 Introduction
Introduction
This is the third part of a three-part article intended to clarify the translation required between the essential view and a relational database designer’s view. Previously, after an introduction explaining the relative roles of the Essential Data Modeler and the System/Database Designer, in the development of a system that can be meaningful for a system/data consumer to use, that article described the first two steps in converting a relatively abstract Essential Data Model into a practical Logical Database Design.
Part One began the effort:
- Step 1 – Perform default database design
- Step 2 – Resolve sub-types
–
Part Two continued the description of that process with:
- Step 3 – Deal with Parameters / Characteristics
Part Three will now address:
- Step 4 – Denormalize, if necessary
Step 4: Denormalize, if Necessary
In the past, elegant data models had to be dramatically restructured in order for the resulting database to be workable on a real computer. Now, however, with the advent of much cheaper disk space and much faster processers, changes made “for performance reasons” are much less often required.
Still, sometimes the processing demands placed on a system call for adjustments to be made.
There are three possible approaches to denormalization:
- Implement derived values as stored columns.
- Split tables horizontally, by instance.
- Split characteristic tables.
NOTE: Any change made to improve performance to do a particular task, it will be at the expense of another task. Any time “de-normalization” is proposed:
- Determine the specific benefit to be achieved.
- Determine the cost in other areas that will result.
- If you do any of this, document the rationale behind the change. (This will be extremely important to your successors some years from now who have to respond to new technological constraints and want to know how to get back to the Essential Model).
Implement Derived Attributes
Continuing from the discussions last month, Figure 1 shows our sample Essential Data Model. Note that some of the attributes are surrounded by curly brackets (“{“, “}”). This is a phenomenon that your author first encountered in the early 1980s in a very well designed database management system/manufacturing package called “Mitrol”. The database had a network architecture (this was before the relational databases had taken off), and it had a feature called the “computed field”.
A computed field was one that, instead of storing a value, had it derived whenever anyone wanted to see it. This enabled the developers to create very sophisticated databases and applications very quickly.
Unfortunately, given the power of the 1980 IBM System 370, whenever a query was requested, the lights dimmed. It was very slow. What quickly became evident was that under some circumstances, it was better to calculate values when data are entered, and only in other cases do you derive them when they are required.
Unfortunately, the next generation of databases (and modeling approaches) lost that idea. Some things did happen over the last 26 years, however:
- Certain essential data modelers (OK, your author) figured out that it is still useful—in presenting a model to the business community—to show how certain things are derived. In the Figure 1 example, Line Item{Value} is defined as Line Item“Price” times Line Item“Quantity”.
- The object-oriented community basically treats all attributes as dynamic—derived when the programs are run.
- The UML notation includes provision for specifying a “derived attribute”—preceding it with a “/” character.
In this particular approach to notation, the curly brackets denote derived attributes (e.g., “{Price}”, “{Contract Value}”, “{Total Sales to Date}”, etc.).
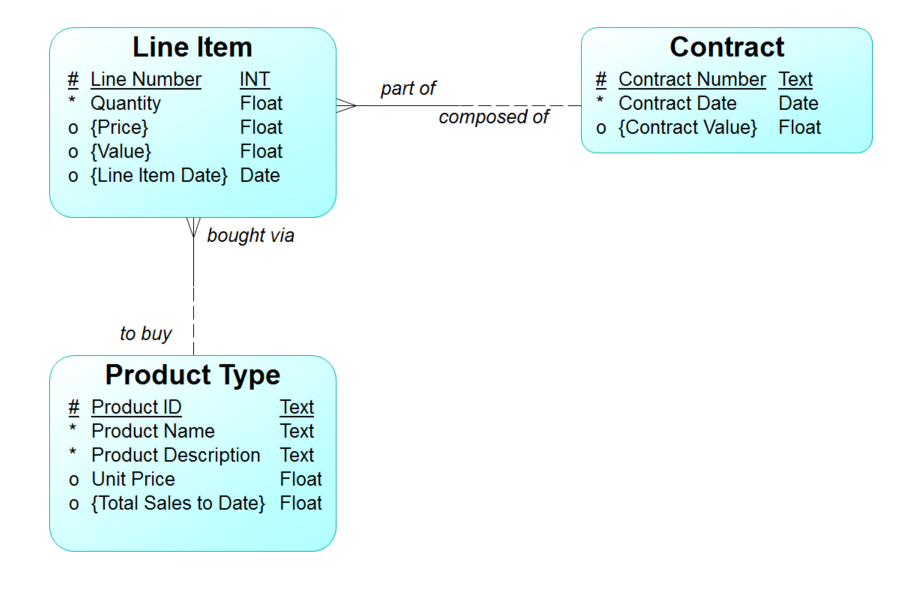
Figure 1: The Entity/Relationship Diagram, Again
Three kinds of derivations are possible:
- Mathematical derivation – One attribute is derived from combining two or more other attributes mathematically. For example: “Line Item {Value} = Line Item Quantity * Line Item {Price}”
- Inference – One attibute in a “child” entity type is inferred from the fact that by definition all attributes in a “parent” entity in fact describe all of its children as well. For example: “Line Item {Price} = INFER-THRU (bought via, Product Type, Unit Price)”
Also, “Line Item {Line Item Date} = INFER-THRU (part of, Contract, Contract Date)
- Summation – An attribute in a “parent” entity type is calculated as the sum of all values of an attribute in an associated “child” entity type. For example: “Contract {Contract Value} = SUM-THRU (composed of, Line Item, {Value})”
Also, “Product Type {Total Sales to Date} = SUM-THRU (to buy, Line Item, {Value})
By showing potential calculations throughout an Essential Model, we are beginning the process of “de-normalizing” it. That is, its third normal form Product Type “Unit Price” is appropriately shown as an attribute of Product Type.
It may, however, be appropriate to have that “Unit Price” made more directly available to the Line Item entity and storing a copy of it in that entity type as well. Having it “looked up” across a relational join every time it is required will cause a serious hit on “performance.”
So the question is: do we have the value derived (via a join) every time it is required, or do we store it as soon as it is available? If this denormalized value is stored, retrieval will be much faster, but there will be a cost in requiring it to be updated every time the source value is updated. If it is computed on demand, there is no ongoing maintence required—but the retrieval time could be excessive.
In deciding how to implement the derived attributes, the fundamental question is, how much traffic is going to be associated with both changing or retrieving each value?
Here are some specific criteria:
Compute on input:
- If values are relatively stable, and/or
- If retrieval volume per day is considerably greater than update volume.
NOTE: This provides much faster retrieval times, but maintenance will be required to keep the values current.
Compute on query:
- If values are relatively dynamic, and/or
- If retrieval volume is relatively low.
In this case, queries may be slower, but additional maintenance will not be necessary.
For example, it is reasonable to expect that when a Contract is created, the Product Type Unit Price will have been established. Thus, it is reasonable to apply it (or adjust it, for that matter) to create the line item {Price}, when it is created. Similarly, “Quantity” and the resulting {Value} are not going to change.
On the other hand, it is reasonable to expect that line items may be added over time. Thus it is also reasonable—at least—to wait until the contract is complete to establish the total Contract {Contract Value}. You could still compute and store this value, but only after all Line Items have been specified.
Even more problematic is the attribute Product Type {Total Sales to Date}. This clearly will change over time, across the creation of many Contracts, with different values each time it is requested. In fact, the derivation is more complex than our example shown here, since it has to sum only the line items whose {Line Item Date} is the current year.
In dealing with computed attributes, we have already taken the first steps toward de-normalization. Instead of expecting queries to make use of multiple “join” statements, we’ve already defined how various attributes (columns) will link to each other. The first was “INFER-THRU”, which anticipated the fact that the value of a parent attribute may be useful in each of its child tables. In the implementation step, one step to demormalization will be simply specifying that that “look-up” will happen when data are stored.
Similarly, it may be reasonable to compute totals (such as Contract “Total Value}”), using “SUM-THRU”. In this case, however, it is more likely that these values will change over time, so you won’t want to compute them in advance.
Figure 2 shows an Essential Data Model that combines the pieces of Essential Models we saw last month, with the attributes we’ve seen before, plus two new ones:
- (Contract) Buyer Name = INFER-THRU (from, Party, “Name”)
- (Contract) Seller Name = INFER-THRU (to, Party, “Name”)
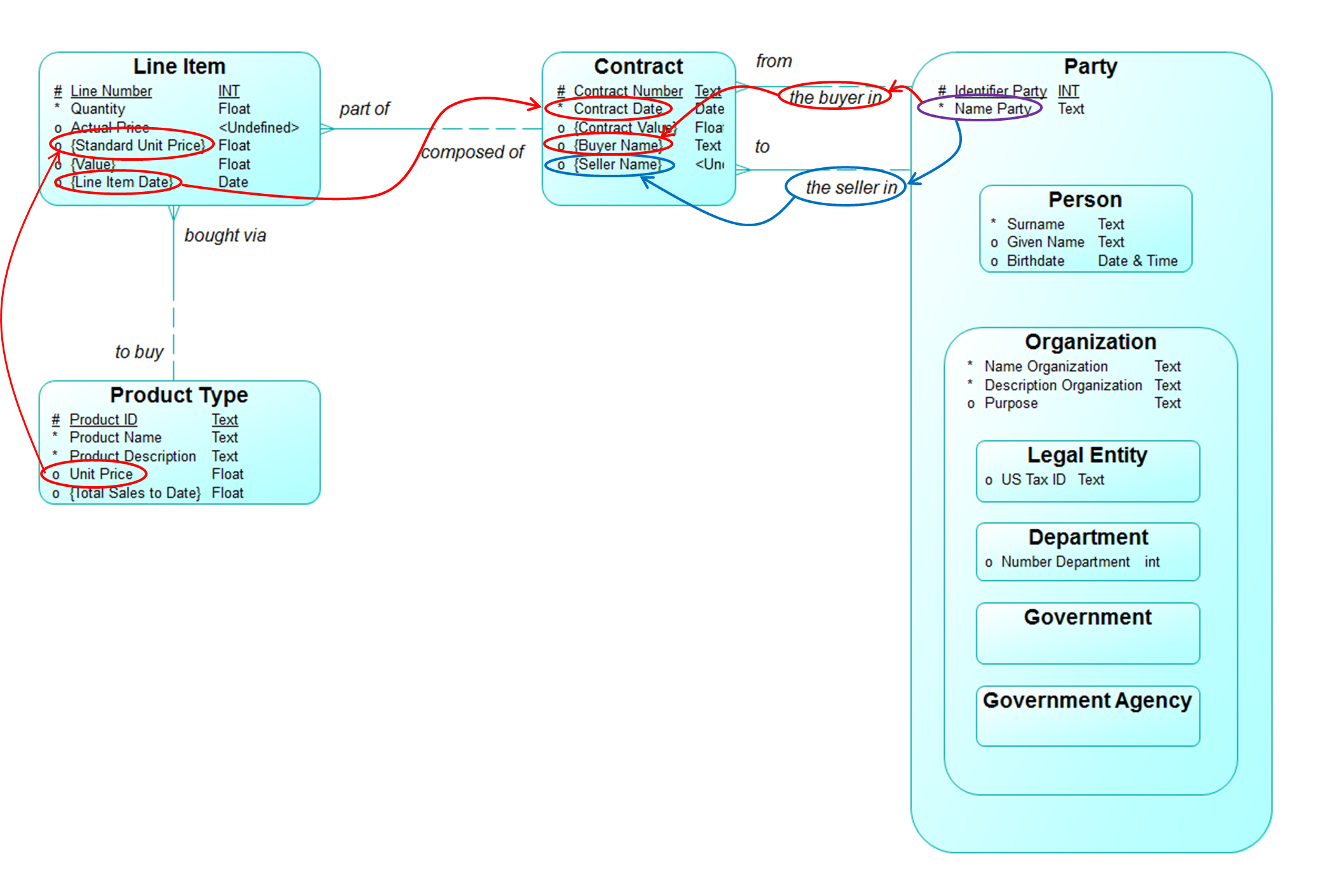
Figure 2: Implement Derived Values
Figure 3 shows the table design resulting from taking this approach. Contract now has the columns:
- [Contract Value]
- [Buyer Name]
- [Seller Name]
Line Item now has the columns:
- [Contract Number]
- [Product Name]
- Quantity
- Actual Price
- [Standard Unit Price]
- [Value]
In this case, the {} notation has been replaced by “[ ]” to show which computed columns will be stored in defined columns when the row is created.
Each of those in Line Item are appropriate as stored values, since it is expected a Line Item will be created all at once. Note, by the way, that the “Price” logic implied by this example is different from that in the earlier example. Apparently, the “Actual Price” may be something different from the inferred {Standard Unit Price}. This makes it clear that this Price is to be stored, although the [Standard Unit Price] may also be stored for future reference. [Value], then, can be calculated when the Line Item is created as well.
At the very least, all the Line Item instances for a single Contract would be created before “[Contract Value] *” is created. Even so, once the process is complete, it can be assumed that (most of the time) there will not be changes. For the reason, it is not unreasonable to store the [Contract Value] for the Contract—again, once it is completed.
Note however, that if an Line Item “Actual Price” is changed, the entire Contract will have to be reprocessed. Both Line Item [Value] and Contract [Contract Value] will have to be recalculated and new values stored. Similarly, if a new Line Item is added to the same Contract, Contract [Contract Value] will have to be recalculated and new values stored.
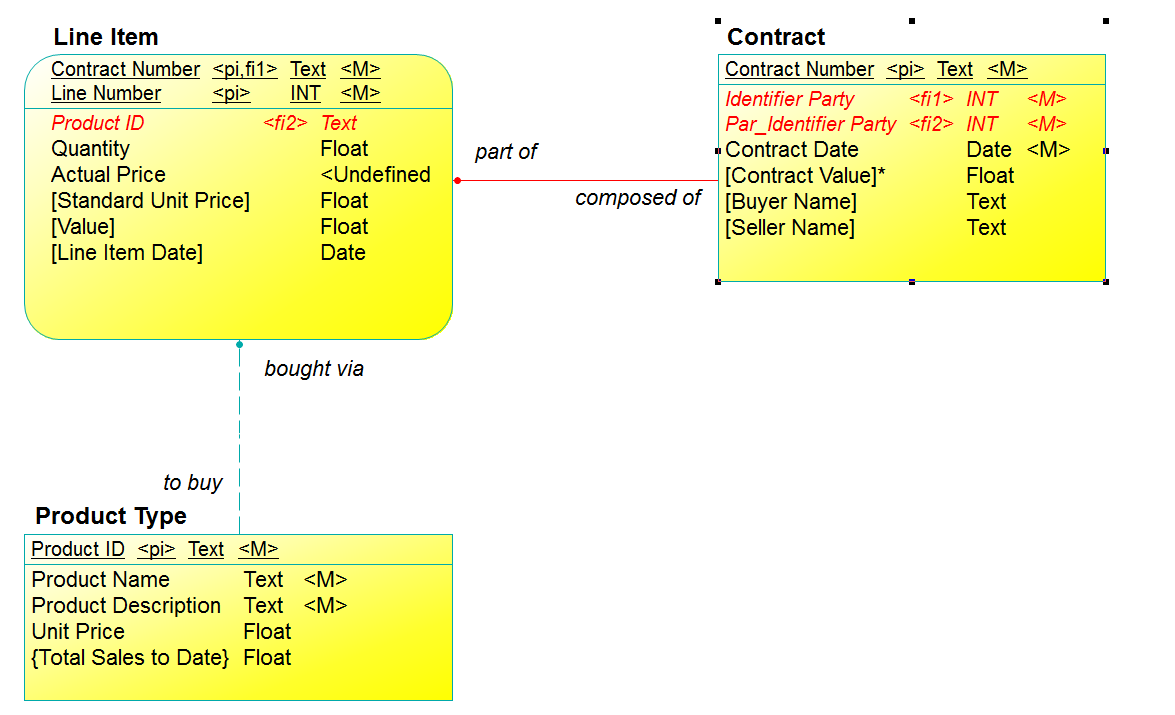
Figure 3: Reference Tables
To summarize, storing denormalized values significantly speeds up queries—but it also incurs significant expense for ongoing maintenance.
It is not recommended that Product Type {Total Sales to Date} be defined permanently as an attribute for Product Type. Contracts and Line Items will be added (and subtracted?) over time, so this value is only true at the moment someone asks.
In fact, the compilation of Sales over time should probably entail some extensions to the Essential Model, requiring some more complex database design as well.
Understand, of course, that, while the logic of deriving each of these columns should be documented as part of the Essential Model, the programming required to carry them out is part of the implementation.
NOTE:
- The paradigm of “INFER-THRU” and “SUM-THRU” in the calculated attributes anticipated all of this.
- If these had been implemented as dynamic columns, their maintenance would have been automatic.
- By implementing them as static copies, maintenance must be added.
Split Horizontally (Instances)
One way to reduce the load on any particular database instance is to divide the body of data. In one case, different instances of each table wind up in different databases, perhaps even in different computes. For example:
- By Geographic Area
- Some tables for North American customers
- Some tables for European customers
- cetera
- By Customer Type, etc.
- One set of tables for corporate customers
- One set of tables for individual customers
- Et cetera
Recognize that decisions along this line are predicated on a deep understanding of who, exactly, will be wanting to see each kind of data. If demands are local, this works. If corporate headquarters will be examining data from the entire population, it might be better to store the data all in one place.
Especially when dividing by any sort of attribute value (i.e., “Customer Type”) care must be taken to clarify just what the categories mean. Part Two of this essay covers categorization.
Split Vertically (Columns)
To the extent that the design hard codes many characteristics as attributes, one approach to de-normalization is to split those attributes across different tables.
For example:
- Person, with “Customer” attributes
- Annual sales
- Sales representative
- Cetera
- Person, with “Employee” attributes
- Social Security number
- Employment date
- Cetera
Note that people with both kinds of attributes would appear redundantly in both tables.
This retains the problems of hard coded attributes described in Part Two of this essay. The cautions described there still apply.
On the other hand, that the design provides for most of the characteristics to be in …Characteristic tables, there are economies that can be realized by splitting these up into more specialized tables. There are two ways to do that:
By sub-type:
- Person Characteristics, Legal Value Characteristics, Government Characteristics, etc.
This works provided few characteristics apply to more than one sub-type.
- Geopolitical Area Characteristic, Management Area Characteristic, Other Surveyed Area Characteristic, etc.
By Category Schema:
- “Standard Industrial Category (SIC), “Color”, “Automobile Manufacturer”, etc.
A separate table could be constructed for each …Category Scheme, or collection of such …Category Schemes.
Summary – Converting an Essential Model to a Real Database Design
The three TDAN.com articles under this title address the problem of taking a relatively abstract “Essential Data Model”, and converting it to a practical database design. There are, of course, many more details to that process than can be covered in these brief pages, but the basic organization of the steps should be clear:
Step One: Begin by using the CASE tool that holds the model to make a “first cut” “Logical” and/or “Physical” relational database model. The particulars of doing this vary by CASE Tool. The SAP Power Designer, for example, keeps the sub-type structures, even in the Logical Model, and doesn’t eleminate them until its version of the Physical Model.
Note that it is always a designer’s job to trade off conflicting requirements to arrive at the best practical solution.
Step Two: Resolve the “inheritance” implicit in super-type/sub-type structures.
Relational databases, by definition, consist of “flat” two dimensional tables, with no direct way to represent hierarchies. There are several ways to address this, and each has both positive and negative implications. It is always a designer’s job to trade off comflicting requirements to arrive at the best practical solution.
Note that it is always a designer’s job to trade off conflicting requirements to arrive at the best practical solution.
Step Three: Deal with Characteristics / Parameters.
The Essential Model will have addressed the proliferation of attributes in the Semantic Model by defining entity types to capture them as “Characteristcs”, “Parameters”, or some such. This provides the most flexibility possible for managing them. In moving to a physical design, however, some of them should be implemented as actual columns in a topical table. For example, the table of Party Characteristics should be evaluated to determine which of those should be hard-coded attributes of Party.
Note that it is always a designer’s job to trade off conflicting requirements to arrive at the best practical solution.
Step Four: De-normalize if necessary.
To the extent that an Essential Model represents “derived attributes,” the process of de-normalization has already been anticipated. The first part of de-normalization is to determine which of the derived attributes should be represented by a column in a table with values derived when the table is created or updated, or by a piece of program code that derives a value whenever it is requested. There are different kinds of costs associated with each approach.
In addition, the designer has the discretion of deciding how to divide up tables so that their storage is most appropriate for the user populations involved.
Note that it is always a designer’s job to trade off conflicting requirements to arrive at the best practical solution.
* Note that this is not computed for each Line Item, but must wait until the Contract is complete.
