
I. Introduction
Information Systems (IS) play an important role in business because they implement the business process. However, designing, refining and maintaining an IS requires some technical or programming skills that stakeholders do not have in general. Thus they currently rely on technical experts (IT) to model their business requirements expressed as a set of business rules (BR). However, transferring the business semantics from business people to IT people can introduce inconsistencies. The expression of requirements in any human language is unavoidably ambiguous and most of the time incomplete. Thus, this paper aims at bridging the gap between business and IT people in order to minimize the loss of semantics and overcome the huge software failures due to miscommunication. Its contribution is to provide a complete framework which takes as input the BR written in natural language (NL) (such as English or French) and provides a set of linguistic analyses and automated transformations into executable models for IT people. Our idea is motivated by the birth of the Semantics of Business Vocabulary and Business Rules (SBVR) standard [1] which is a Semantic Metamodel (SMM) [2], [3] for specifying semantic models of business using NL. Based on a fusion of linguistics, logic, and computer science, SBVR provides a way to capture specifications in NL and represent them in formal logic so they can be machine-processed [1]. The presented methodology follows a pipeline architecture defined in two steps: Firstly, the NL BR is linguistically analyzed using the Micro-Systemic Linguistic Analysis (MSLA) methodology [4] and automatically transformed to SBVR BR to overcome the syntactic inconsistencies and semantic ambiguities involved in the NL representation. The resulting SBVR BR is mapped to SBVR models through semantic formulations. Since SBVR is the NL starting point for the Model Driven Architecture [5] (MDA) process, the MDA model transformations are used to transform SBVR models towards executable models. One motivation of this framework is to provide support for the Data Excellence Management System (DEMS) platform driven by the Data Excellence Framework (DEF) [6].
The remaining paper is structured into the following sections: Section II briefly introduces the underpinning technologies used in our approach. The reader is introduced to the basic principles behind the DEF, SBVR, MDA and model transformations. Section III describes the whole process of the methodology along with a running example. Section IV presents some related work. The paper ends in Section V with conclusions and future work.
II. Context of the Methodology
A. Data Excellence Framework (DEF)
The DEF describes the methodology, processes and roles required to generate business value while improving business processes using data quality and BR [6]. DEF is supported by the DEMS platform shown in Fig.1. However, the complexity of the description of the BR due to ambiguities of NL can induce a deviation in the operationalization of the DEF. In the current context, the BR is manually read, disambiguated and converted to DEMS Agent BR format for further operations. The set of BR supporting data quality grows over time and the amount of manual processing becomes huge and time consuming. Thus, our framework supports the DEF with a fully automated process of transforming NL BR to SBVR BR in DEMS (NLP Framework), and afterwards, SBVR BR to Executable BR in DEMS Agent (SBVRtoEXE Framework).
B. Semantics of Business Vocabulary and Business Rules (SBVR)
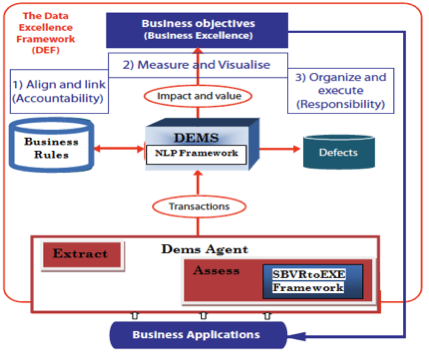
Figure 1. DEMS platform
In the business context, the Object Management Group (OMG) has recently published a new standard called SBVR, which defines a metamodel for developing semantic models of business vocabularies and business rules [1]. SBVR is designed to be used for business purposes by business people, independently of IS design. Its first aim is to allow business vocabularies construction and business rules definitions, enabling their interchange among organizations. The SBVR metamodel is very sophisticated [7], but clearly shows the approach that separates logical formulations from meanings.
- SBVR meanings: there are two key constituents of meaning in SBVR [1]:
- Business vocabulary: a cohesive set of interconnected concepts (concepts and fact types), which organizations or communities use while talking or writing in the course of doing business.
- Business rules: define the structure of business and provide elements of guidance on the actions. The SBVR rules can be of two types:
- Definitional rules or structural rules are used to define an organization’s setup, e.g. It is necessary that each customer has at least one bank account.
- Behavioral rules or operative rules express the conduct of an entity, e.g. It is obligatory that each customer can withdraw at most € 300 per day.
- SBVR semantic formulations: the SBVR specification document [1] has defined a set of logical formulations (LF) to formulate semantically the NL BR in a structured and consistent manner. LF is an abstract and language independent syntax to represent the meaning of a rule in a set of logic structures so that it can be machine processed. Following are the details about how LF is used to map NL BR into the SBVR metamodel [1]:
- Atomic formulation: specifies a fact type in a rule, e.g. “customer has bank account”
- Instantiation formulation: denotes an instance of a class, e.g. “Silver account” is an Instantiation of the noun concept “bank account”
- Logical operations: conjunction, disjunction, implication, negation, etc.
- Quantifications: state the enumeration of a noun concept or verb concept, e.g. “at least one”, “at most one”, “exactly one”, etc. are used to quantify concepts.
- Modal operators: identify the meanings of a logical formulation, e.g. “It is obligatory” or “It is necessary” are used to formulate modality.
- SBVR Structured English (SSE): SSE is the concrete syntax documented in SBVR Annex C based on controlled English to textually map SBVR concepts and rules. SBVR specification is itself described using SSE [1]. It should be noted that SBVR is not itself a controlled natural language (CNL) so it is up to each SBVR-implementing language or notation to specify its formal mechanisms [8]. SSE defines four formatting styles, as follows:
- Terms: underlined green text applied to noun concepts (currency, bank)
- Names: double underlined green text applied to individual concepts (Euro).
- Verbs: blue italic text for identifying fact types, which define relationships between concepts. e.g. ‘bank uses currency.
- Keywords: orange text used for other linguistic symbols and built-in SBVR concepts used to construct vocabulary definitions and rule statements (it is obligatory that, exactly one, each, some, etc.)
C. Model Driven Architecture (MDA) and Model Transformations
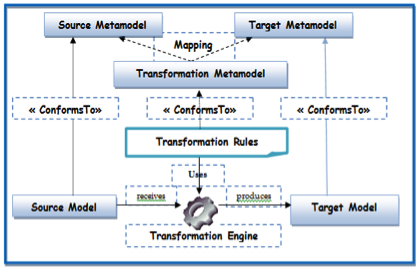
Figure 2. Transformation based modeling
MDA is an OMG standard [5] constituting the core standard of Model Driven Development (MDD). It defines an approach that separates business and application logic from underlying platform technology (e.g. CORBA, J2EE, .NET). No longer tied to each other, the business and technical aspects of an application can each evolve at their own pace, business logic responding to business needs and technologies taking advantage of new developments. MDA is focused on two artifacts: models and model transformations. Its key principle is to elaborate models at any stage of the application development process and to move from one stage to another by model transformations as in [9]. Model transformation is the main key constituent of the MDA approach. A transformation is the automatic generation of a target model from a source model, according to a transformation definition. A transformation definition is a set of transformation rules that together describe how a model in the source language can be transformed into a model in the target language. A transformation rule is a description of how one or more constructs in the source language can be transformed into one or more constructs in the target language [10]. There are currently three approaches to model transformations: transformation based programming, design patterns, and modeling. Our methodology uses transformation based modeling presented in Fig. 2 which is strongly recommended by the MDA approach and is defined in three steps: transformation rule definitions, expression of transformation rules, and the execution of transformation rules by the transformation engine. This takes as input the source model, applies the transformation rules, and produces the target model. The relation between a model and its metamodel is called “ConformsTo”.
III. Process of Transforming NL BR to Executable Models
The process of transforming BR specifications from NL to executable models requires two main steps as highlighted in Fig. 3. First of all, we need to transform NL BR into SBVR rules using the Natural Language Processing (NLP) Framework. Afterwards, the resulting SBVR Rules are mapped into Executable models using the SBVRtoEXE Framework. An example will be used throughout this section to illustrate the approach. The considered BR is: A student must validate at least five courses.
A. NL to SBVR Transformation
This section defines our NLP Framework, which is responsible for a number of linguistic processes from NL BR. This module is the core of the methodology because it faces NL ambiguities. It performs a lexical, syntactic, and semantic analysis in order to identify SBVR concepts from complex NL BR. Micro-Systemic Linguistic Analysis (MSLA) is used and consists of analyzing a linguistic system in component systems as follows [4]: Sc: a system which is recognizably canonical; Sv: another system representing the variants and Ss: a ‘super’ system which puts the two systems Sc and Sv in relation with each other. In this context, Ss represents the systemic translation system, Sv the NL, and Sc the SBVR metamodel. Applications of MSLA are very varied [11]. It has been applied to many concrete applications such as controlled languages and machine translation in safety critical applications [12] and text normalization [13]. MSLA lends itself to mathematical modeling; it has certain inherent features that satisfy notions pertinent to software engineering, and furthermore, its mathematical underpinnings provide the meta-descriptions needed for the software development process [14].
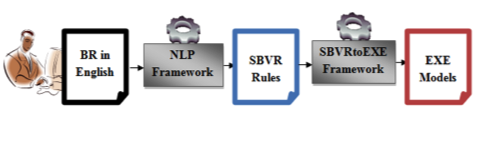
Figure 3. General architecture of the methodology
Given an English BR defined by a user, the following steps are performed:
- Segmentation: The text is split into sentences and words (tokens), e.g. A | student| must| validate| at| least| five| courses.
- Lexical processing: Part of Speech (POS) tagging is performed to identify the basic POS of tokens, e.g. A/DET | student/NN | must/VB | validate/VB | at/IN | least/JJS | five/CD | courses/NNS. Afterwards, morphological analysis is performed on verbs and nouns. e.g. “courses” is analyzed as “course + s”
- Syntactic analysis: The text is syntactically parsed in order to generate the parse tree for further semantic analysis.
- Semantic analysis: Role labeling [15] is firstly performed. The desired role labels are actors (nouns used in subject part), co-actor (additional actors conjuncted with ‘and’), action (action verb), thematic object (nouns used in object part), and beneficiary (nouns used in adverb part), if it exists. E.g. A student {actor} must validate {action verb} at least five {quantity} courses {thematic object}. Subsequently, the SMM [2], [16] is used to enable the construction of meta bases which allow on one hand the classifying of concepts appearing in the BR, and on the other hand the creation of links that can occur between the concepts. This classification assists in identifying SBVR vocabulary. The theoretical basis for SMM is that of the semantic modeling of queries. Any query of a data source, independent of the language in which the query is expressed (natural or formal), is considered as following certain semantic rules that are essential understanding [3].
- Concepts extraction: In this stage, Basic SBVR elements (Noun concept, individual concept, object type, verb concepts, etc.) are identified. For this purpose, we used a concept classification similar to the keyword classification proposed in the SMM [2], [3]. This concept classification distinguishes between generic concepts and specific concepts. Generic concepts are business independent but have roles in the formulation of a semantic description of a given BR. Specific concepts are domain specific and their extraction is based on the business glossary provided to ensure that generated SBVR BR will be semantically related to the target business domain. The SBVR concepts extracted in our example are: A {quantification} student {noun concept} must {modal verb} validate {verb concept} at least five {quantification} courses {object type}.
- SBVR Rules Generation: Once the different SBVR concepts are identified from the NL BR, SBVR rules are generated from the output of the NLP Framework. The SBVR rule is firstly generated in SSE and parsed afterwards to the SBVR model, which conforms to the SBVR metamodel by applying a set of logical formulations (Fig. 4). For instance, modal verbs “can” or “could” are mapped to possibility formulation (It is possible that…) and “should”, “must” or verb concept “have to” are mapped to obligation formulation (It is obligatory that…). In this generation process, the core element of a BR is a rule, which is expressed by modal verbs or “if…then…” structures. This helps us to identify sentences representing a SBVR BR in a complex NL BR description.
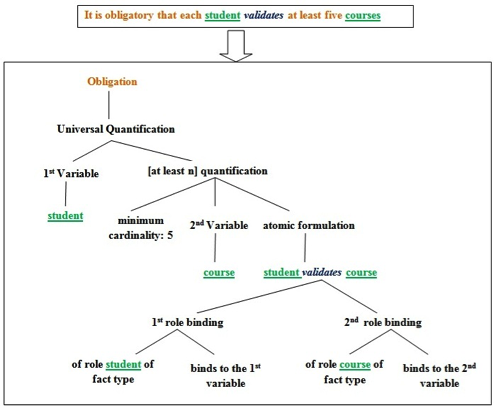
Figure 4. Mapping of SSE rule to LF structure
B. SBVR Rules to Executable Models Transformation
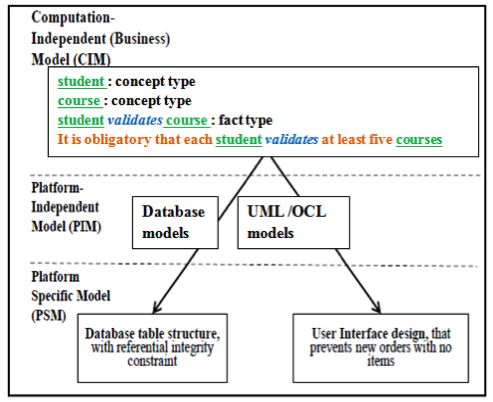
Figure 5. SBVR to executable models process
In reality, SBVR describes BR without addressing their implementation, e.g. an obligation rule specifies what a business must do, possibly under some conditions, without saying how the business should do it. This stage of our methodology allows ensuring that the SBVR BR conforms to SBVR metamodel in order to map to an executable model (PIM level) for further code generation (PSM layer). An MDA model transformation described in section II is applied. An advantage is that one rule can map to multiple implementation artifacts [17], as shown in Fig. 5.; e.g. our SSE rule “It is obligatory that each student validates at least five courses” implies a database table structure with a foreign-key reference among student and courses, and the application that supports the constraint at least five courses per student.
C. Case Study and Tool Support
The example of BR “A student must validate at least five courses.” has been used throughout the paper to illustrate the methodology. Although it seems relatively simple, it embeds important concepts both from the language and modeling viewpoint. However, the framework also supports some complex description of BR written even in several sentences as well. In this case, we first proceed to the identification of sentences representing a SBVR BR by using modal and logical keywords. Afterwards, each rule sentence can be analyzed in the same way as the above example.
Our framework is implemented using the Eclipse platform extended with certain plug-ins: Eclipse Modeling Framework (EMF), Atlas Transformation Language (ATL) [18]. XML Metadata Interchange (XMI) is used for the serialization of metamodels. We have used the SBVR XML Schema proposed in [19] and our transformations rules are written using ATL.
As a proof of concept, we have experimented using the prototype to generate an executable SQL script according to the process described in the Fig. 5 in order to verify whether or not a given state of relational database conforms to the constraint that SBVR BR imposes. Fig. 6 shows the skeleton of the script generated from the LF of the running example shown in the Fig. 4.

Figure 6. SQL script generated from the running example
IV. Related Work
The idea of generating executable models from NL specifications is not new [20]. In the last two decades, much work has been presented to address NLP problems in object-oriented analysis in order to automatically generate object models from NL texts [21]. However, most of them provide results with less accuracy because of the ambiguous and non‑formal nature of NL. Hence, some researchers adopt the use of controlled natural language (CNL), which is a subset of a NL with restricted grammar and vocabulary [22]. CNLs are useful in reliable automatic semantic analysis of the language [8] because a particular challenge for NLP is the translation of NL to formal semantics [2]. More recently, SBVR has been presented as a metamodel for the semantic formalization of NL and SSE the CNL mapping to SBVR structures of meaning. However, the writing of SBVR rules in SSE representation is itself an overhead [23]. Moreover, many business domains already have their BR written in NL and the manual translation of NL rule to SBVR rule is not only difficult, complex, and time consuming, but also can result in erroneous BR. The contribution of this paper has been to propose a framework that can fully automate the process of transformation of NL BR to SBVR rules and to executable models.
V. Conclusions and Future Work
Applications of NLP in the field of software and business modeling are significant, especially in improving accuracy, productivity, flexibility, multilingualism and robustness [24]. We have presented a methodology to facilitate the transformation of BR specified in NL into executable models. This methodology uses the SBVR standard front-ended by MSLA to bridge the gap from NL to executable models. As soon as the user inputs the NL BR, the framework linguistically processes the input NL BR to extract SBVR vocabulary and generate a SBVR representation in the form of SBVR rules. Then, SBVR rules are semantically analyzed to generate executable models. We believe our paper can also be a first step towards the development of efficient automated systems from NL specifications, and finally bridge the gap between business and IT. Our current and future work is to improve the prototype in order to deal with more complex rules.
Acknowledgment
Sincere thanks to Professor Sylviane Cardey and Dr. Peter Greenfield for their guidance and unconditional support during the writing of this paper as well as their entire availability for reading and corrections.
Written with Paul Brillant Feuto Njonko.
References
[1] OMG, Semantics of business vocabulary and business rules (SBVR), OMG Standard, v. 1.0, January 2008.
[2] El Abed, “Méta modèle sémantique et noyau informatique pour l’interrogation multilingue des bases de données en langue naturelle (théorie et application),” thèse, Université de Franche-Comté, Besançon, France, décembre 2000.
[3] Cardey, W. El Abed and P. Greenfield, “ Exploiting semantic methods for information filtering,” In Actes du 3ème Colloque du Chapitre français de l’ISKO (International Society for Knowledge Organization), Université de Paris X : “Filtrage et résumé automatique de l’information sur les réseaux”, 2001, pp. 219-225.
[4] Cardey and P. Greenfield, “A core model of systemic linguistic analysis,” In Proceedings of the International Conference RANLP-2005 Recent Advances in Natural Language Processing, Borovets, Bulgaria, 21-23 September 2005, pp. 134-138.
[5] OMG, Model driven architecture (MDA) guide, OMG Standard, v. 1.0.1, June 2003.
[6] El Abed, “Data governance: a business value-driven approach,” a White Paper, USA, November 2009.
[7] Mathias, A. Patrick, and J. Bezivin, “Parsing SBVR-based controlled languages,” In 12th Models’09, LNCS Vol. 5795, Springer-Verlag Berlin, Heidelberg, 2009, pp. 122-136.
[8] Anderson and S. Spreeuwenberg,“SBVR’s approach to controlled natural language,” In proceedings of the Workshop on Controlled Natural Language (CNL, 2009), Italy, 8–10 June, pp. 155–169.
[9] E. Kouamou and P. B. Feuto Njonko, “Cohérence de vues dans la spécification des architectures logicielles ,” In proceeding of 10th African Conference on Research in Computer Science and Applied Mathematics (CARI’2010), Yamoussoukro, Ivory Coast, October 18–21, 2010.
[10] Kleppe, J. Warmer, and W. Bast, “MDA explained: the model driven architecture: practice and promise,” Addison-Wesley, 1st édition, August 2003.
[11] Cardey and P. Greenfield, “Systemic linguistics with applications,” In Linguistics in the Twenty First Century, Eds. E.M.Bermúdes and L.R. Miyares, Cambridge Scholars Press, United Kingdom, ISBN 1904303862, 2006, pp. 261-271.
[12] Cardey, “Machine translation of controlled languages for more reliable human communication in safety critical applications,” In Proceedings of the 12th International Symposium on Social Communication – Comunicación Social en el Siglo XXI, Santiago de Cuba, Cuba, January 17-21, 2011, Vol. II, pp. 953-958.
[13] B. Feuto Njonko, “Rule based approach for normalizing messages in the security domain”, to appear in Natural Language Processing and Human Language Technology 2011, BULAG n°36, PUFC, ISSN 0758 6787.
[14] Cardey and P. Greenfield, “Micro-systemic linguistic analysis and software engineering: a synthesis,” In revue RML6, 2008, Actes du Colloque International en Traductologie et TAL, 7 et 8 juin 2008, Editions Dar El Gharb, Oran, ISBN: 978 9961 54 593 1, pp. 5-25.
[15] S. Bajwa, M. G. Lee, and B. Bordbar, “SBVR business rules generation from natural language specification,” In AAAI 2011 Spring Symposium -Artificial Intelligence for Business Agility (AI4BA). San Francisco, USA. March 2011, pp. 2-8.
[16] El Abed, G. Jin, S. Cardey and S. Durbec, “La gouvernance des données dans un contexte de sécurité globale,” Worshop interdisciplinaire sur la securité globale, Troyes, 2011.
[17] Linehan, “SBVR use cases,” In international Symposium on Rule Representation, Interchange and Reasoning on the Web, RuleML, LNCS Vol. 5321, Springer-Verlag Berlin, Heidelberg, 2008, pp. 182-196.
[18] Jouault and I. Kurtev, “Transforming Models with ATL,” In: Bruel, J.-M. (ed.) MoDELS 2005. LNCS, vol. 3844, Springer Heidelberg 2006, pp. 128-138.
[19] Cabot, P. Raquel, and R. Ruth, “From UML/OCL to SBVR specifications: a challenging transformation,” In Information’s Systems Journal. 2010, pp. 417-440.
[20] R. Bryant et al., “From natural language requirements to executable models of software components,” In Workshop on S. E. for Embedded Systems, 2008, pp.51-58.
[21] S. Bajwa, M. Asif, A. Ali and A. Shahzad, “A controlled natural language interface to class models,” In proceedings of the 13th International Conference on Enterprise Information Systems (ICEIS 2011), pp: 102-110.
[22] Hart, M. Johnson, and C. Dolbear, “Rabbit: developing a control natural language for authoring ontologies,” 5th European Semantic Web Conference (ESWC’08), 2008, pp. 348-360.
[23] S. Bajwa, B. Bordbar, and M. G. Lee, “OCL constraints generation from natural language specification,” In 14th IEEE International Enterprise Distributed Object Conference (EDOC 2010). Vitoria, Brazil. October 2010. pp. 204-213.
[24] Leidner, “Current issues in software engineering for natural language processing,” HLT-NAACL 2003 Workshop on Software Engineering and Architecture of Language Technology Systems – Vol. 8, Morristown 2003, NJ, pp.45-50.
