Overview
What is a Semantic Model?
The use of a semantic model as a fundamental step in the data warehouse development process can serve as a keystone for understanding requirements, the design of the subsequent data models, and as
a link between the reporting tool interface and the physical data models.
Although not as famous as its logical or physical data model cousins, the semantic model deserves generally greater consideration because of its unyielding focus on the user perspective. When built
correctly, the semantic model is the user’s perspective of the data-and what could be more important?
In a general sense, semantics is the study of meanings-of the message behind the words. “Semantic” in the context of data and data warehouses means “from the user’s perspective.” It is the
data in context-where the meaning is. “Information” is also often defined as “data in context.” “Semantic” therefore, while not synonymous with information, carries with it the same sense of
data at work, or data in the worker’s hands.
Why is a Semantic Model Needed?
Semantic data elements are deceptively similar to the entities and attributes we find in a logical or physical data model. They are things like “customer,” “product,” “credit limit,” “net
sales,” and so forth. What the semantic modeler must address however, is the context of the term-the data element- and how it relates to the data elements as present in the computing systems data
stores. For example, is a customer an individual-the Purchasing Agent- or a company? Must a customer have actually purchased a product, or can a customer also be someone who is in the market for a
(the) product? What in some contexts might be called a “prospect” might be called a “customer” in others. Is a customer a wholesaler or is the end consumer the customer? Is the wholesaler’s
customer also called a customer?
The answer to these questions is likely to be “it depends.” And that is the correct answer, because it does depend. It depends on who is asking and why. ABC company’s sales department may draw a
clear line between customers (buyers) and prospects. ABC’s marketing department may simply use “customer” to refer to those participating in the market, whether or not they’ve actually bought
ABC’s product.
The semantic modeler must drill down and capture the nuance of each perspective and must struggle to work with the business users to develop a naming convention or syntax that provides clarity. All
perspectives are represented in the semantic model.
Imagine the confusion if ABC’s Sales Department and ABC’s Marketing Department both ask the IT department for a list of all customers that attended the Big Trade Show. Will they both get the same
list? Which list will it be?
Something as deceptively simple as “Employee” can also be the cause of confusion. Suppose IT receives a request to answer the question: How many Employees work in this building? IT runs a query
against it’s Employee database, selecting only those names where the work location is this building and provides and answer: 250. When 250 new telephones arrive three weeks later, there are 100
workers without new phones. What happened? In addition to 250 Employees, there are also 100 contract workers in the building, and they all have desks and phones. Well then, what exactly is an
Employee? It depends on the semantics-on the context.
It is exactly this confusion that the semantic model strives to both reveal and resolve. Is “Net Sales” net of invoice line-item costs or also net of rebates? For Financial Reporting, it may just
be net of invoice line-item costs; for Sales Representative. Commissions, it may be net of rebates as well. (I know of a global company so committed to semantic clarity that an operations manager
was sent around the country, making presentation after presentation to Sales Representatives, just to explain the difference between “net sales” and “commission sales.”)
It is often said that one of the purposes for building a Data Warehouses is to have “one version of the Truth (capital T).” While this does have a nice ring to it, in actuality a successful data
warehouse project will expose many legitimate versions of the truth (lower case t), and will align the business and data semantics so that each truth is understood in its individual context and in
its relation to other contexts.
Creating the Semantic Model
Document the Business Metrics
For the chosen subject area, review the existing IT generated reports, screens and spreadsheets and the less formal, (but often more relied upon) departmental or individual reports and
spreadsheets. (As is good practice for any systems development project, it’s best not to extend the scope too far. It’s always better to succeed at something small and build in increments than to
fail at something large.)
Create a list of the report row and column names, selection and sort criteria elements. These are the semantic elements for the chosen subject area.
Discuss the list of elements with the business users and document their definitions. Document comments about the usefulness or quality of the elements. Pay special attention to element names that
appear frequently, perhaps even across departments-anything that appears to be a good candidates for semantic confusion.
Group the elements in a rough hierarchy in some type of outline format. For example, Customer Name, Customer Address, Customer Credit Limit, Customer Type, etc. should be grouped together under
Customer.
This model can be documented in Excel or Access-or in any number of more sophisticated metadata repositories or modeling tools to conform to corporate standards.
Trace the Elements to their Atomic Sources
For all listed data elements, trace them back to their source system(s) and document what transformations they went through before they were printed on the report, displayed on the screen, or
written to the extract file. This is where the hidden semantic differences are revealed. Two reports, maybe for two different departments displaying Net Sales, are found to use slightly different
calculations-and of course the numbers don’t match-how could they? It’s found that data on two different reports, while generally identical, is sometimes different. The tracing exercise may
reveal that one report is sourced from an unadjusted file and the other report is sourced from the same file, but only after twice-yearly adjustments are made. The point is to trace and document
all traces. The resulting document should look like a target-to-source map. A simplified sample of such a map might be:

Resolve the Semantic Issues with the Business Users
Review the completed element list with definitions and traced mappings with the business users and validate that the document is a complete and correct semantic representation. Further, and more
importantly, for those elements that have some semantic confusion, clear it up. Facilitate joint sessions with the business users and IT to develop and come to consensus on new terms as needed-e.g.
“commission” sales. On the other hand, it may be more appropriate to redefine one or more transformation formulas to conform dissimilar elements.
In the sample above, for example, further work is required to understand the similarities and differences between the Sales Force Automation system’s MSCL costs and the MATL, LBR, and FRT costs
applied by the Invoicing system.
The goal is to resolve all the semantic differences before designing the data structures for the data warehouse.
Delivering the Data
The Semantic Layer
A key deliverable of virtually every data warehouse project is providing users with hands-on access to the data. That kind of access has in fact, become synonymous with the concept of data
warehousing. The access is typically provided through one of two approaches, via one of two kinds of reporting tools:
1. Query and reporting tools
They can also produce graphs and charts.
combination of direct links to the atomic database elements (e.g. Customer Name) and derived or calculated elements (e.g. Customer Gross Profit %). The data is typically presented as elements
within folders. The semantic layer insulates the users from the complexity of SQL and the distinctions as to which of the elements in the semantic layer are atomic and which are derived. When the
semantic layer is constructed correctly, the user can drag and drop semantic elements at will into the reporting template and have confidence that the results will be correct. (“Constructed
correctly” often requires the creation of multiple semantic layers, each dedicated to supporting a particular segment of ad hoc reporting need. The user must be educated as to which one to choose
for each need. It is rare that one size will fit all.)
2. Data cubes
ledger, based on a well-defined and rigorously enforced chart of accounts. Instead of a folder-view of elements, the semantic layer for the OLAP cube is a spreadsheet-like view, complete with data.
The user can drill-down or roll-up the data by clicking. Graphs and charts are also available. The term semantic layer is not typically used in the context of OLAP cubes, but the cube is a semantic
interface to the data nonetheless.
The Semantic Model is the Semantic Layer
Here is an example of a list of semantic elements (without the all-important definitions):
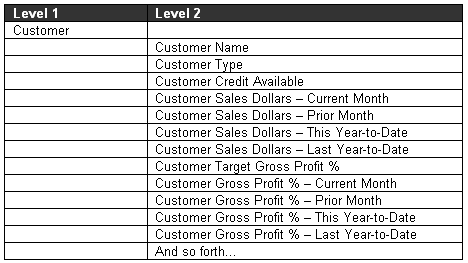
The appearance and the manner in which the data elements are manipulated are different in the query and reporting environment versus that of the OLAP cube, but the difference is only skin deep. The
same semantic elements, or appropriate sub-sets, are present in both.
There are significant technical differences in how the semantic layer is transformed into the “user view” in the query and reporting environment versus the OLAP cube, but the semantic elements
don’t change. Year-to-Date Sales is Year-to-Date Sales, whether in the query and reporting environment or in an OLAP cube. The same care must be taken in understanding the semantic issues.
The validated semantic model already contains most of the metadata-the business definitions and source data transformations-and that metadata should be incorporated into the tool implementation of
the semantic layer.
Designing the Data and the Process
Creating the Physical Data Model(s)
Given the variety of data warehouse sizes, environments, complexity and purpose, there is not one standard recommended architecture. There will probably be two, but as many as four or five physical
data models to consider: staging area, operational data store (ODS), atomic data warehouse (ADW), data mart and OLAP cube.
There are many factors in addition to semantics that influence the architecture decisions for determining how many physical platforms are needed and how the data should be moved across platforms.
The need for “division-restricted” views of data may, for example, be best implemented by creating a set of separate divisional data marts with a larger data mart containing all divisions for
corporate use.
Whatever the architecture, the design of the data structure that directly interfaces to the query and reporting or OLAP cube tool’s semantic layer must be designed to fully support that
layer. It is a mistake to think that a physical data warehouse database can be designed that will correctly support any semantic layer implementation. Only by understanding the semantic model and
its implementation in the tool can the correct supporting physical structure be designed. In other words, the key design principal driving the design of the physical database is that it must
support the semantic implementation.
Understandably, there are tradeoffs in the database/semantic layer interface. By combining an understanding of how the reporting tool works with the insights gained from the semantic modeling
process, the design tradeoffs are understood and an optimum approach adopted. One of these tradeoffs is in the design of the structures to support aggregated elements- Year-to-Date Sales, for
example. From the example above, it’s clear that the “Year-to-Date Sales” element should be explicit in the semantic layer, as it is explicit in the semantic model. The design decision to be
made is: should the calculation for Year-to-Date Sales be made during the Extract, Transform, and Load (ETL) process and placed in the physical database, or should Sales-by-Month (for example) be
stored in the database and the burden of calculating Year-to-Date placed on the query tool at run time? The answer lies in the significance of the need for the aggregated Year-to-Date numbers and
the burden placed on the user to create the element, versus the need for the monthly numbers and the associated performance trade-offs. The semantic model can help determine that significance.
(Typically, the performance of the ETL tool and the performance of the query and reporting tool must also be taken into consideration.)
Another example is the need to provide multi-level percentages, like Gross Profit Percent at the invoice line, as well as rolled-up product, and customer levels. These semantic elements cannot be
put into the database itself. They must be calculated at run-time by the query and reporting tool. If Gross Profit Percent is included in the database at the lowest detail level and placed in the
semantic layer accordingly, when a query is requested to sum the sales for a given customer over a month, and also display the aggregated Gross Profit Percent, the query tool will perform a simple
addition of the Sales Dollar field and the Gross Profit Percent field. See what can happen to a customer with four invoice line items in a month:

Leaving it up to the reporting tool to calculate Gross Profit Percent at each requested summary level solves the problem. If a Gross Profit Percent is included in the invoicing system’s invoice
line item, it should be ignored. This is another example of why understanding the semantics of the data is essential for success.
Designing the Source to Target Map
Finally, the transformations documented as part of the target-to-source mapping exercise to discover semantic anomalies can be leveraged in creating the source-to-target ETL mappings. This is the
case whether the transformations are implemented at source-to-staging, or staging-to-ODS, or staging to ADW.
