 Data Vaults have enormous potential to deliver value, but to do so, we’ve got to turn the spotlight off the technology. Sure, we absolutely need some underpinning techo stuff, but if we want tangible value for the business, we must focus on …?
Data Vaults have enormous potential to deliver value, but to do so, we’ve got to turn the spotlight off the technology. Sure, we absolutely need some underpinning techo stuff, but if we want tangible value for the business, we must focus on …?
Focus on what? Yes, focus on the business.
The preceding article in this series looked at some reasons why a Data Vault design should be based around the enterprise view, why some people might ignore this sound advice, and finally we began to look at some tips-&-techniques for actually applying a top-down enterprise view to the design of a Data Vault, starting with Hubs.
This next segment of the paper continues the application of a top-down enterprise view, this time to Data Vault Links and Satellites, and then shares some concluding thoughts.
This 2-part series is itself the 3rd part of a trilogy of papers also published on TDAN.com that began by looking at “why” top-down models should be considered, not just for Data Vault projects. A second, companion set of materials articulated “how” to develop such models.
Designing the Links
Introducing One Problem – “Clean” and “Ugly” Feeds
So at this point, we’ve designed the hubs to strongly align with the business view. That’s a really good start. Next we need to “link” them together.
The population of the world can be divided many ways; for example: based on wealth, country of birth, first language, and many more classifications. Similarly, links can be classified many ways (same-as links, hierarchical links, etc.). The classification I am choosing to focus on is whether the source feed that provides the data is somewhat “ugly” or is “clean.” But what on earth do I mean by those terms?
A more technically precise way of labelling “ugly” data is that it’s not normalised. A typical example might be an extract from a source system where multiple joins across multiple tables have been performed to get a flat extract file. Another example might be a transaction (an order, a payment, a job-ticket completion, and so on). It, too, may contain a diverse mixture of data. In Data Vault terms, these “ugly” source feeds often reference many hubs. The order transaction, for example, might refer to the customer placing it, the product being ordered (each line item for a real-word order might come through as a separate transaction row), the salesperson who negotiated the order, and the store where the salesperson works.
Conversely, a “clean” data feed is typically closer to representing normalised data. Taking the order scenario again, if we have Change Data Capture (CDC) turned on in the source system’s database, we might be presented with lots of tight little feeds. For example, the allocation of a salesperson to a store might be triggered by a Human Resources event, and only refer to two hubs – the salesperson (an employee) and the store (another hub). A totally separate feed might associate the order to the customer, and yet another set of individual feeds might associate individual line items to products.
A Pattern We Can Study
For those that have studied the Light-Weight Data Model Patterns supplement to Part #2 of the trilogy, you will have encountered a pattern for assignment of resources to tasks. If we extend the base pattern with a few subtypes for managing emergencies (floods, wildfires …), we might have a model as follows:

An Emergency Event is a type of “Task” – it is work that has to be managed – and all sorts of resources can be assigned to get the job done – Employees, Fire Trucks, Infrared Scanner Aircraft, and many more. The above diagram shows how the generic data model patterns can form a framework, with a little bit of specialisation. Then against this we map the more detailed specialisation required as we drill down into source-system specifics over the next few pages.
Handling “Clean” Data
Let’s look at some hypothetical scenarios from the emergency response.
Firstly, within the Human Resources (HR) department, they can be approached to release employees into a pool of available resources for a particular emergency (fire, flood …). Maybe they’ve been asked for one logistics officer, two bulldozer drivers, and three firefighters. They talk to candidate employees and one by one release them to the fire. The HR screen they use might look something like the following:

Now we look at a second scenario. Instead of pushing resources into the pool, an administrative officer working on the wildfire response thinks of particular people he/she would like assigned, and uses his/her screen to log specific requests to pull the nominated people into the wildfire’s resource pool:

Interestingly, it’s really the same data structure in both cases, even though sourced from two separate operational systems. Nominate an employee (one hub), nominate a wildfire or flood (another hub), provide some date and percent assignment details, and the transaction is completed. The enterprise data model takes a holistic view, not a source system view, and represents both source-centric scenarios as one relationship:
If you recall, we chose to design the Data Vault hubs at the Wildfire and Flood level of granularity rather than at the Emergency Event supertype level. Leaving aside the Data Vault attributes for things like load dates, source systems, and hash keys, a Data Vault model, including satellites on the links, might look like the following:

If only it were always that easy!
Handling “Ugly” Data
We will continue with scenarios from the hypothetical emergency response. This time we will start with the nice, clean enterprise data model view, and then look at the not-so-clean shape of some source data.

What is being presented in the model above is the idea that large chunks of work called Jobs are done in response to an emergency. These Jobs are broken down into smaller pieces of work, known as Tasks. Timesheets are filled in for Employees working on the Tasks, and signed by other Employees to authorize payment for work done. Each line on the timesheet refers to a specific Task the Employee worked on at the nominated time.
 We could try to “normalize” the input, breaking it into the relationships represented by the enterprise data model. There are implied relationships between emergency events and their jobs, between those jobs and the smaller tasks they contain, and so on. But if you notice the highlighted bits of the third row, maybe these implied relationships may contain bad data. Does the Emergency Event Wildfire WF111 really contain tasks prefixed with Job WF222?
We could try to “normalize” the input, breaking it into the relationships represented by the enterprise data model. There are implied relationships between emergency events and their jobs, between those jobs and the smaller tasks they contain, and so on. But if you notice the highlighted bits of the third row, maybe these implied relationships may contain bad data. Does the Emergency Event Wildfire WF111 really contain tasks prefixed with Job WF222?
This overly simple example carries a message. If you’ve got transactions coming into the Data Vault that are not normalized (and hence may reference lots of hubs), you may be better creating a link for the raw transaction, with a dump of its data in the satellite, and with full audit back to the source:

Later, using business rules, you can then map to other links that represent the enterprise data model’s fundamental business relationships. The hubs referenced by such links reference the narrow neck in the egg-timer diagram presented earlier, but the links and their satellites themselves are one level closer to the source systems in the diagram, representing raw Data Vault artefacts.
Where you are directly provided “clean” source data, you can map it directly into the business-centered links belonging in the narrow neck. Job done. But while the timesheet sample above references the business hubs in the narrow neck, the link is “raw.” Thankfully it is only a few business rules steps away from cleaning up its facts.
Designing the Satellites
Satellites attach directly to their appropriate “parent” hubs and links. Examples have been given in the sections above.
The parent hubs (and links) themselves have a very strong mapping to the enterprise data model, and they should reflect the business view of corporate data. Conversely, raw Data Vault satellites are created from source feeds which, by their very nature, reflect the way those source systems see the world.
It follows that, while these satellites may be attached to business-centric objects (their hubs or links), they themselves may not be directly useable by downstream business consumers. A common practice is to create business Data Vault satellites from these raw satellites, ready for consumption. The business rules involved in the transformation can address, for example:
- Renaming source attributes to align with the enterprise data model.
- Transforming source system data types to standardize them for business consumption (e.g. converting date fields or the names and address of parties to a standard format).
- Conforming conflicting values. For example, if an employee hub has a satellite from the human resources (HR) system, and another from the payroll system, it is possible for common attributes to have conflicting or incomplete values. A business rule might say “If the HR system’s date-of-birth is null, use the Payroll system’s date-of-birth, but if both are supplied, use the HR system’s value even if the payroll system disagrees.”
- Derivation of values e.g. computing a contractor’s weekly cost by multiplying his/her hourly rate by the standard hours per week.
There is an alternative to having (1) source attribute names and data types in the raw Data Vault satellites and (2) business-centric names and data types in the business Data Vault satellites. This approach is to simply transform the names and data types while loading the raw Data Vault satellites. One advantage is that the data is closer to being consumption ready. One disadvantage is that, for example, I have come across data scientists who are familiar with source system names and want to see them directly. And, of course, if this approach is used, there must be traceability back to the source, and this won’t be via the business rules layer between raw and business Data Vault.
Yet another approach is emerging, driven in part by the capabilities of platforms such as Data Lakes to store persistent copies of source data. In this scenario, the responsibilities of raw Data Vault satellites can at least in part be delegated to a Data Lake platform. But here’s the key message again. These replacement “satellites” still need to be associated with the business-centric hubs and links, which in turn lean heavily on the articulation of the enterprise data model. Whichever way you go, you need a business-centric view to drive the Data Vault design.
Pulling it Together
Isn’t it Risky Having All the Eggs in One Basket?
The above discussion advocates that we design and build a single, unified business Data Vault. So we want a single cohesive view, but what if we get its design wrong? Isn’t that a serious risk? Aren’t we putting all our eggs in one basket?
The answer is that the risk is not as high as it may appear.
- The fundamentals of an enterprise ontology are unlikely to radically change unless the business profoundly changes, as may be true when companies merge. By designing the Data Vault around the business rather than around technology, we start with greater stability. Sure, there will be some business changes, but when they do happen, there are two more saving graces.
- If the enterprise data model upon which the Data Vault is based is itself constructed using data model patterns, these patterns have been proven again and again to be resilient to change. Len Silverston calls them “universal” data model patterns because of their ability to be applied widely. If you want to read more about data model patterns, David Hay’s and Len Silverston’s books are on my recommendation shortlist.
- Data Vault, by its very nature, is more adaptable to change. I recommend reading Dan Linstedt and Michael Olschimke’s book, “Building a Scalable Data Warehouse with Data Vault 2.0” for hints on accommodating change.
It’s a Process
Designing and building a Data Vault is a process. A business-centric design, based on patterns, can be reasonably expected to be closer to the mark from the outset, but it won’t be perfect, and even it if was, we need a process for when things in the real world change. Let’s look deeper at the last bullet point above on the inherent adaptability of Data vault, starting with a business view of employees as a super type, with salaried and contractor subtypes.
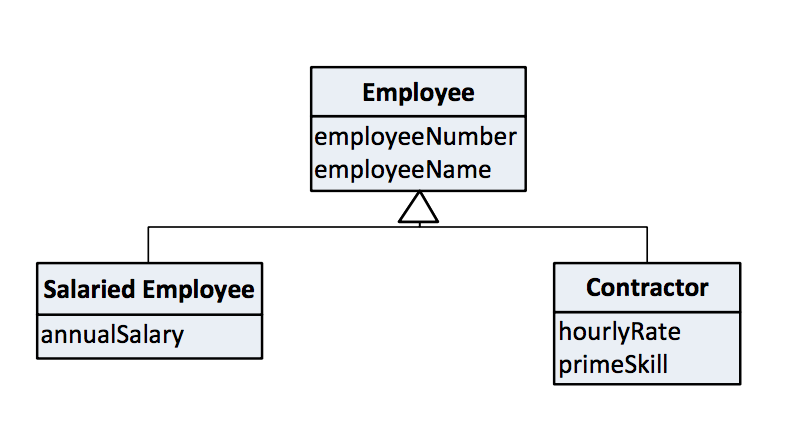
In scenario #1, the Data Vault modeller decided that Salaried Employee and Contractor were sufficiently different to have a hub each. That’s the way they’re built, along with their related satellites and links. Sometime later, this is deemed to be “wrong.” It should have been a single Employee hub. What do we do?
- Create the new Employee hub.
- Redefine the mapping of the data feeds to point to the new hub rather than the old pair of hubs, and start loading to it from now on.
- Leave the historic data against the old pair of hubs. Their satellites won’t change as the mapping now directs future feeds to the single Employee hub.
- In the business Data Vault, consolidate the two different views, merging the two historically separated views with the new single hub.
Scenario #2 flips things the other way. The original design was for one Employee hub, but new insight suggests is should have been a pair of hubs – one for Salaried Employee and one for Contractor. What do we do? Create the two new hubs, redefine the mapping, leave the historic data untouched, and present a consolidated view of a pair of hubs, with the historically single-view deconstructed to align with the two new hubs. Too easy!
I’ve encountered Data Vault practitioners who seem to fear the consequences of having a single hub that represents one business concept but has data feeds from differing source systems, maybe with different key structures, and with key values that may not neatly align. In the above example, Salaried Employees may be sourced from a payroll system, and Contractors from a contract management system. In the (very) short term, it seems easier and quicker to separate variations of IT system perspectives rather than accept a business-centric view.
In Data Vault, we are aiming at integration around common business concepts. Let’s design and build to that view, with the comforting knowledge that we can adjust as needed. But always start with the business!
In Conclusion
Australia has some cities that grew somewhat organically, and that origin is reflected in some chaotic aspects! It also has some major cities that were planned from the outset, where the designers articulated vision for the end-state, and the authorities defined a clear path to get there.
Some Data Vault practitioners appear to follow simplistic bottom-up raw Data Vault design and hope the business Data Vault will magically appear. Like the source-driven tool vendors, they can impress with their speedy delivery of something, but subsequent delivery of tangible business value may be much slower.
Of course, Data Vault is flexible, adaptive, agile. You can create source specific hubs and links, and later create business Data Vault artifacts to prepare the raw data for business consumption. But if you head down this route, you can expect an explosion of raw hubs, followed by a matching explosion of source-specific links.
Data Vault is about integration. Just because Data Vault can use the business rules layer to untangle a messy gap between source-specific hubs and links in the raw Data Vault, and ready-for-consumption artefacts in the business Data Vault, why should it? Why not create a small number of clean, agreed, business-centric hubs, and then define business-centric links around them to represent the stable business relationships. Then comes the key message – the “raw” Data Vault satellites can now be loaded happily against this framework, immediately providing a useful level of integration.
The good news is that this can be done. By designing the Data Vault, from the very outset, based on an enterprise data model, you may reduce or eliminate “business debt.” And hopefully this paper will help you achieve tangible business value both initially and in the longer term.
And now a parting thought. While Data Vault is capable of cleaning up problems in the source operational systems, let’s not forget the role of data governance in moving resolutions back to the source where reasonably possible. Operation staff who use these source systems will thank you. But to guide such an endeavor, you’ll benefit if you start with a top-down enterprise model. Which takes us full circle!
Acknowledgments
Many of the ideas presented in this paper were refined during one Data Vault project. I worked with many wonderful people at the site, but I wish to give special mention to Rob Barnard, Emma Farrow and Natalia Bulashenko. You were a delight to work with, and truly an inspiration.
I also wish to acknowledge the contribution of Roelant Vos, an internationally recognized Data Vault thought leader, who kindly provided much valued feedback across all parts of the trilogy.
