Published in TDAN.com January 2003
Abstract
The purpose of this paper is to present and discuss a patent-pending technique called a Data Vault™ – the next evolution in data modeling for enterprise data warehousing. This is
the second paper in a series of papers that will be published on a Data Vault. This paper explores a specific example: Microsoft SQLServer 2000 Northwind Database, and taking it to a Data Vault
representation. One of the most interesting concepts surrounding a Data Vault is the incorporation of S.E.I. and CMM Level 5 ideas. This poses the question: Can a Data Vault be reverse engineered
mechanically from an existing model? The answer is yes – it can. Will it be perfect? No, the algorithm that has been constructed builds a base-line Data Vault data model from an existing 3rd
Normal Form operational model. The point is that the process is repeatable and consistent; therefore portions of it can be automated.
1.0 Introduction
The purpose of this paper is to present and discuss a patent-pending technique called a Data Vault™ – the next evolution in data modeling for enterprise data warehousing. The audience
of this paper should be the data modelers who wish to construct a Data Vault data model. This paper focuses on a specific example: The Microsoft SQLServer 2000 Northwind Database. It is suggested
that for the purposes of this discussion, the reader obtains at a minimum, a trial copy of the SQLServer 2000 database engine. Please read Series 1, the original paper – defining Data Vault
architecture. This will provide the context on what the data model is, and how it fits into business. The topics in this paper are as follows:
- Examining an OLTP 3NF Model for conversion.
- The process of modeling a Data Vault (data warehouse)
- Populating a Data Vault.
- Summary and Conclusions.
Several of the objectives that you may learn from this paper are:
- How the components of a Data Vault interact with each other.
- How to model a Data Vault.
- How to populate a Data Vault.
- An understanding of converting 3NF OLTP to a Data Vault Enterprise Data Warehouse (EDW)
Let’s consider this for a moment: suppose it is possible to reverse engineer a data model into a warehouse. What would that mean for a data warehousing project? Suppose it could be done in an
automated fashion, would that help or hurt? What if the only consideration necessary to make is how to integrate different aspects of the generated data models? These and many more questions come
to mind when beginning to consider the automation of data modeling for data warehousing, particularly when the consideration involves mechanized engineering.
For our purposes, having this functionality to produce a baseline Data Vault would be of tremendous help. The Northwind data model was converted both by hand, and through an automated fashion. When
the two data models were compared they only had minor differences. Further examination showed that hand-conversion opened up the possibilities for errors in Link tables where the automated
converter kept the Links clean. Some of the most important items to mechanizing the process are: naming conventions, abbreviation conventions and specification of primary / foreign keys.
What’s important here is that this is a baby step into the application of “dynamic data warehousing” or dynamic model changes (please see my other article: Bleeding Edge Data
Warehousing – due out in the Journal of Data Warehousing Fall 2002). It also provided a data model in ten minutes (for this particular example), when it took roughly two hours to convert it
by hand. It then took an additional twenty minutes to adjust the model slightly, and implement it. Keep in mind this is a small data model and all that is proposed is auto-vaulting of one OLTP data
model at a time. The automated process isn’t smart enough yet to integrate end-resulting Data Vault data models.
The DDL is available on a web link: http://www.coreintegration.com Sign in to our free online community, the Inner Core, and click on Downloads, select
Data Warehousing, then find the zip file titled: DataVault2DDL.zip (for this series). The DDL and the views are built for Microsoft SQLServer 2000. Feel free to convert them to a database of your
choice. The automated mechanism is not available today – it’s still in an experimental phase. The DDL contains the tables for a Data Vault and the views to populate the structure both
initially and with changes.
Please keep in mind; this is not a “perfect Vault” and has not been conditioned to be the same quality of data model as delivered to the customer. This is meant as an example only, for
trial purposes. Feel free to contact me directly with questions or comments.
2.0 Examining an OLTP 3NF model for conversion
Some OLTP data models in 3NF are easier to convert than others. However, there are some distinctive properties which make the conversion process easy. Here are a few items to look for:
- How well does the data model adhere to standard naming conventions? This will have an affect on integration of fields. If the fields (attributes) are named the same across the model, then the
resulting Data Vault will be easier to build, as well as easier to identify which components have been translated. - How many independent tables are in the data model? Independent tables usually don’t integrate in a Data Vault very well. It is a stretch to integrate the table through field name
matching. Normally these independent tables are copied across into a Data Vault as standalone tables – until integration points can be found. - Have Primary and Foreign Key relationships been defined? If referential integrity has been turned off in the data model, it will be exceedingly difficult to create a Data Vault model. It is
near impossible to automatically convert it, however, through some hard work and rolling up of the sleeves (digging into business requirements) it can be done effectively. - Does the model utilize surrogate keys instead of natural keys? The converted data model favors natural keys over surrogate keys. The models that are converted by hand require that the data
modeler understands the business well enough to identify the business keys (natural keys) and their mapping to the surrogate keys. - Does the model match the business requirements for the data warehouse? If the requirements are to integrate or consolidate data across the OLTP system (such as a single customer view, or a
single address view) then the process of converting to a Data Vault may be a little more difficult. The process may require cross-mapping data elements for integration purposes. - Can the information be separated by class or type of data? In other words, can all the addresses be put in a single table, all the parts in another table, all the employees, etc? Separating the
classes of data helps with the integration effort. This is usually a manual cross-mapping and regrouping of attributes. - How quickly do certain attributes change? A Data Vault likes to separate data by rates of change. It is easier to model a Data Vault if an understanding of the rates of change of the underlying
information is known.
These are just a set of suggested items to consider before converting the data model. They are by no means a complete list. First and foremost, the data warehouse data model should always follow
the business requirements, regardless of how the base-line or initial model is generated. It is suggested that a scorecard approach be developed. Over time, these items will be on a scale of
difficulty, when that happens – it will provide a good guideline as to the “convertibility” of a particular data model. Future series will cover migrating Conformed Data Marts and
other types of adapted 3NF EDW to a Data Vault schema.
2.1 The Northwind Database
Northwind is built by Microsoft, and is installed on every Microsoft SQLServer 2000 database. It is freely accessible with sample data. The data model is shown below, in Figure 2-1.
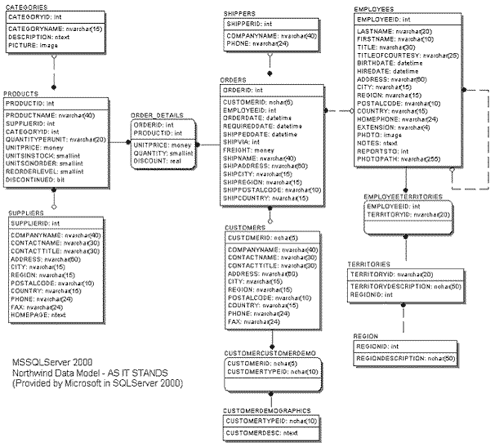
In this model the first thing to notice is the use of non-standard data types: bit, ntext, image, money. These don’t port very well to other relational databases. This is important to resolve
because most of the data warehouses are not built on the same database engine as their OLTP counterparts. In this case a Data Vault will be built on the same RDBMS engine. Another item that pops
out of the data model is the recursive relationship. Immediately this should signal a necessary change to the data model.
The naming conventions appear consistent across the model. ID is used synonymously with primary keys, primary and foreign keys are defined, there are no independent tables and the model does appear
to use some surrogate and some natural keys. For the sake of discussion, the business requirements are to house all of the data in the warehouse and store only incremental changes to the data over
time.
The attributes could be classed out (normalized) further if desired, items such as address, city, region, and postal code can all be grouped. Do certain attributes change faster than others? From
looking at the model, the two tables with the most changes might be orders and order details. There really isn’t a method that will help the discovery of rapidly changing elements in this
model. Normally rapid changing elements are either indicated by business users or provided in audit trails, usage logs or through time-stamps on the data itself. In this case, none of these are
present.
3.0 The process of modeling a Data Vault
In order to keep the design simple, yet elegant, there are a minimum number of components, specifically the Hub, Link and traditional skill sets of data modeling expertise. These were defined in
Series 1. Please refer to the first article for definitions and table structure setup. This section will discuss the process of converting the above data model to an effective Data Vault. The steps
for a single model conversion without integration are as follows:
- Identify the business keys and the surrogate key groupings, model the hubs.
- Identify the relationships between the tables that must be supported, model the links.
- Identify the descriptive information, model the satellites.
- Regroup the satellites (normalize) by rates of change or types of information.
To address more than one model start with the business identified “master system”. Build the first data model and then incrementally map other data models and data elements into the
single unified view of information.
There are three styles to load-dates in the EDW Data Vault architecture and before modeling can begin it is wise to chose a style that suites your needs. The styles are as follows:
- Standard Load Date as indicated by this article and previous article. This is easy to load, difficult to query. For more than two satellite tables off a hub it may require an additional
“picture table” or point-in-time satellite to house the delta changes for equi-joins. - Load Date data type altered to be an integer reference to a Load Table where the date is stored. Integer’s reference is a stand-alone foreign key to a load table and can be used if date
logic is not desired. Be aware that this can cause difficulties in re-loading, and re-sequencing the keys in the warehouse. This is not a recommended practice / style. - Load End Date is added to all the satellites. Rows in satellites are end-dated as new rows are inserted. This can help the query perspective and at the same time can make loading slightly more
complex. Using this style, it may not be necessary to construct a picture table (point-in-time satellite).
Select the style that best suits the business needs and implement it across the model. Part of the Data Vault modeling success is consistency. Stay consistent with the style that’s chosen and
the model will be solid from a maintenance perspective.
3.1 Hub Entities
Since the Hubs are a list of business keys it is important to keep them together with any surrogate keys (if surrogates are available). Upon examination of the model we find the following business
key/surrogate key groupings (the examination included unique indexes and a data query):
- Categories: CategoryName is the business key, CategoryID is the surrogate key. This will constitute a HUB_Category table.
- Products: ProductName is the business key, ProductID is the surrogate key. This will constitute a HUB_Product table.
- Suppliers: SupplierName is the business key, SupplierID is the surrogate key. This will constitute a HUB_Supplier table.
- Order Details: has no business key, and cannot “stand on its own”. Therefore it is NOT a hub table.
- Orders: Appears to have a surrogate key – which may or may not constitute a business key (depends on the business requirements). Upon further investigation we find
many foreign keys. The table appears to be transactional in nature which makes it a good candidate for a LINK rather than a HUB table. - Shippers: CompanyName is a business key, and ShipperID is the surrogate key. Shippers will constitute a HUB_Shippers Table. If the business requirements state that an
integration of “companies” is required, then the CompanyName field in Shippers can be utilized. However, if the business requirements state that shippers must be kept separate, then
CompanyName is not descriptive enough, and should be changed to ShipperName in order to keep with the current field naming conventions. - Customers: CompanyName is the business key, and CustomerID is the surrogate key. Customers will constitute a HUB_Customers table. Again, if integration is desired, then
maybe an entity called: HUB_Company would be constructed (to integrate Customers and Shippers). - CustomerCustomerDemo: Has no real business key, and cannot stand on its own. Therefore it will be a Link table.
- CustomerDemographics: Upon first glance, CustomerDesc appears to be the business key with CustomerTypeID being the surrogate key, however, this could also be constructed
as a Satellite of Customer. Remember that the warehouse is meant to capture the source system data, not enforce the rules of capture. For the purposes of this discussion, HUB_CustomerDemographics
will be constructed. - Employees: EmployeeName appears to be the best business key, with EmployeeID being the surrogate key. This will constitute a HUB_Employee table.
- EmployeeTerritories: There appears to be no real business key here, this will not constitute a HUB table, most likely it will become a Link table.
- Territories: TerritoryDescription appears to be the business key, with TerritoryID being the surrogate key. This will constitute a HUB_Territories table.
- Region: RegionDescription is clearly the business key, RegionID is the surrogate key. This table will constitute a HUB_Region table.
Once the analysis has been done for each of the table structures, we can assemble the list of hub tables that will be built: Hub_Category, Hub_Product, Hub_Supplier, Hub_Shippers, Hub_Customer,
Hub_CustomerDemographics, Hub_Employee, Hub_Territories. There are a couple of questionable items which depending on the business rules may have their structure integrated. Remember that the hub
structures are all very similar, an example of the Hub_Category looks like this:
Create Table Hub_Category (
CategoryName nvarchar(15) NOT NULL,
LOAD_DATE DateTime Not Null,
RECORD_SOURCE nvarchar(12) not null,
Primary Key (CategoryID)
)
Create unique index hub_category_i1
Now that we have the hub structures, we can move on to the links. The function of the hubs is to integrate and centralize the business around the business keys.
3.2 Link Entities
The Links represent the business processes, the glue that ties the business keys together. They describe the interactions and relationships between the keys. It is important to realize that the
business keys and the relationships that they contain are the most important elements in the warehouse. Without this information, the data is difficult to relate. Typically transactions and
many-to-many tables constitute good Link tables. Along with that, any table that doesn’t have a respective business key becomes a good link entity. Tables with a single attribute primary key
mostly make a good Hub Table, however the requirement is still for a business key. In the case of Orders, a business key does not exist. The link tables of our model are as follows:
- Order Details: Many to many table, excellent Link table. LNK_OrderDetails will be constituted.
- Orders: Many to Many, Parent transaction of Order Details, excellent Link Table. LNK_Orders will be constituted. However, please note: It may or may not be appropriate
to constitute Hub_Orders as a hub table depending on the business – and it’s desire to track Order ID. In this case, we will keep it as a Link table. - CustomerCustomerDemo: Many to many table, excellent link table. LNK_CustomerCustomerDemo will be constituted.
- EmployeeTerritories: Many to many table, excellent link table. LNK_EmployeeTerritories will be constituted.
Did we get all the linkages? No. Look again. There are some parent/child foreign key relationships in tables that are slated to become Hubs. Hubs don’t carry parent/child relationships or
resolve granularity issues. Examining the Products table, we see both a CategoryID and a SupplierID. This will constitute a LNK_Product Table, including the ProductID, SupplierID, and CategoryID.
In a true data warehouse we would construct a surrogate key for this link table – however in this case the data model states that ProductID is sufficient to represent the supplier and
category (as indicated by OrderDetails). No surrogate key is necessary.
In cases of integration (across other sources), it may be necessary to put the surrogate key into multiple link tables. Are there other parent child relationships that need a linkage? Yes,
Employees has a recursive relationship. To draw this out, we will construct a LNK_EMPLOYEE table, so that the “reportsto” relationship can be handled through a link table. There are no
more relationships that need to be resolved. Now we can move on to Satellite entities. An example of a link table is below:
Create Table LNK_PRODUCTS (
CategoryID int NOT NULL,
SupplierID int NOT NULL,
LOAD_DATE DateTime Not Null,
RECORD_SOURCE nvarchar(12) not null,
Primary Key (ProductID),
Foreign Key (SupplierID) references HUB_Supplier,
Foreign Key (CategeoryID) references HUB_Category
)
3.3 Satellite Entities
The rest of the fields are subject to change over time – therefore they will be placed into Satellites. The following tables will be created as Satellite structures: Categories, Products,
Suppliers, Order Details, Orders, Customers, Shippers and Employees. The Satellites contain only non-foreign key attributes. The primary key of the Satellite is the primary key of the Hub with a
LOAD_DATE incorporated. It is a composite key as described in series 1. In the interest of time and space only one example of a Satellite will be listed below:
Create Table SAT_Products (
LOAD_DATE DateTime Not Null,
QuantityPerUnit nvarchar(20),
UnitPrice money,
UnitsInStock smallint,
UnitsOnOrder smallint,
ReOrderLevel smallint,
Discontinued bit,
RECORD_SOURCE nvarchar(12) not null,
Primary Key (ProductID,LOAD_DATE)
Foreign Key (ProductID) references HUB_Products
)
The physical data model now appears as follows:

If this is difficult to read, the full image is available on a PDF (in the ZIP file on the Inner Core Downloads) at: www.coreintegration.com (sign up
for the Inner Core – its free, then go to the downloads section). This is the entire data model with all the hubs in light gray/blue, the links in red, and the satellites in white. This is
style 1, with just a standard load date being utilized. In the interest of space the other styles will be represented in a future article.
4.0 Populating a Data Vault
If the Auto Vault generation process is used, the views will be generated to populate the data structures, right along with the generation of the structures themselves. In this case, the views have
been generated. A sample is provided of one of each of the Hubs, Links, and Satellites.
The Hubs are inserts only. They record the business keys the first time the data warehouse sees them. They do not record subsequent occurrences. Only the new keys are inserted into the Hubs. The
Links are the same way, they are inserts only – for only the rows that do not already exist in the links. The Satellites are also delta driven. The Satellites insert any row that has changed
from the source system perspective, providing an audit trail of changes.
Another purpose of a Data Vault structure is to house 100% of the incoming data, 100% of the time. It will be up to the reporting environments, and the data marts, to determine what data is
“in error” according to business rules. A Data Vault makes it easy to construct repeatable, consistent processes, including load processes. The architecture provides another baby step
in the direction of allowing dynamic structure changes.
To load the Hubs: select a distinct list of business keys with their surrogate keys, where the keys do not already exist in the hub.
CREATE VIEW V_INS_HUB_CATEGORIES AS
GETDATE() LOAD_DATE,
‘NORTHWIND’ RECORD_SOURCE
FROM NORTHWIND..[CATEGORIES] A with (NOLOCK)
WHERE NOT EXISTS
To load the Links: select a distinct list of composite keys with their surrogates (if provided), where the data does not already exist in the link.
A.ORDERID,
A.CUSTOMERID,
A.EMPLOYEEID,
A.SHIPVIA,
GETDATE() LOAD_DATE,
‘NORTHWIND’ RECORD_SOURCE
FROM NORTHWIND..[ORDERS] A with (NOLOCK)
WHERE NOT EXISTS
(SELECT * FROM LNK_ORDERS WITH (NOLOCK))
To load the Satellites: select a set of records, match or join to the business key (or by composite key if possible), where the columns between the source and target have at least one change. Match
only to the “latest” picture of the satellite row in the satellite table for comparison reasons.
CREATE VIEW V_UPD_SAT_EMPLOYEES AS SELECT
A.EMPLOYEEID,A.LASTNAME, A.FIRSTNAME, A.TITLE, A.TITLEOFCOURTESY, A.BIRTHDATE,
A.HIREDATE, A.ADDRESS, A.CITY, A.REGION, A.POSTALCODE, A.COUNTRY,
A.HOMEPHONE, A.EXTENSION, A.PHOTO, A.NOTES, A.REPORTSTO, A.PHOTOPATH,
GETDATE() LOAD_DATE, ‘northwind’ RECORD_SOURCE
FROM northwind..[employees] A with (NOLOCK),
SAT_EMPLOYEES B with (NOLOCK)
WHERE A.EMPLOYEEID = B.EMPLOYEEID
AND (isnull(A.LASTNAME,’x’) != isnull(B.LASTNAME,’x’)
OR isnull(A.FIRSTNAME,’x’) != isnull(B.FIRSTNAME,’x’)
OR isnull(A.TITLE,’x’) != isnull(B.TITLE,’x’)
OR isnull(A.TITLEOFCOURTESY,’x’) != isnull(B.TITLEOFCOURTESY,’x’)
OR isnull(A.BIRTHDATE,convert(datetime,’01/01/1960′)) !=
isnull(B.BIRTHDATE,convert(datetime,’01/01/1960′))
OR isnull(A.HIREDATE,convert(datetime,’01/01/1960′)) !=
isnull(B.HIREDATE,convert(datetime,’01/01/1960′))
OR isnull(A.ADDRESS,’x’) != isnull(B.ADDRESS,’x’)
OR isnull(A.CITY,’x’) != isnull(B.CITY,’x’)
OR isnull(A.REGION,’x’) != isnull(B.REGION,’x’)
OR isnull(A.POSTALCODE,’x’) != isnull(B.POSTALCODE,’x’)
OR isnull(A.COUNTRY,’x’) != isnull(B.COUNTRY,’x’)
OR isnull(A.HOMEPHONE,’x’) != isnull(B.HOMEPHONE,’x’)
OR isnull(A.EXTENSION,’x’) != isnull(B.EXTENSION,’x’)
OR isnull(CONVERT(varbinary(2000),A.PHOTO),0) != isnull(CONVERT(varbinary(2000),B.PHOTO),0)
OR isnull(CONVERT(varchar(2000),A.NOTES),’x’) != isnull(CONVERT(varchar(2000),B.NOTES),’x’)
OR isnull(A.REPORTSTO,0) != isnull(B.REPORTSTO,0)
OR isnull(A.PHOTOPATH,’x’) != isnull(B.PHOTOPATH,’x’)
)
The view is built to handle null comparisons, as well as chop the comparison on text and image components to only 2000 characters. The comparison is extremely fast, and is a short-circuit Boolean
evaluation. These views are run as Insert Into… Select * from . They satellite view is fast as long as partitioning is observed along with the primary key.
Views work well when the source and a Data Vault are in the same instance of the relational database engine. If different instances are utilized, then there are two suggested solutions: 1) stage
the source data into the warehouse target, so that the views can be used. 2) utilize an ETL tool to make the transfer and comparison of the information. However, staging the information in the
warehouse, and utilizing the views allows the database engine to keep the data local, and in some cases take advantage of the highly parallelized operations in the RDBMS engine (such as Teradata
for instance).
5.0 Summary
This series provides a look at implementing and building a Data Vault along with a sample Data Vault structure that most everyone has access to. This simple example is meant to show that a Data
Vault can be built in an iterative fashion and that it is not necessary to build the entire EDW in one sitting. It is also meant to serve as an example for the previous series, showing that this
modeling technique is effective and efficient. The next series will dive into querying this style of data model and will discuss Style 3 – Load End Date of records vs. the point-in-time
satellite structure.
© Copyright 2002-2003, Core Integration Partners, All Rights Reserved. Unless otherwise indicated, all materials are the property of Core Integration Partners, Inc. No part of this
document may be reproduced in any form, or by any means, without written permission from Core Integration Partners, Inc.
