Geospatial data has a significantly different structure and function. It includes structured data about objects in the spatial universe – their identity, location, shape and orientation, and other things we may know about them. Geographical data describe an incredibly wide range of objects or business assets – roads, buildings, property lines, terrain, infrastructure, hydrology and ecosystems. All these objects can be described in terms of points, lines and polygons – and tables of these objects constitute the tabular portion of geospatial data.
Geographical information system technology also accommodates some kinds of unstructured data (usually raster imagery) that can be tagged and geocoded (given precise positional characteristics) and integrated by GIS software to the other kinds of map data.
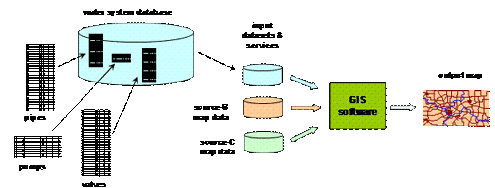
Thus the management of GIS data and metadata is somewhat different. Whereas traditional tabular data could be understood by a human looking at any printed expression of the data (usually in rows and columns, even on paper), raw GIS data is generally meaningless to the human eye until converted into a map. This is what GIS software does.
However, because of the complexity of the storage and expression of GIS data, the software is heavily dependent upon formalized metadata conforming to rigorous metadata standards. Any positional coordinates of geographic objects must be stored in a reference system (e.g., X and Y coordinates) and a projection (remember the distorted maps in your geography textbook?).
The problem (and the powerful opportunity) of GIS technology is that map data from various sources is often fragmented in source and format. The power comes from integrating sources (displaying power lines over terrain, for example) and displaying to the human eye the proximity-based relationships between objects of interest. Proximity can’t be “seen” in the data, but it can be seen on a map.
Sources can have different projections and reference points, and the GIS software resolves those. With GIS software, things “fit” or “line up” properly. It is the metadata that makes this happen!
Sources of Geospatial Data
Geospatial data can come from many sources. Geospatial data has been digitized by a wide variety of agencies and commercial enterprises at an increasing pace over the past ten years. The first digitization often involved tediously tracing existing paper maps with a digitizing device (similar to a mouse) to record, point-by-point, the shape of roads, rivers, contours, buildings, etc.
More recently, techniques have been developed to ease the in-field gathering of positional and other data. Utilities have field devices with a global positioning system (GPS) to gather positional information about assets (transformer vaults, utility poles, hydrants, valves, etc.) as well as allowing the entry of other data about the asset. Some even allow you take a photo of the hydrant that is included in the geocoded data record. Mapping companies sometimes drive special vehicles around the street system, taking photographs and noting the exact coordinates – all digitized to make salable street maps.
Imagery can sometimes be interpreted by specialized software to derive roads and other objects, but this is not as reliable as human, on-the-ground observations.
What results from such data construction is a set of files containing one record for each component of a geographic object. For example, a segment of street (between two connecting streets) would be one record, containing an ID, a single field of geographic data (impossible for the human eye and brain to interpret), and certain useful non-GIS attributes (such as the street name, the street width, the surface material, etc.).

The streets connect at nodes (a distinct subject entity in the street data model, deserving its own table not shown here), and curved streets will have multiple “points” along the curve as shown below.
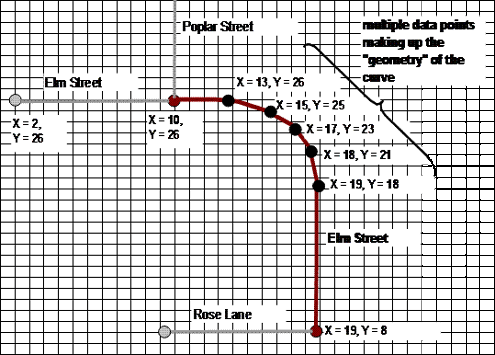
This is known as vector data in that all objects on the earth’s surface may be represented as points, lines or polygons. The nodes are points, but the streets are lines. A parcel of owned property would be represented by a polygon (below).
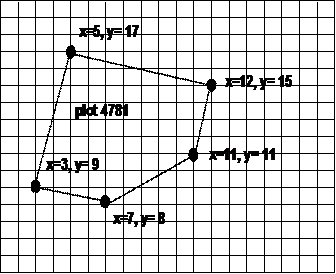
In a geospatial database, each of these objects would be grouped into object classes, and their data would be stored in separate tables.
Data about a street system (table fragment shown above) usually is stored in a separate database from data about the hydrology of the same area or the electrical system in the same city. GIS software integrates these various datasets (often coming from different authorities or sources) into a single desired representation (a map appearing on the screen, ready to be manipulated and/or printed out).
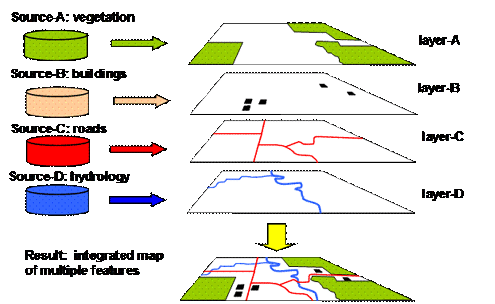
Again, it is the job of the GIS software to successfully integrate these various sources of graphical representation of objects in the desired sequence and scale.
Reference Systems
All vector data must be stored in some kind of reference system. The position of any geographic object must always be captured, stored and expressed with reference to other objects or an underlying coordinate grid.
Because the earth is not only ellipsoid, but quite irregular (nearly undulating) in the distance of its surface from the center of the earth, reference systems are complex and varied. In other words, “sea level” is irregular and can vary by as much of 150 meters (vertical) over the space of a few thousand miles (as from Sri Lanka to Borneo). The water doesn’t flow because the force of gravity is equal in those two places. So what we know as “sea level” is a result of the equal force of gravity.
Therefore, elevation data must take into consideration the issue of an irregular surface of the earth.
Geographical Coordinate Systems
A second reference issue involves the X and Y coordinates of a point. The traditional geographic coordinate system (that most Americans learned about in school) is the latitude and longitude system where the circumference of the earth is divided into 360 degrees, each degree divided into 60 minutes, and each minute potentially divided into 60 seconds of arc.
Unfortunately, there are different definitions of latitude (because of that ellipsoid), and that must be declared in the metadata of the GIS dataset.
It’s the Metadata!
What allows all this to come together is the metadata for each dataset that is used by the GIS software to properly overlay each layer coming from each source.
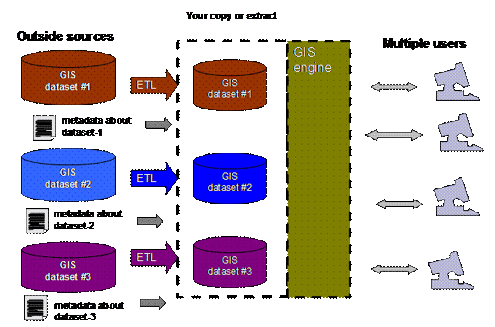
This metadata sits in an adjacent dataset, usually in XML format, which is read by the GIS “engine” to understand the coordinate system and projection of each dataset. The software then correctly overlays the data for presentation to one or more users.
The GIS community has created standards for its metadata. These standards include structured fields (absolutely essential for the software to read the data) and unstructured metadata (that is designed for humans to read and evaluate the suitability of the dataset for their needs). The Federal Geographic Data Committee (FGDC) established one metadata standard called the Content Standard for Digital Geospatial Metadata (CSDGM). A similar (and mostly compatible) ISO 19115 standard for geographic information metadata is also widely used.
Advantages of Digital Map Data
The primary result of digitizing geographic data is that the raw data is now separate from the expression of that data. Previously, a paper map was both a repository of information and an (often) artistic expression of that information. Now they are separate.
Raw data can be reused in a variety of different maps – better return on the investment in the data asset. Additionally, a wide variety of analysis can be done. For example, optimal retail sites can be evaluated using demographic information down to the census tract and street level of granularity.
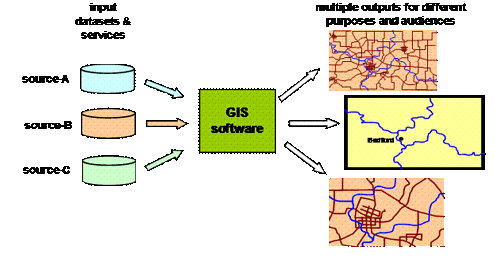
Because the data is separate from the expression, the symbols may be altered to suit the audience. Streets, for example, can be any desired color; and schools, churches and other buildings can be portrayed using a variety of symbols.
Data Sharing Culture in GIS
Unlike most competitive industries, there is a culture of data sharing in the geospatial world, which allows agencies to exchange data freely. Only a few for-profit companies that do mapping or collect imagery (aircraft and satellite) are driven by the revenue of data or imagery sales. Many government agencies freely provide their datasets for a variety of uses.
Data may be shared by the total transfer of a dataset (in bulk) from the source server to a user or through a Web-based “service” where only the data needed (limited to a small geographic subset of the total dataset) is sent to the requesting software (and user).
Finding the datasets or service you want is sometimes difficult – there are many of them out there. There are portals sponsored by various government agencies (such as www.geodata.gov) that allow the user to search for GIS datasets addressing specific topics.
A variety of business and demographic data that has been geocoded is available (at a cost) and, thus, can be integrated into the base map data.
Industry Standard Data Models
Because of this culture of sharing, there are also industry standard data models that allow not only the sharing of data among peer agencies and companies, but also the sharing of analysis tools. This is because some GIS databases not only describe a portion of the earth’s surface, but also can be used for behaving in certain ways (such as creeks and streams) supporting certain simulation software. One agency may develop a model for calculating flow through a water supply system, and it can then share that software with another agency covering a different geography.
GIS data faces the same data management challenges as traditional structured (or tabular) data. There must be appropriate versioning of data and archiving. There can be many unknowns regarding data quality and currency of any dataset. This is true especially where data may be integrated from multiple sources, some of which may have unknown reliability. Again, the metadata of original and derivative datasets must reflect all these issues.
Conclusion
This has been only a brief (and very simple) overview of the world of geospatial data. Geospatial software packages can be quite complex, but they provide a host of analysis tools. These software packages are used by nearly every major federal government agency to address geography-related problems.
Raw geospatial data (unreadable by the human eye) is nearly useless without the software to convert it to rich, graphic expression, but this is impossible without precise metadata. The business analytical possibilities of employing proximity and spatial relationships among objects are nearly unlimited.
