 Is your SQL drawing a blank? It’s NULL a surprise!
Is your SQL drawing a blank? It’s NULL a surprise!
The title of this post is a play on words, but very appropriate. We are going to discuss the inconsistent results, as well as performance implications of queries processing records with NULLS, or situations where we are expecting NULLS, but the records really contain blank values.
Before we do that, a bit of trivia – what is the origin of the phrase “drawing a blank”? The phrase is believed to come from old lotteries around the 16th century. At that time, lotteries were conducted using two containers:
- One container had lottery tickets placed inside of it, which may have had the names of the participants written on them.
- The other container held the tickets or notes that had the prizes written on them.
When it came time for the lottery to start, a lottery ticket would be drawn from the first container, followed by a prize being drawn from the second container. Some lotteries had blank prize notes, meaning that if a blank was drawn, then the person would win nothing. As time progressed this was applied figuratively to people who try to think of something, only to come up empty-handed. It’s an appropriate metaphor for the trials and tribulations that can occur with blank columns in database tables.
The Problem
When working with databases, the concept of NULL vs. blank columns can be very confusing to new users who don’t understand the difference. It can even wreak havoc for experienced users if records are being created and/or updated inconsistently. I have seen instances where multiple applications were updating the same database tables. One of the applications was using NULL to update NULL capable columns, while another was using blanks. A developer trying to write queries to populate different reports was going crazy trying to resolve inconsistent results. It was like playing a game of Russian Roulette. This is a bad situation, and it is obvious that there should be standards in place to avoid this type of inconsistency. However, we need to play the hand that we are dealt, so we will look at how to cope with this situation.
NOTE: This example was constructed using SQL Server 2014. Different database platforms can yield different results, which makes this problem even more insidious.
I will now illustrate this with a simple example. Let’s assume that you are retrieving data from a database table called “Example” and pulling it into excel to preview the data before building your report. This initial query could be as simple as:
SELECT ExampleID, FixedAlphaVal, VarAlphaVal, NumVal FROM dbo.Example
The resulting excel report looks like this:
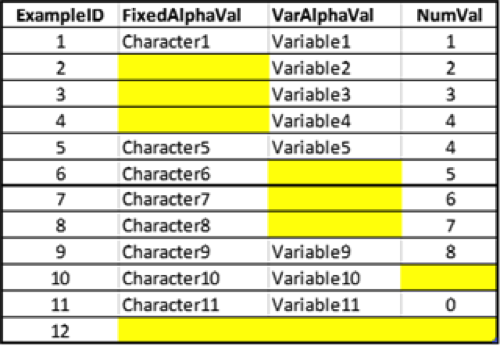
For the purposes of illustration, this example table contains 3 very carefully constructed data sets to examine behavior of queries with different data types (char, varchar, numeric) and different methods of populating records. At first glance, all the yellow cells appear to be NULL, but that is not really the case. Some are NULL, but others are populated with an empty string ” or a single space ‘ ‘. If the person working with the data is unaware of this, they may find out the hard way (or not at all, which is even worse).
Use Case 1 – CHAR Column
For the first use case, let’s assume that we want a simple report that shows all the records without a FixedAlphaVal. Therefore, we would expect the result set to contain Row 1 and Rows 5 through 11 (Rows 2 -4 and Row 12 would be filtered out of the results). We have just graduated from the SQL 101 class so we will be very clever and retrieve the records that are NOT NULL. Thus, we write the following query:
SELECT ExampleID, FixedAlphaVal FROM Example WHERE FixedAlphaVal IS NOT NULL
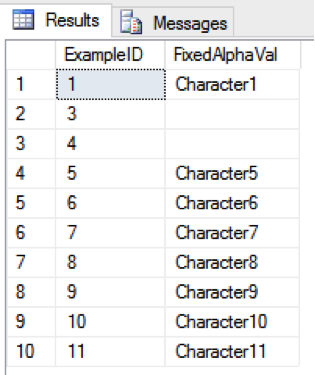
The result is shown on the left.
Wait a minute! What’s up with Rows 2 and 3 of this result set? We have just been caught in the trap where these values that appear to be NULL but they are not. NULL and Blank are not the same thing:
- NULL is the absence of any data value
- Blank is a data value
In reality, the column in Row 2 is blank and the column in Row 3 contain a single space.
The Full Data Set Revealed
To make the data easier to decipher, I have expanded the table and created descriptor columns which indicate exactly how the adjacent column is actually populated. Thus, the FixedAlphaMethod cell describes exactly how the Fixed AlphaVal cell to it’s right was populated. The same holds true for the VarAlpha and Num column sets. I have also reproduced the table with color coding to clearly illustrate the column values. Below each data column is a statistical summary by method used as well.
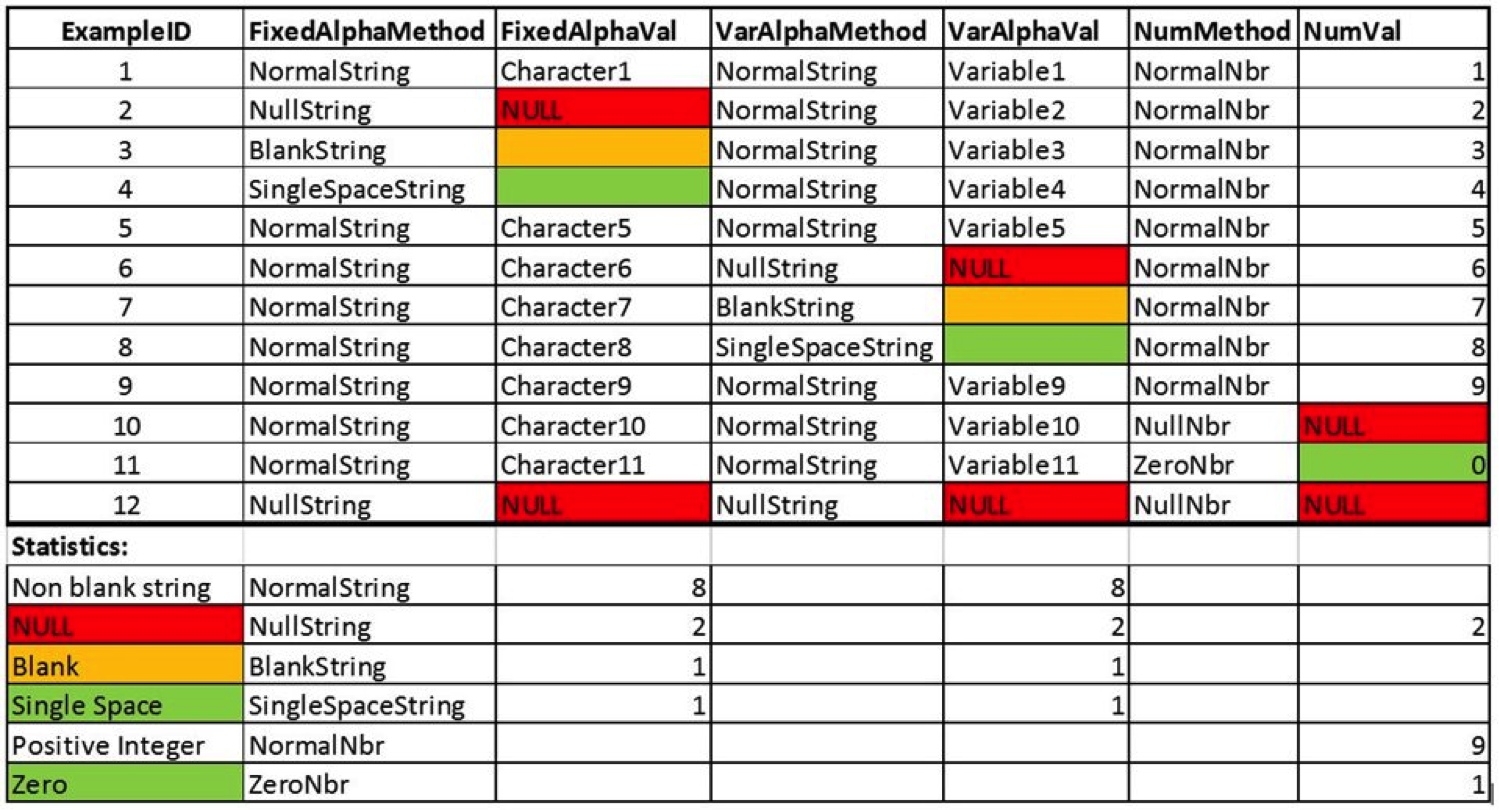
Without knowing this, building SELECT statements assuming the values are all NULL could yield very unpredictable results. When building statements for a report, these gaps will become quite evident in the building of the report itself, giving us a clue that we have a problem to solve. If the SELECT statement is embedded in a VIEW or PROCEDURE that is part of a complex process, we may not have any visibility of the incorrect result set and may be processing records incorrectly, with disastrous results.
Let’s rerun the above query including the method column to clarify our result set:
SELECT ExampleID, FixedAlphaMethod, FixedAlphaVal FROM Example WHERE FixedAlphaVal IS NOT NULL
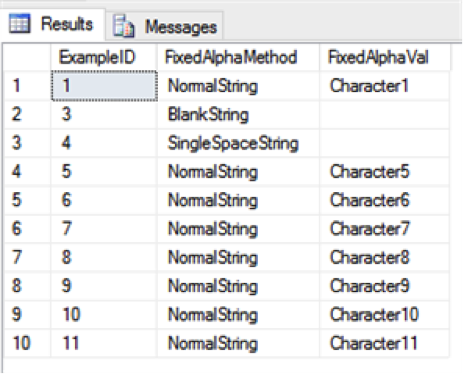
In order to get the correct result that we are looking for, we need to modify the WHERE clause to get rid of the NULLS and the Blanks. One way of doing this is to use <> instead of IS NOT NULL
SELECT ExampleID, FixedAlphaMethod, FixedAlphaVal FROM Example WHERE FixedAlphaVal <> ”
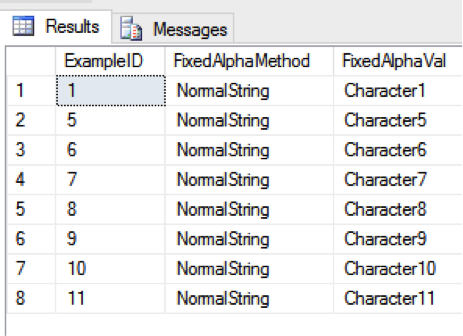
We have now achieved the result set we were looking for. It has eliminated the records with ”, ‘ ‘ and NULL.
Performance Considerations
When we are writing SQL, getting the correct result set is only part of the battle. We also want to ensure that we are writing efficient SQL. Using a small data set like this example will not show us any noticeable difference, but processing thousands or millions of records can yield major performance gaps between efficient and inefficient SQL. In procedures and views with complex joins and processing, inefficient SQL can cause exponential performance degradation.
Using IS NOT NULL in a WHERE clause can negatively impact performance. It forces the optimizer to do a full table scan, rather than an indexed read for the column used in the WHERE clause. So, in our current example using WHEREFixedAlphaVal <> ” would also be more efficient. (NOTE: be careful! If you really do want to process blanks then this approach won’t give the correct result set).
Let’s take this a step further. Using not equal (<>) is not the most efficient for this scenario. When trying to process <>, query optimizers in some databases will sometimes build the execution plan by splitting the less than (<) and greater than (>) portions into separate clauses. Why make the optimizer do this extra work if we don’t need to? If we look at our query again, the less than (<) is superfluous and we can get exactly the same result set by using > ” instead of <> ”
SELECT ExampleID, FixedAlphaMethod, FixedAlphaVal FROM Example WHERE FixedAlphaVal > ”
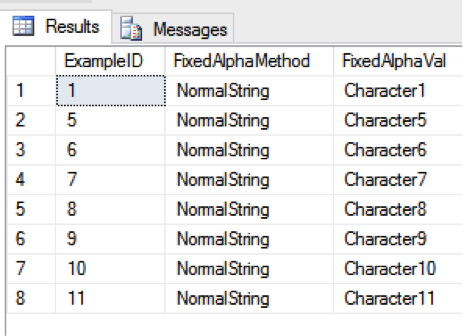
It also allows the query engine to do a positioned read rather than a discrete comparison of each value. On some DBMS platforms this can be a tremendous performance improvement.
Use Case 2 – VARCHAR Column
The CHAR vs. VARCHAR data types is another issue that can cause a lot of confusion. On many platforms, inserting a value into a CHAR column will pad the string with trailing blanks. This can cause inconsistent query results. This usually manifests itself when trying to do a join, where one column is CHAR and the other is VARCHAR. Ensure you are trimming the strings and CAST to the same datatype to overcome this problem. In the context of this example, the behavior was the same as with the CHAR column.
SELECT ExampleID, VarAlphaMethod, VarAlphaVal FROM Example WHERE VarAlphaVal IS NOT NULL
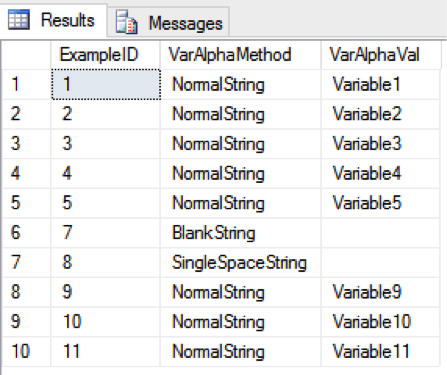
As we can see, the result set includes the records with the blank and single space in the VarAlphaVal column.
Again, we can use either of the <> or > comparisons in the where clause to get the result set that removes the NULL and blanks as follows:
SELECT ExampleID, VarAlphaMethod, VarAlphaVal FROM Example WHERE VarAlphaVal <> ”
SELECT ExampleID, VarAlphaMethod, VarAlphaVal FROM Example WHERE VarAlphaVal > ”
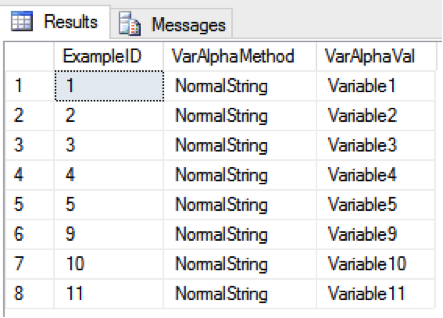
Use Case 3 – INTEGER Column
Lastly, let’s examine a situation where the column is numeric. There are similar instances where different applications may populate the column differently. Some may use NULL because there isn’t a value, while others may default to 0 (zero). Assuming we are interested in meaningful, positive values, we can see that different variants of the WHERE clause give us different results (with varying performance), so we want to use the best alternative for our use case:
If we use IS NOT NULL, we are picking up the 0 (zero) valued rows, since it is a valid data value whereas NULL is the absence of a value.
SELECT ExampleID, NumMethod, NumVal FROM Example WHERE NumVal IS NOT NULL
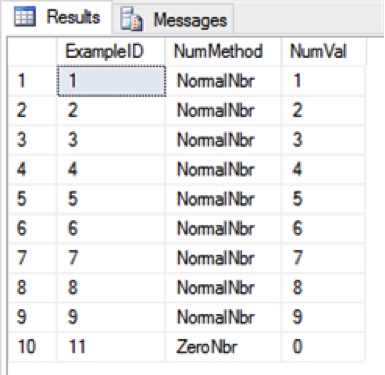
Records with ExampleID of 10 and 12 are filtered out due to the NULL in NumVal.
If we want to exclude 0 (zero) values as well, we would use:
SELECT ExampleID, NumMethod, NumVal FROM Example WHERE NumVal> 0
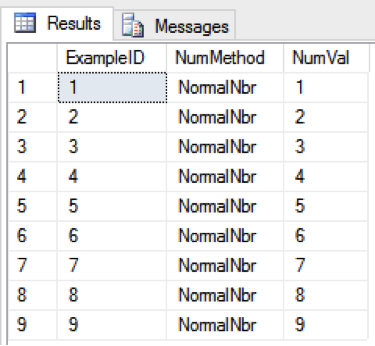
Note of interest: In SQL Server we can get the same result by comparing to blank:
SELECT ExampleID, NumMethod, NumValFROM Example WHERE NumVal > ”
For numeric columns, the same performance considerations exist as for alphanumeric. Using IS NOT NULL in a WHERE clause can negatively impact performance. It forces the optimizer to do a full table scan, rather than an indexed read for the column used in the WHERE clause.
Summary
Understanding your specific database platform is crucial in determining the behavior induced by NULL vs. blank columns. Understanding your environment is also critical, as the data within that database may not have been populated in the manner you expect. You want to ensure that you write efficient SQL. To test it adequately, you need to use test data sets with thousands or even millions of records. It is also imperative to use proper indexes over the columns used in WHERE clauses, so that the query optimizer builds efficient access plans, keeping table scans to an absolute minimum. Depending on the platform, a NULL will usually be included in an index. However, using IS NOT NULL in a WHERE clause for that same column will force a table scan, which foregoes the efficiency of the index. Using the > or <> comparisons will generally yield the desired result set with greater efficiency, since the indexes are used.

{kind=link}