 The idea for Hackolade came from Pascal Desmaret’s personal need for a data modeling tool specifically for NoSQL databases. He searched the web and couldn’t find one that would satisfy his needs. He tried really hard to use existing tools! After all, all he wanted was to give his credit card number and download the right tool to do his job. The last thing on his mind was to embark on a new entrepreneurial adventure.
The idea for Hackolade came from Pascal Desmaret’s personal need for a data modeling tool specifically for NoSQL databases. He searched the web and couldn’t find one that would satisfy his needs. He tried really hard to use existing tools! After all, all he wanted was to give his credit card number and download the right tool to do his job. The last thing on his mind was to embark on a new entrepreneurial adventure.
There is a short explanation for why I was not satisfied with the existing tools, and there’s also a long answer below. The short answer is simple and can be seen (almost) by this one picture:

Periodically, Yelp awards prize money for interesting insights out of the analysis of their sample dataset. In the past, it has led to hundreds of academic papers. As the data is provided in JSON format, any NoSQL document database is a good candidate to store the data, and several blogs explain how to use MongoDB for the analysis. Using a data modeling tool to discover the data structure should be a great first step.
The only problem is that the Yelp dataset is made of just five data collections in MongoDB, yet the traditional ER tools finish their reverse-engineering process by showing these stats:

If there are just five collections in the database, you would expect only five entities in the Entity Relationship diagram— one for each of the collections in MongoDB, right? Instead, it’s something more like this:

Besides the more orderly aspect, this second diagram is also a lot easier to understand. It is a closer representation of the physical storage, displaying nested JSON sub-objects as indentations rather than as separate boxes (entities) in the ERD— in a manner similar to what you would find in a JSON document
And if you’re developing or maintaining your own model, it is a lot easier to deal with the entire JSON structure in just one view, including all nested objects (arrays and sub-documents), than if you need to open a new entity for each nested object (like in the following picture representing the structure of just one of the Yelp documents).

No wonder some developers of NoSQL applications don’t want to hear about data modeling, especially when the diagram that is supposed to help understand and structure things is actually more confusing, and doesn’t look anywhere close to the physical documents being committed to the database! A more natural view would be this one:

To manage objects metadata, Hackolade provides a second view —a hierarchical tree view— similar to the familiar XSD tree:

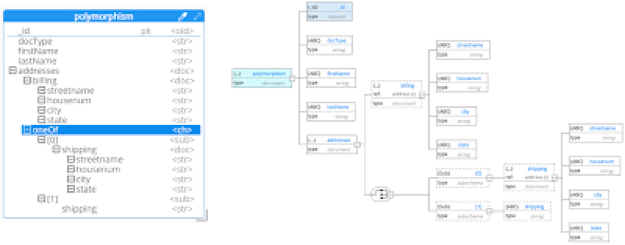
One of the great benefits of this tree view is the handling of the polymorphic nature of JSON, letting the user define choices between different structures.
The reason for the difficulty with traditional ER tools in representing JSON nested structures is simple and logical: they were originally designed for relational databases, and their own persistence data model (how they store objects and metadata) is itself relational.
As a user, if you use a traditional ER diagramming tool for the data modeling of relational databases and apply it to a NoSQL database (MongoDB in this case), you are constrained by the original purpose and underlying data model of the tool itself. And while it is quite creative of the vendor to make its tool “compatible” with MongoDB, it is clearly an afterthought and it ends up not being very useful.
Just like how NoSQL databases are built differently than relational databases, data modeling tools for NoSQL databases need to be engineered from the ground up to leverage the power and flexibility of JSON, with its ability to support nested semi-structured polymorphic data. And to do that, the modeling tool cannot store its own data in flat relational tables!
Hackolade stores data model metadata in JSON (actually in JSON Schema, the JSON equivalent of XSD for XML), making it easy to represent JSON structures in a hierarchical manner that is close to the physical storage of the data. And the user interface was built according to the specific nature and power of JSON. Therefore, Hackolade is the pioneer for the data modeling of NoSQL and multi-model databases!
Longer Answer
The challenges in modeling JSON with tools made for flat database structures are as follows:
- Similarity between JSON and its GUI representation:
- Structure
- Sequence
- Indentation
- Clarity of complex models
- Meaning of relationship lines
- Representation of polymorphism
Structure
Contrary to conceptual modeling, JSON is a representation of the physical storage in the database as implemented, or intended to be implemented, in a NoSQL database (or multi-model DBMS.) Entity Relationship modeling theory has worked wonders for the normalization of relational databases, in its ability to represent conceptual, logical, and physical models in diagrams. But ER theory has to be stretched for the purpose of NoSQL because of the power and flexibility provided by embedding, denormalization, and polymorphism.
If the ERD is going to represent conceptual entities, then each embedded object in a JSON document could (maybe sometimes) be represented by 1 box in the ERD. However, we’re dealing here with physical storage, and therefore in such case, it is preferable to have:
1 JSON document = 1 entity = 1 box in the ERD
That way, the contextual unity of the document can be preserved.

Sequence
Preserving in the ERD the sequence of the physical document helps legibility and understanding.
As a consequence of splitting embedded objects from the main document, the ERD drawn with traditional tools makes things harder for the observer by not displaying the same sequence of fields in the diagram as in the physical JSON.

On the other hand, Hackolade’s views (ERD and the hierarchical tree) both respect the physical sequence of the document:
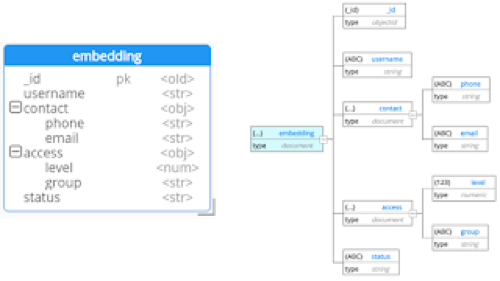
Indentation
Indentation of embedded objects in JSON (arrays and sub-documents) helps legibility. As another consequence of splitting embedded objects from the main document, the ERD drawn with traditional tools does not preserve the indentation of JSON that would make it easy to read.
Clarity of Complex Models
Take a look at an example of the structure of a real document from a real customer (with some field names obfuscated on purpose):

The ER rendering of such a document by a traditional ER tool would result in so many boxes that it becomes nearly impossible to work with. And that’s with a single document. Imagine what an ERD would look like for an application comprised of dozens of such collections.
Meaning of Relationship Lines
Yet another consequence of splitting embedded objects from the main document, the ERD drawn with traditional tools displays relationship lines of different nature:
- Relationships resulting from the embedding of objects
- Traditional foreign key relationships (even though we are dealing with so-called ‘non-relational’ DBs, there are often implicit relationships in NoSQL data)
This makes for a confusing picture as true foreign key relationships are hard to distinguish from embedding relationships (even though there can be dashed and solid lines).
All this does not leave much room for a useful 3rd type of relationships: those issued from denormalization (i.e.; redundancy of data which is useful in NoSQL to improve the read performance of the database).
Polymorphism
One of the great features of JSON, also applicable to NoSQL and Big Data, is the ability to deal with evolving and flexible schemas, both at the level of the general document structure, and at the level of the type of a single field. This is known as “schema combination” and can be represented in JSON Schema with the use of subschemas and the keywords: anyOf, allOf, oneOf, and not.
Let’s take the example of a field that evolves from being just a string type to becoming a sub-document, or with the co-existence of both field types. Traditional ER tools have a hard time dealing graphically with subschemas (let’s be frank, they’re simply unable to deal with it), whereas with Hackolade:
Conclusion
Besides the above demonstration, Hackolade has many other advantages. For example, reverse-engineering is done through a truly native access to the NoSQL database, not via a “native” 3rd-party connector (is that not a contradiction in terms?) Hackolade provides useful developer aids such as the ability to generate sample documents and forward-engineering scripts specific to each supported NoSQL database vendors. And Hackolade supports other NoSQL vendors than just MongoDB: DynamoDB, Couchbase, Cosmos DB, Elasticsearch, Apache HBase, Cassandra, Google Firebase and Firestore, with many others coming up.
Data is a corporate asset, and insights on the data is even more strategic. Sometimes overlooked as a best practice, data modeling is critical to understanding data, its interrelationships, and its rules.
Hackolade lets you harness the power and flexibility of dynamic schemas. It provides a map for applications, a way to engage the conversation between project stakeholders around a picture. Proper data modeling collaboration between analysts, architects, designers, developers, and DBAs will increase data agility, help get to market faster, increase quality, lower costs, and lower risks.
