
This column focuses on
1) two classes of graph databases – Property and Semantic
2) how Property and Semantic graph databases differ and
3) graph database common use cases. It is important to understand what Property and Semantic graph databases are before understanding where they differ.
Property
Graph Database
A Property
Graph Database is an attributed, multi-relational graph where:
- The edges are labeled
- Both vertices and edges can have any number of key/value properties associated with them
- Graph databases are more complex compared to the standard single-relational graphs
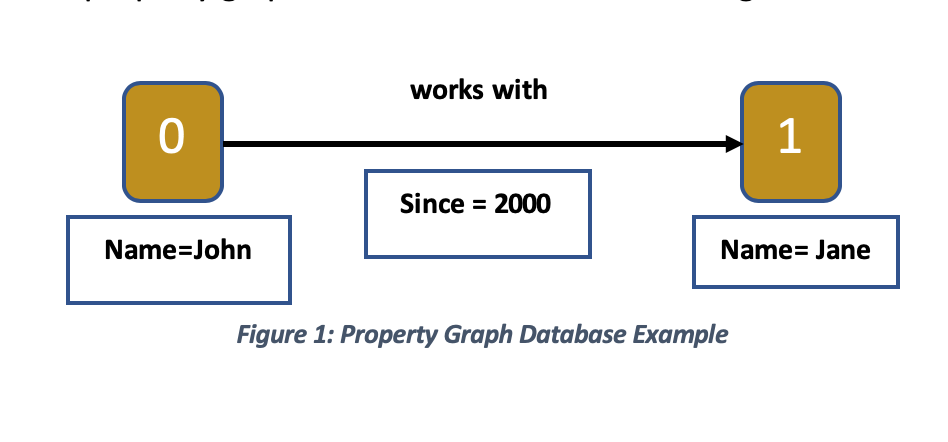
Each node
represents a single person who is connected with others through relationships.
Figure 1 shows:
- John works with Jane
since year 2000.
Semantic
Graph Database
- A Semantic Graph Database is a Triplestore:
- It is made up of semantic triples in the form of Subject-Predicate-Object.
- It is capable of integrating heterogeneous data from many sources.
- It is a type of NoSQL graph database.
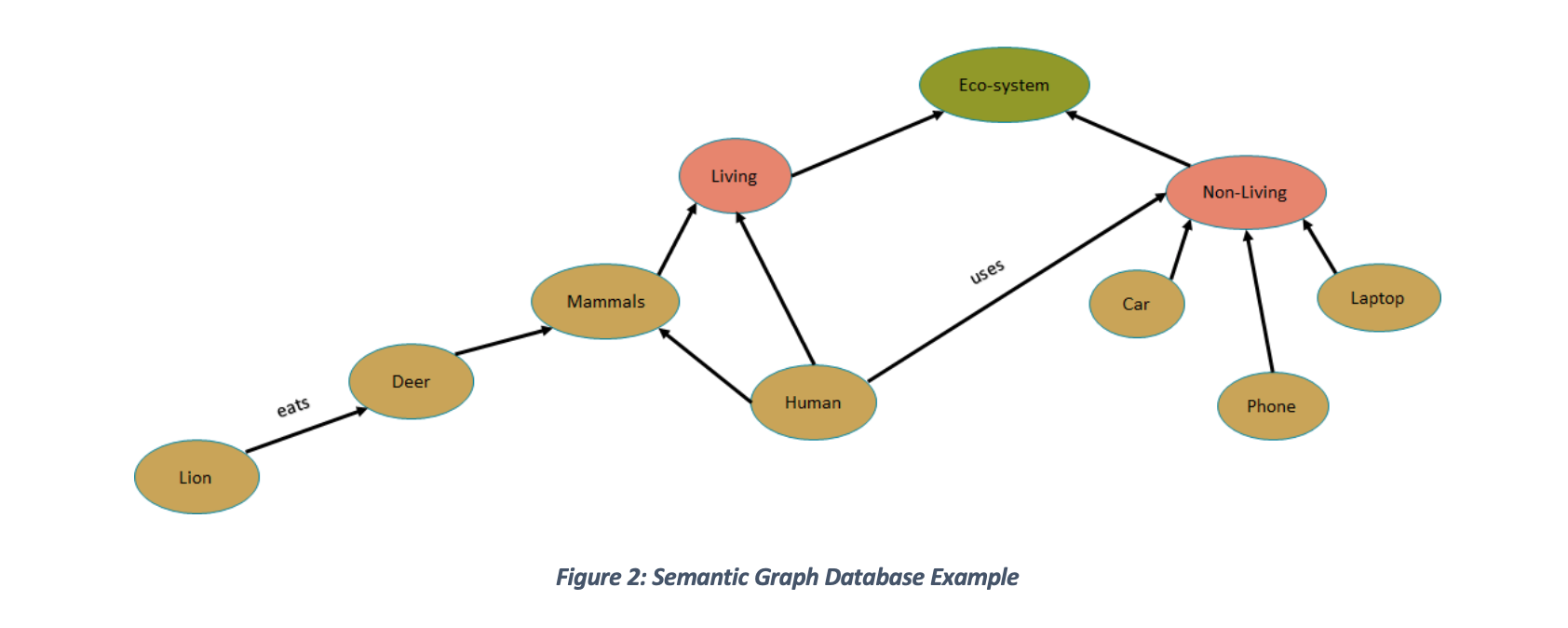
Figure 2 shows:
- Lion eats Deer
- Deer is a Mammal
- Human is a Mammal
- Mammals are Living things
- Car is a Non-Living thing
- Phone is a Non-Living thing
- Laptop is a Non-Living thing
- Human is not a Non-Living thing; but a human uses
Non-Living things - Living and Non-Living things are part of Eco-System
Property vs
Semantic Graph Databases
The following section highlights areas where Property and Semantic graph
databases differ.
Standards Adherence/Compliance
- Property graph
databases use emerging Ad Hoc standards which apply to structure, properties, metadata,
etc. - Semantic graph
databases use W3C standards.
Schema
- Property graph
databases are schema-based with the need to define all types, properties, and
values upfront. - Semantic graph
databases are schema-less.
Query Language
- A query language
is still in development for property graph databases. Cypher is an evolving
query language for property graph databases, provided by Neo4j. - Full query
languages like SPARQL are similar to SQL with query optimization and are
available for semantic graph databases.
String Length
- Property graph
databases avoid long strings. - Semantic graph
databases are optimized to deal with arbitrary length strings (Example: URLs).
Disparate Data
- Property graph
databases require effort to share disparate data. - Semantic graph
databases are built to link disparate data.
Linked Open Data
- It is very hard
to read linked open data when using property graph databases. - Semantic graph
databases are built to read linked open data.
Graph
Databases Common Use Cases
One of the biggest data challenges faced in
today’s world is not about how to handle disparate data but how to connect data
using the technologies available. Graph databases provide one solution for this
challenge. Here are some common use cases:
Social Networks
Social networking databases tend to store and
pull information that is connected but also not uniform. These databases are
focused more on building a network among users (“objects”) rather than neatly
storing data in tables. The relationships among those users can be friends,
friends of friends, coworkers, common interests, etc. which in turn make
everything even more complex.
Metadata Management
Graph databases offer the fundamental solid
foundation and processes needed to manage and gain benefits from enterprise
data. It is robust at modelling the complex relationships between
mission-critical data assets and answering data stewards’ questions. When the
business is in need of answers, it also needs to know the level of confidence
in the information that is provided. Graph databases enable a way to quickly
explore and measure trust to understand the data asset with confidence. Graph
database technology has proven effective in mastering information
across hundreds of data sources and it continues to gather pace as part of a
robust metadata management strategy.
Fraud Detection
Enterprise organizations rely on graph
database technology to strengthen their fraud detection capabilities to prevent
a variety of financial crimes like credit card fraud, insurance fraud, etc.
Traditional fraud prevention measures used to focus on individual data points;
however, today’s fraud presentation measures are improved by using graph
technology to look beyond individual data points to the connections that link
them.
Network Analysis
The size and complexity of the network requires
a configuration management database more powerful than anything relational
databases have to offer. A graph database enables the connection of many
monitoring tools at once to gain critical insights into the complicated
relationships between different networks. The size and complexity of today’s networks
requires a configuration management database (CMDB) that is more powerful than
relational databases can support. Using graph database technology in network
analysis will tremendously help in troubleshooting, impact analysis, and
scheduling for planned outages.
Recommendation Engines
Real time
recommendation engines are critical to the success of any online business. Making
accurate, timely recommendations in real time takes advantage of a customer’s
browsing history and recent product purchases. Graph databases are the key
technology in real time for connecting masses of consumer and product data to
gain insight into customer needs and product trends. This is one of the
significant areas where graph databases outperform relational and other NoSQL
data stores.
This column has introduced you to the two types of graph databases and their common use cases.
In the next column in this series, we will address:
- Graph database challenges
- How to identify the right
graph database
This quarter’s column was written by Anandhi Sutti with THE MITRE CORPORATION. Anandhi has over 20 years of experience in Data Management. She has helped public and private sector clients to oversee and strategize the implementation of Data Management and Business Intelligence (BI) projects. She has strong expertise in Business Intelligence, Data Analytics, Data Modeling, Data Architecture and Data Strategy along with architecting complex systems and applications using a Software Development Life Cycle (SDLC). Anandhi has a master’s degree in computer applications and bachelor’s degree in mathematics.
Approved for Public Release, Distribution Unlimited. Public Release Case Number 20-0029
The author’s affiliation with The MITRE Corporation is provided for identification purposes only and is not intended to convey or imply MITRE’s concurrence with, or support for, the positions, opinions, or viewpoints expressed by the author. ©2020 The MITRE Corporation. ALL RIGHTS RESERVED
