
Many software developers distrust data architecture practices such as data modeling. They associate these practices with rigid and bureaucratic processes causing significant upfront planning and delays. As a result, they believe that, if they follow such practices, it will take them a long time to finally deliver solutions that may be obsolete by the time they reach customers. They would rather code first, and deliver quickly in small iterations, in the name of agile principles.
Some believe that the data model will somehow emerge without requiring a conscious schema design focus. Because of these beliefs, they may not think that data modeling is important. The emergent approach often delivers a product that initially provides the functionality required by the customer, which is a good start. But, without explicit concerns for the sustainability of data structures, it can potentially deteriorate data and application quality.
Sucking Agility out of Agile Projects
Granted, we all know cases when the development of “enterprise models” got in the way of getting things done. As explained in the History of the Agile Manifesto by their authors, their motivation was to restore a balance:
“We embrace modeling, but not in order to file some diagram in a dusty corporate repository. We embrace documentation, but not hundreds of pages of never maintained and rarely used tomes. We plan but recognize the limits of planning in a turbulent environment.”
Today, the agile movement is torn between 2 extremes, and organizations are struggling to achieve the desired balance. On one hand, quick-and-dirty approaches have demonstrated that without design and planning, there is chaos, mistakes, and rework, resulting in missed objectives and exploding Total Cost of Ownership. On the other hand, “fake agile” is sucking agility out of agile projects.
There is no magic formula to delivering projects. Only people make a difference between success and failure.
Applications Come And Go, While Data Stays
People in successful agile projects understand how data and applications complement each other. Applications are required to process the data, to turn it into something that organizations can use. But the useful life of software is typically between 3 and at most 5 years, whereas data stays around. Data is shared across multiple applications, and has a much longer shelf life. Some of it may get stale or even perishable, it evolves and moves around, but it greatly outlives software applications. It is therefore critical to store data correctly, which brings us to the subject of data modeling.
Data modeling is the process of creating a blueprint to help organizations design data systems for their unique needs. A data model is a visual representation of the data structure in information systems like databases, data warehouses, or data exchanges. Data models are easy to understand by humans, using visual entity-relationship diagrams.
Data models are used to generate schemas, which serve as technical “contracts” between producers and consumers of data, or agreements on the structure of data being exchanged. Schemas are powerful and amazingly helpful to keep data stable and healthy. The purpose of data models is to help humans design technical schemas for databases and data exchanges.

Click to view larger
A blueprint is used by building architects to document the requirements for the construction, discuss the vision with the owners, and finally discuss execution details with engineers and contractors. While you can sketch a basic plan on the back of an envelope if you’re building a shed in your backyard, you would never consider building a house or a skyscraper without using drafting software to create precise and detailed plans.
The reasoning is the same for databases and data exchanges. Different stakeholders must be consulted and involved, and countless details must be thought through to identify the optimal design. A data model is an ideal medium to involve the different stakeholders and settle the important facets of the data structure for performance and durability.

Click to view larger
The design, evolution, and maintenance of schemas have increasing importance as the number of schemas has exploded with event-driven architectures, micro-services, REST APIs, data pipelines, self-service analytics, and data meshes. Additionally, digital transformations and ever-changing customer needs mean that applications evolve at increasing speed, with a direct effect on transformations and adjustments to databases and data exchanges.
JSON Looks Easy, But Beware of Traps
JSON— which is used in NoSQL document databases, REST APIs, websites, and increasingly in relational databases— looks easy and gives a false sense that its design can somehow emerge organically. When designing a JSON document schema, it is critical to think in terms of access patterns and application queries, to co-locate related data into a single atomic unit through denormalization.
At least, with relational databases, DDLs and the rules of normalization provided guardrails and predictability. But none of that’s available with JSON, particularly if the integrity of the JSON payload is not enforced by JSON Schema. The convenience of being able to commit a document of any structure without constraints sounds great… until you have mission-critical transactions relying on the accuracy of the data. Schema-less sounds great… until you have to work with the data.
Agile and Polyglot Data Modeling
Back to the question of balance. Neither an architectural blueprint nor a data model are end goals, but they are powerful means to successfully deliver the final product. The exercise of creating a data model must be an enabler to design, evolve, and maintain the schema, and facilitate the work of developers as they build their application around data, which is critical to operations, self-service analytics, management decisions, machine learning, and other artificial intelligence.
Legacy data modeling tools have worked well in the past for relational databases, monolithic applications, and waterfall development. But modern stacks now include cloud and NoSQL databases, JSON in RDBMS, REST APIs, Avro for Kafka, Parquet in data lakes, etc. Software architectures now leverage micro-services and events. Source code control has been migrated to Git providers. Development must be agile and is deployed using DevOps CI/CD pipelines.
All these factors mean that data modeling must evolve and adjust to today’s technology and practices, using developer-friendly tooling integrated with the ecosystem. A modern data modeling tool integrates with the repository tools preferred by dev teams (Git and related platform hubs) so they can co-locate data models and schemas with application code. It must fit in the lifecycle management of applications and DevOps CI/CD pipelines and tools. And it must speak the schema languages of the different technologies of application modernization and cloud migrations.
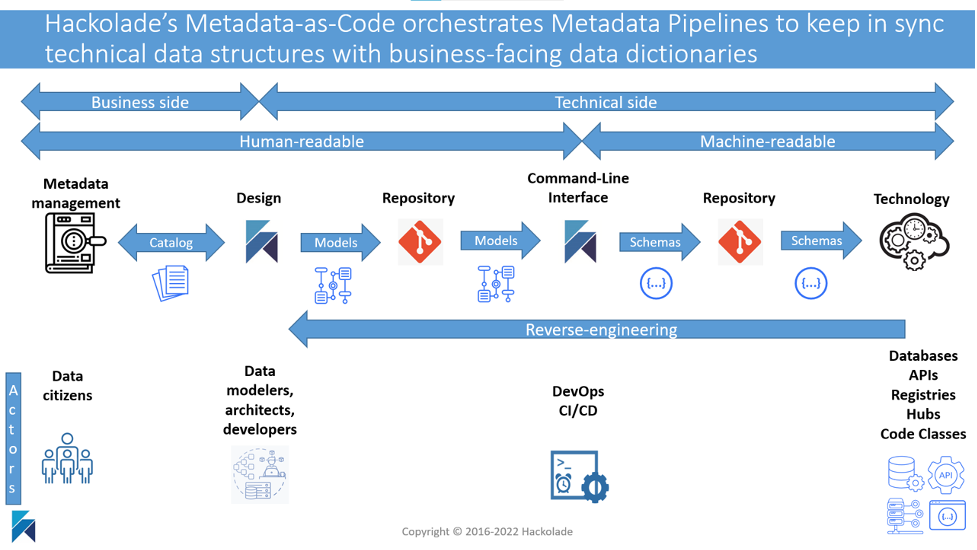
Click to view larger
It is also required to share with business users the meaning and context of these constantly evolving technical structures. There must be automation to update data catalogs and dictionaries so that data citizens can accurately query the data and then draw insight in a self-service analytics context.
Conclusion
It turns out that data modeling is even more important today than it was previously. With today’s technology stacks, schema contracts are used everywhere between producers and consumers of data. Plus, these schemas constantly evolve to meet the changing needs of customers.
While there may have been an imbalance in the past, the Agile Manifesto did not intend to create an imbalance in the opposite direction. On the contrary!
It is time to restore the balance again and leverage agile data modeling to deliver working software and quality data that users can find, understand, and turn into information, insight, and decisions.
