
The terms Data Mesh and Data Fabric have been used extensively as data management solutions in conversations these days, and sometimes interchangeably, to describe techniques for organizations to manage and add value to their data. In this article, we intend to clarify these terms and explain the overlaps and differences to enable the readers to each approach.
Data Fabric
Data Fabrics arose as a solution to bring efficiency and governance to data integration and access problems when the numbers of data sources, integration methods, and consumers outgrew traditional methods. The term “data fabric” first appeared in the mid-2000s, attributed to former Forrester research Noel Yuhanna,1 and Wombat Financial Software launched the first fabric solution “Wombat Data Fabric” in 2007.2 In its current use, a data fabric is a metadata-driven configurable technology solution for connecting data users to organizational data in a cohesive and self-service manner. Specifically, data fabric solutions deliver capabilities in the classical areas of
- data discovery and access,
- data transformation and integration pipelines,
- governance, and lineage
Data Fabrics are not necessarily domain-driven and can be domain-agnostic without any impact to functionality. Domains can be any specific realms of data that have specific processing needs, like different lines of business in an organization, or even different data categories like financial data, etc. For example, in a vast organization, there could be autonomy in developing a fabric per domain or have multiple fabrics based on different needs in the organization, with each fabric responsible for complete data lifecycle of the data it manages including storage, archival and removal. In a small organization, one fabric could integrate data from all domains and manage the lifecycle of all the data. In the former, data governance would be federated with each fabric solution providing governance capabilities for the data it manages, whereas in the latter, data governance would be centralized for all data managed in the solution at the organization-level.
Data Fabrics are customizable technology solutions that can be engineered by putting technology appliances together; they enable business requirements in organizations and provide access to managed data, as depicted by a basic solution in Figure 1 below. Once the sources of data have been identified and ingested, the data is cleansed, harmonized/transformed, tagged and appropriately stored in data and metadata repositories. Consumers may search the metadata to identify data to match their needs in a catalog and may use the visualization and analytic tools provided by the technology, or APIs may be used for integration with other software.
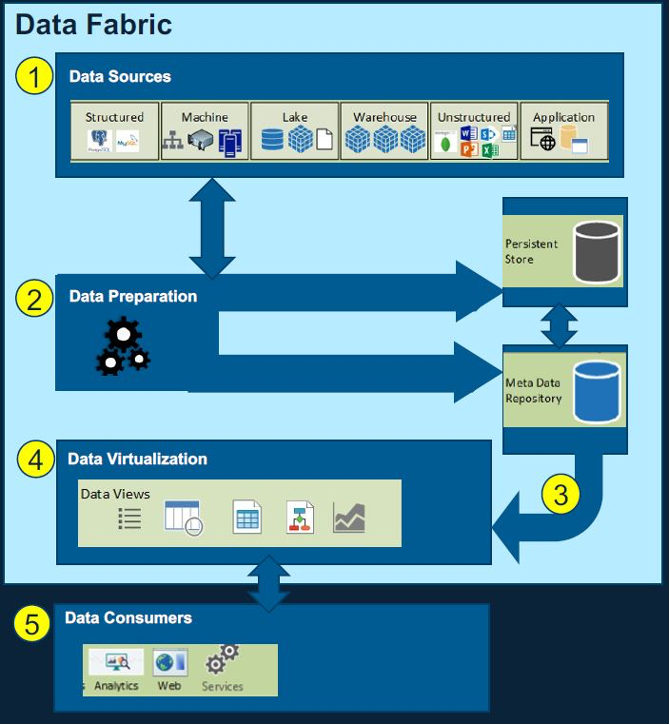
Click to view larger.
A comprehensive data fabric solution might include much more than the traditional methods and contemporary tools. It may be designed to apply machine learning to how data is being used by collecting active metadata — action-oriented metadata that is continuously collected from logs and usage statistics about data through the entire data stack. As shown in Figure 2 below, data sources and associated logs are mined for metadata and a knowledge graph is generated. This depicts how data dependencies impact business relationships and how and where data influences their mission activities. AI/ML algorithms applied to the active metadata can highlight which data is used most often or suggest alternative sources to increase timeliness or trustworthiness of data used in decisions. And as data and metadata continues to become integral to business operations, active metadata monitoring in a data fabric can provide dashboards to quickly highlight when data delivery is compromised so DataOps teams can repair data pipelines with minimal impact on business operations. Thus, metadata is actively engaged in data delivery mechanisms and operations; it doesn’t idly sit in catalogs.
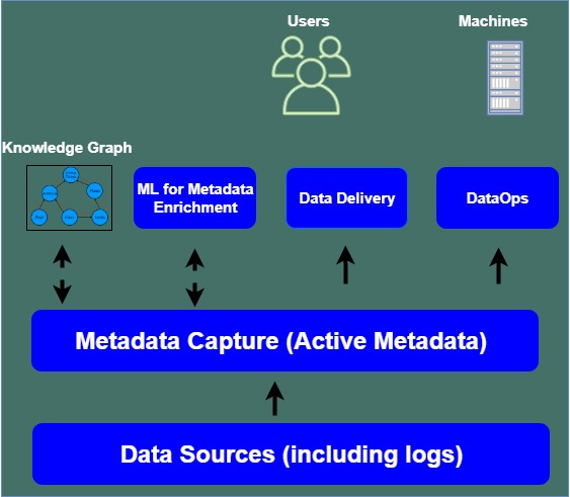
Click to view larger.
There can be a whole spectrum of solutions between what is depicted in Figure 1 and Figure 2, and still be considered a data fabric solution. In other words, data fabric solutions can be custom built, complete COTS, or a hybrid of the two, so long as they facilitate business operations by integrating data from several sources for analytics and provide data access to users.
Data Mesh
The data mesh concept was first introduced by Zhamak Dehghani, who created initial principles and concepts of the data mesh in her May 2019 report How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh3 which were updated in December 2020 report titled Data Mesh Principles and Logical Architecture.4
Her idea emerged in response to the increasing complexity of data management, especially in large enterprises. A Data Mesh applies a decentralized architectural style to manage heterogeneous data environments, where the types and sources of data are abundant and each data source has specific integration, maintenance, and governance requirements. It is based on the premise that data is best owned and managed by the teams that know their data well. It is centered around the concept of data products, where the life cycle management of a data asset is delegated to teams that curate and build the asset to satisfy data mesh rules for quality and sharing. Data Meshes are domain-driven, with the understanding that a domain team (who are subject matter experts for the domain) may develop one or more data product(s) they own and curate, and they are best suited to manage and govern that data. As mentioned earlier, domains can be specific realms of data that have specific processing needs, like geo-spatial data, sensor feeds, or similar unique structures — making a data mesh more about teams and processes that build and exchange data products seamlessly and less about technology. For instance, there are no Data Mesh appliances that can be bought and customized for the organization’s business requirements, but organizations can build Data Mesh architectures by developing teams that own data products and administering a set of standard services that enable the exchange of data products between producers and consumers in a safe, interoperable, and reliable manner.
Mesh Data Products and their metadata requirements must be clearly defined to reduce the friction between producers and consumers. Products must be discoverable, addressable, accessible, and secure. Each data product requires a universal resource locator (URL) to be reachable and accessible for consumers to use it. Products must be managed, versioned, trustworthy, understandable, and created from reliable data sources. Analytical products can contain analytical tools and algorithms which should again be versioned and managed. Products must also be capable of accepting feedback and comments from consumers.
Data/metadata standards and formats are broadly recommended for enterprise interoperability, however extensions and custom additions are left to the purview of the producers and consumers. As long as the product meets the minimum viable product definition set by the enterprise, the products will be validated at the enterprise level. Mesh Data Services are also defined by the enterprise for producers and consumers to register, search, access and validate data products.
The diagram Figure 3 below shows a generic data mesh architecture. Each box at the four corners of the diagram represents a node, or a data domain, which can produce and/or consume data products. Products are curated in their local data environments before they are published at the enterprise level. Each node manages its own data and may use a local catalog for data discovery and governance of data within its platform. The center of the diagram shows the enterprise hub which include an enterprise catalog to register, publish and discover data products, and enterprise mesh services. They provide common data-product related services (like registering, searching, retrieving data products) for seamless operation of the data producers and the consumers.

Click to view larger.
A data mesh is fundamentally a model depicting how the governance and technology used to manage data is organized into domains and shared within the enterprise for end user discovery and use.
Similarities and Differences
As a reminder:
- A data fabric seeks to build a single, virtual management layer atop distributed data sources.
- A data mesh encourages distributed groups of teams to manage data as they see fit, albeit with some common governance provisions.
Both solutions provide a method of finding and gaining access to data that meets a user’s criteria, and a data fabric may actually be included in a data mesh. But because one is technology and one is a conceptual architecture, there are many more differences. Table 1 below highlights these differences in selected categories:
Table 1
| Data Fabric | Data Mesh |
| Originated when organizations struggled to manage multiple ungoverned data solutions. | Originated when organizations were overwhelmed with the administration of complex data environments. |
| Domain agnostic: can have one fabric solutions to manage, process, and share all data across an enterprise. | Domain specific, based on domain teams knowledgeable in their domains, who manage and curate their products. |
| Data-Product agnostic: any relevant source of data may be ingested, and any relevant data feeds may be created. | Data-Product based: products are managed and have a well-established lifecycle. |
| Customizable technology solution that enables business requirements in organizations and provides access to managed data. | Not a technology solution, but rather an agreed-upon set of rules for publishing and accessing managed data products. |
| Data Governance is generally centralized, or systems based. | Data Governance is federated, with each domain managing its data products and pipelines. Computational governance (such as automated checks on product integrity) may be included. |
| An optional data catalog enables search, discovery and access to organization datasets. | A central data catalog is required to enable search and discovery of the organization data products. |
| A management and visualization layer will generally be part of the solution. | Once set up, producers and consumers can operate autonomously. Visualization is available when data products are integrated with rest of the data at the consuming end. |
Factors for Successful Implementations
As many of us know from experience, the technology is the easy part of implementation. So rather than address the needs of storage and network capacity, we address the surrounding capabilities that keep the technology working seamlessly in this section.
Understand your business needs and data culture – Implementing either a data fabric or data mesh requires that the organization understands data, its value, and how it can help answer business questions. The precondition for success requires that either a mesh or fabric implementation include steps to prepare the organization. This could mean providing a “data 101” type of data literacy course so everyone can be comfortable with the basic data vocabulary and how they contribute to the solution. It may also require identifying the early adopters from the business side of an organization and having their use cases as the first to be fully realized in either a fabric or mesh solution. This pre-work not only prepares them to be successful data producers and consumers but can also generate insights to the expected user experience that must be delivered for acceptance.
Documentation in a catalog – A current data problem is that organizations don’t know what data they have. In the Federal Government, this problem is significant enough that the Evidence Act directed agencies to build a comprehensive catalog of data assets! As noted, while an enterprise catalog is a “must” for the Mesh architecture, data fabrics definitely benefit from a catalog. This cannot simply be a technical feature, but must be monitored to ensure sufficient metadata is provided by registered entries and that the quality of metadata leads to appropriate inclusion in search results. User feedback in the catalog is a useful feature for crowd-sourcing the value of datasets but may introduce bias — organizations can mitigate this risk through training, regular review of ratings, and promotion of new high quality datasets to increase their use.
Design of governance – For many organizations, “governance” is a loaded term that can deter people from participating in a solution. For that reason, it is important to understand the various approvals that a given source of data is already subject to and only add new governance when necessary. By its very nature, the data mesh requires a precise governance model to enforce rules that assign a level of trustworthiness for the data consumer to rely on. Should computational governance be implemented, much of the burden is automated and seemingly behind the scenes but it still must be managed and maintained by people who understand the needs of data consumers and the broader organization. With no governance, even the best planned technology solution may be rejected by the consumers because the quality and volume of the contents do not meet expectations.
Conclusion
Knowing your organization and the readiness of personnel to both use and support any data solution is the most important part of selecting whether a data fabric or data mesh is the right choice. Small or single-mission organizations may be able to manage a single enterprise data fabric because the complexity of access is small. The complexity of data dependencies and interactions can also inform whether a single fabric can work, or where the domain lines can be appropriately drawn for a data mesh influenced solution. A data fabric-based platform can be one of the domain nodes or an over-arching data mesh architecture, as long as it conforms to the mesh principles in the enterprise. If there are limited personnel available to support, a data mesh concept might work well by “outsourcing” the responsibilities of managing quality and content to the domain experts.
Enterprises may benefit from a Mesh architecture where the components continue to manage their data sources, formats, pipelines, and product lifecycles while exposing products that cross the domain/component boundaries. The exposed data products need to be managed for interoperability requirements and mesh standards, while much of the other internal data activities can continue on their own schedules. By conducting a review of your organization against the characteristics of these two models and the factors for successful implementation, you can begin to craft a plan for implementing the model that is a best fit for you.
References
https://www.wherescape.com/news-press/four-pillars-to-building-a-successful-data-fabric-for-your-enterprise/
https://www.openfabrics.org/downloads/Media/IB_LowLatencyForum_2007/IB_2007_03_Wombat%20Financial%20Software-DoNotUse.pdf
https://zeenea.com/everything-you-need-to-know-about-a-data-fabric/#:~:text=A%20data%20catalog%20is%20the,point%20for%20a%20Data%20Fabric.
https://www.gartner.com/smarterwithgartner/data-fabric-architecture-is-key-to-modernizing-data-management-and-integration
About the Authors:
Savithri Devaraj is a Lead Data Engineer in MITRE Labs, with extensive experience in data architectures and data engineering. She has worked with several agencies in setting up their data architectures and governance programs. Her expertise in AWS cloud architectures, data management and interoperability have helped her sponsors identify challenges, knowledge gaps and policy considerations in implementing programs of record. Her current focus is data governance in the U.S. Army as it steers towards a data-centric organization.
Andrea Heithoff is a MITRE Principal Architect for Data Management Innovation who has advised Federal CDOs, CIOs, and Chief Architects for over 15 years. Since the passage of the Evidence Act of 2018, she has assisted new CDOs implement plans that balance technology innovation with effective organizational design and stakeholder engagement, so they are best equipped to lead their organizations use of data as a strategic asset. She currently works in MITRE Labs with a focus on operational data management in the U.S. Army.
‘Approved for Public Release; Distribution Unlimited. Public Release Case Number 23-1164
‘The author’s affiliation with The MITRE Corporation is provided for identification purposes only, and is not intended to convey or imply MITRE’s concurrence with, or support for, the positions, opinions, or viewpoints expressed by the author.’©2023 The MITRE Corporation. ALL RIGHTS RESERVED.
