
In the ever-evolving world of data management, the terms “data lake,” “data warehouse,” and “data lakehouse” are frequently discussed. Each of these solutions offers unique benefits and serves different purposes within an organization. This article aims to define these terms, highlight their differences, delve into their histories, and provide examples to help readers understand which solution might be best suited for their needs.
Additionally, we will explore how these data management solutions can be applied to working with knowledge graphs, along with recent trends and practical applications.
Data Lake
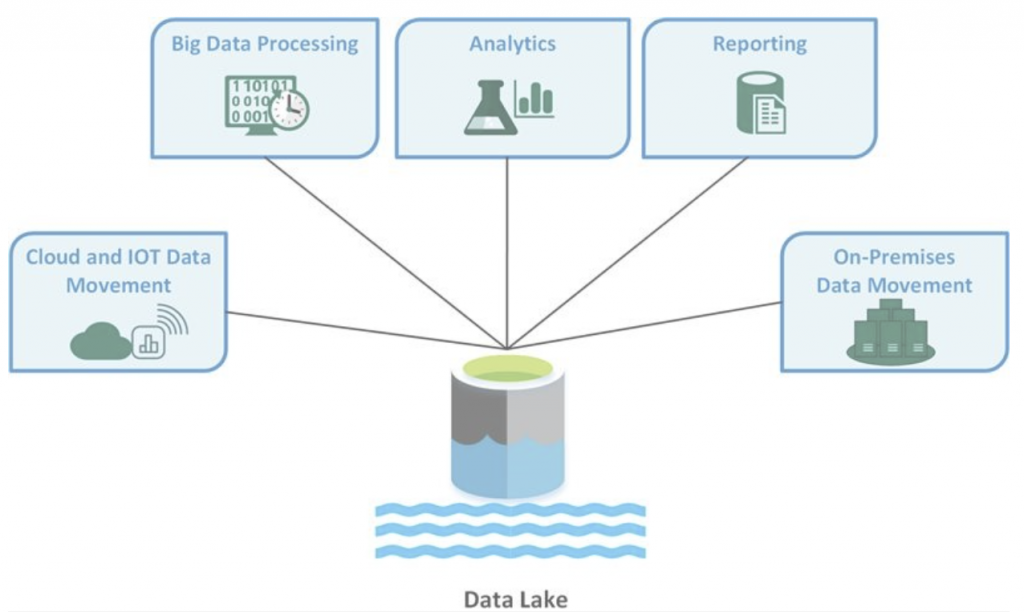
A data lake is a centralized repository that allows you to store all your structured and unstructured data at any scale. You can store your data as-is, without having to first structure the data, and run different types of analytics — from dashboards and visualizations to big data processing, real-time analytics, and machine learning. The concept of a Data Lake emerged in the early 2010s as organizations began to struggle with the limitations of traditional data warehouses in handling large volumes of unstructured data. The term “data lake” was popularized by James Dixon, then CTO of Pentaho, who described it as “a large body of water in a natural state, in contrast to a bottled water (data mart) or a cleaned-up water reservoir (data warehouse).” The rise of big data technologies like Hadoop further propelled the adoption of data lakes, providing a scalable and cost-effective solution for storing vast amounts of raw data.
Characteristics
- Storage: Raw, unprocessed data in its native format.
- Schema: Schema-on-read, meaning the schema is applied when the data is read.
- Flexibility: Highly flexible, supports a wide variety of data types and formats.
- Cost: Generally lower cost for storage, as it uses cheaper storage solutions.
Challenges
- Data lakes depend on the querier to understand the data or supply metadata. Because they use a schema-on-read approach, the querier must understand the “hidden” schema.
- Without proper metadata or understanding, Data lakes can become “data sewers,” where retrieving meaningful data becomes difficult. Data modeling always must be done — whether before, during, or after querying. For data lakes, this modeling is done at query time, which can complicate data retrieval.
Data Warehouse
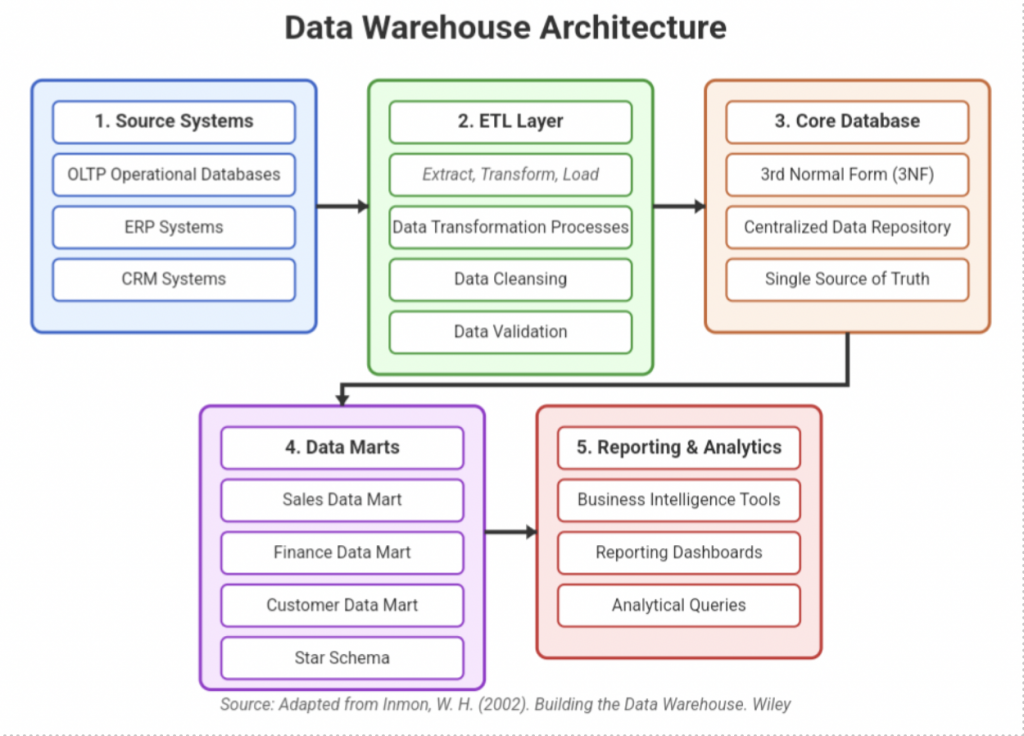
A data warehouse is a centralized repository for storing large volumes of structured data from multiple sources. It is designed for query and analysis rather than transaction processing. Data is cleaned, transformed, and cataloged to support business intelligence activities, such as reporting and data analysis. The concept of a data warehouse dates to the late 1980s and early 1990s, with pioneers like Bill Inmon and Ralph Kimball contributing significantly to its development. Inmon is often referred to as the “Father of the Data Warehouse” and defined it as a “subject-oriented, integrated, time-variant, and non-volatile collection of data to support decision-making processes” (Corporate Finance Institute). The rise of business intelligence and the need for consolidated, high-quality data for reporting and analysis drove the adoption of data warehouses.
Characteristics
- Storage: Structured and processed data.
- Schema: Schema-on-write, meaning the schema is defined before the data is written.
- Performance: Optimized for read-heavy operations and complex queries.
- Cost: Generally higher cost due to the need for more powerful computing resources and storage.
Challenges
- Development Time: Designing the database and creating/testing transformations can be time-consuming.
- Technology-Specific Implementations: Traditional data warehouses were mostly developed with relational databases, often consisting of a 3rd normal form (3NF) core and data marts created for specific reporting needs.
- OLTP Performance Impact: Querying directly against OLTP systems had performance ramifications for the transactional systems.
Data Lakehouse
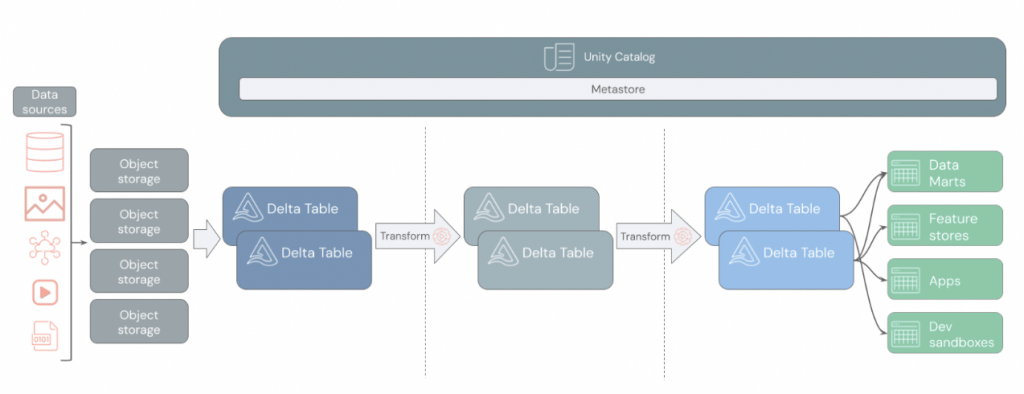
A data lakehouse is an emerging data management architecture that combines the capabilities of data lakes and data warehouses. It aims to provide the data management and governance features of data warehouses along with the low-cost storage and flexibility of data lakes. The concept of a data lakehouse emerged in the late 2010s as organizations sought to address the limitations of both data lakes and data warehouses. Data lakes, while flexible and cost-effective, often lacked the data management and governance features required for reliable analytics. Data warehouses, on the other hand, were optimized for structured data but struggled with the volume and variety of modern data. The term “data lakehouse” was popularized by companies like Databricks, which introduced architectures that combined the best features of both data lakes and data warehouses (Databricks Documentation).
Characteristics
- Storage: Can store both structured and unstructured data.
- Schema: Supports both schema-on-read and schema-on-write.
- Flexibility and Performance: Offers the flexibility of a data lake with the performance and management features of a data warehouse.
- Cost: Aims to provide a cost-effective solution by combining the best of both worlds.
Challenges
- Complexity: Lakehouses must balance the simultaneous storage of unstructured data while maintaining query performance.
- Integration: Questions arise about whether the same data exists in both formats (structured and raw) and whether the querier can query either format.
- Emerging Technology: As a newer architecture, organizations may face challenges in adoption and implementation.
Differences
The primary differences between these data management solutions lie in their data structure, schema approach, use cases, and cost.
- Data Lakes: Store raw data in its native format and use a schema-on-read approach, making them ideal for big data analytics, machine learning, and data exploration. They are generally more cost-effective for storage.
- Data Warehouses: Store processed and structured data using a schema-on-write approach, optimizing them for business intelligence, reporting, and structured data analysis, albeit at a higher cost.
- Data Lakehouses: Bridge the gap between these two solutions by providing better data management and governance features than traditional data lakes, along with improved performance for analytics and querying. They support both structured and unstructured data and offer a cost-effective solution with the performance benefits of data warehouses.
Feature Comparison
| Feature | Data Lake | Data Warehouse | Data Lakehouse |
| Data Structure | Raw, unprocessed | Structured, processed | Both structured and unstructured |
| Schema | Schema-on-read | Schema-on-write | Both schema-on-read and schema-on-write |
| Use Cases | Big data analytics, ML, data exploration | Business intelligence, reporting, structured data analysis | Combines use cases of both data lakes and data warehouses |
| Cost | Generally lower | Generally higher | Cost-effective, combines benefits of both |
| Flexibility | Highly flexible | Less flexible | Flexible |
| Performance | Variable, depends on processing tools | Optimized for complex queries | High performance |
| Data Management | Limited governance | Strong governance | Strong governance |
Applications with Knowledge Graphs
Knowledge graphs represent a network of real-world entities — objects, events, situations, or concepts — and illustrate the relationship between them. Integrating knowledge graphs with data lakes, warehouses, and lakehouses can significantly enhance data management and analytics capabilities.
- Data Lakes and Knowledge Graphs: Data lakes can store vast amounts of raw, unstructured data, which can be used to build and enrich knowledge graphs. By leveraging the flexibility of data lakes, organizations can ingest diverse data sources, including text, images, and sensor data, to create comprehensive knowledge graphs that provide deeper insights and support advanced analytics.
- Data Warehouses and Knowledge Graphs: Data warehouses, with their structured data and optimized query performance, can be used to store and manage the structured data that forms the backbone of knowledge graphs. This structured data can be queried and analyzed to extract relationships and build knowledge graphs that support business intelligence and decision-making processes.
- Data Lakehouses and Knowledge Graphs: Data lakehouses offer the best of both worlds, providing the flexibility to store unstructured data and the performance to manage structured data. This makes them an ideal platform for integrating knowledge graphs. Organizations can use data lakehouses to store and process the diverse data required to build knowledge graphs while ensuring efficient query performance and data management.
Conclusion
Understanding the differences between data lakes, data warehouses, and data lakehouses is crucial for organizations looking to implement an effective data management strategy. Each solution has its unique strengths and is suited for different use cases. By evaluating your organization’s specific needs and data requirements, you can choose the solution that best aligns with your business goals.
Author Biography
Kyle Costello is an information systems engineer at the MITRE Corporation. He has domain knowledge in assisting the Department of Defense, particularly on Air Force-related projects. He has a Bachelor of Science in Data Science from Worcester Polytechnic Institute (WPI) and is pursuing his Master’s in Analytics at Georgia Tech.
‘The author’s affiliation with The MITRE Corporation is provided for identification purposes only, and is not intended to convey or imply MITRE’s concurrence with, or support for, the positions, opinions, or viewpoints expressed by the author.’
