
In today’s digital systems, vast volumes of information are produced daily. However, simply collecting large amounts of data is not enough. That data must be reliable and well-structured to serve any real purpose. This is where validation and engineering come in; they help ensure information is accurate, consistent, and useful before it is applied to decision-making or automation.
As information systems become more advanced, maintaining quality through human effort alone becomes more difficult. To manage this complexity, automated frameworks and intelligent tools are increasingly being used to support the process.
Why Unreliable Data Is a Risk
If data is missing, duplicated, out of order, or stored incorrectly, the entire system using it can be compromised. In some cases, this can lead to incorrect decisions, delays, or even legal issues. Systems depending on such data for example, those making predictions or controlling resources must be built with care and discipline.
Problems that arise from unvalidated inputs include:
- Mismatches between systems
- Incomplete or missing entries
- Irregular formats
- Broken transformations
- Errors in aggregation
Each of these can quietly damage confidence in the information being used and, in some cases, go unnoticed until much later.
The Process of Validation
Validation involves checking data at multiple points. It might begin with source validation ensuring fields are in the right format or that important information is not missing. Later, during processing, additional checks may be run to confirm that the data has been interpreted and stored correctly.
Types of validation include:
- Format checks (e.g., dates, numeric fields)
- Logic checks (e.g., a person cannot be listed as both employee and customer in the same record)
- Range and consistency checks (e.g., values staying within acceptable limits)
By embedding these checks early and often in the system, quality issues can be identified before they reach critical business systems.
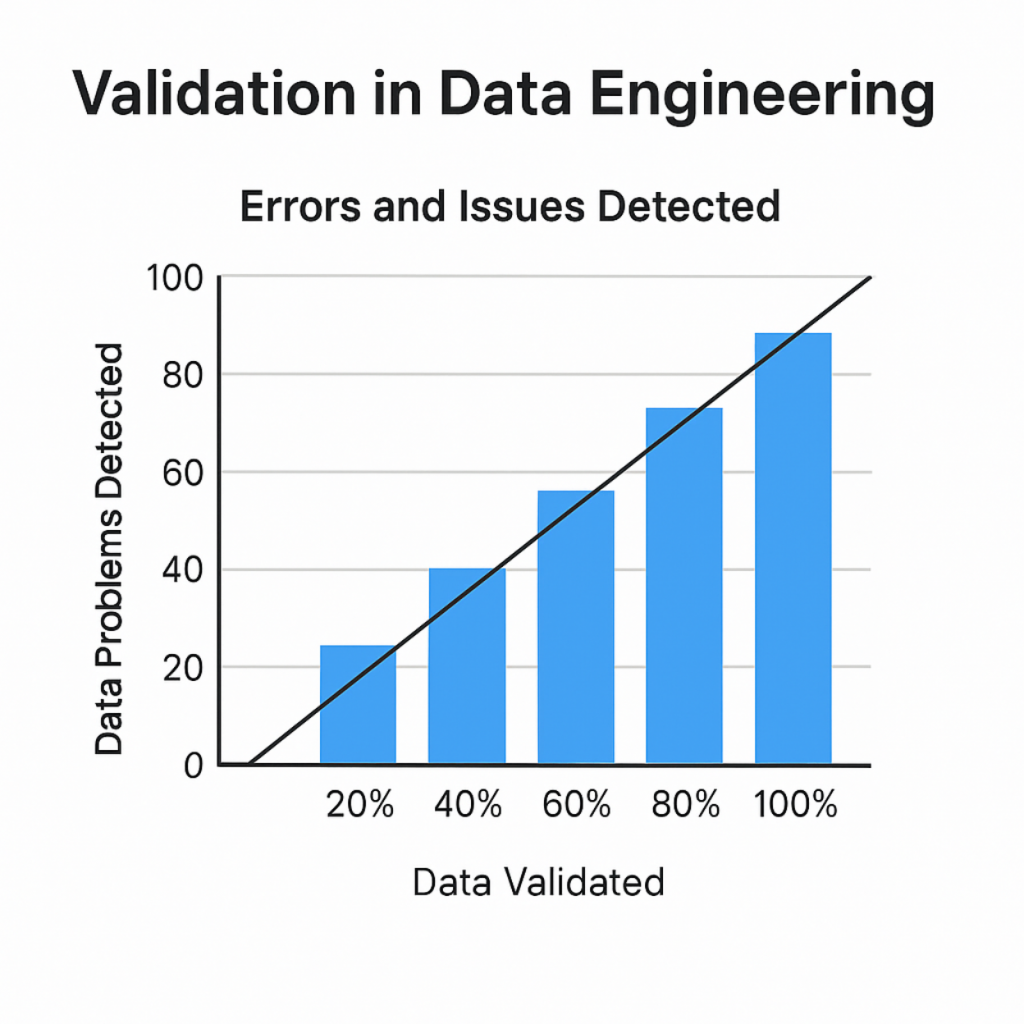
What Graphs Tells Us:
- Insight: The more thoroughly you validate your data, the more problems you uncover.
- Implication: Partial validation may miss significant issues; full validation provides a clearer picture of data quality and risks.
Role of Data Engineering
Data engineering involves building pipelines and systems that allow information to move from one place to another. These systems collect, transform, and store data so that others such as analysts, application developers, or decision-makers can work with it.
Modern engineers often work across different types of data: text, images, event logs, and more. They must manage how the data flows, how it’s stored, how quickly it moves, and how it connects with other tools.
This work includes:
- Structuring storage for scale and performance
- Managing delays or data loss
- Ensuring consistency across environments
- Supporting both real-time and historical access
A well-built system doesn’t just work once it continues to work as the data grows, changes, and evolves.
Use of Automation and Learning Systems
Because the amount and complexity of data are always increasing, many teams are now using learning-based tools to assist with quality control. These tools look for changes in expected behavior, identify unusual patterns, and sometimes even suggest new checks.
Some areas where this can be useful include:
- Alerting when formats shift over time
- Finding outliers that deviate from normal patterns
- Detecting drift in source feeds or application use
These tools do not replace human judgment, but they do help people focus their time where it’s needed most.
Applications in Various Sectors
Reliable data systems are useful in many areas of work:
- In medicine, to make sure patient records are correct
- In finance, to prevent fraud or meet reporting requirements
- In logistics, to track goods accurately
- In customer service, to personalize communication
Each field has its own rules and expectations, but the underlying need for clean, accurate information is shared across all of them.
Building Reliable Systems
To create lasting value, teams should focus on:
- Defining clear rules for acceptable data
- Testing inputs and outputs at all stages
- Monitoring systems regularly
- Making results visible and explainable
- Working together across teams to understand both the technical and business aspects
These practices reduce waste, build trust, and make future growth easier to manage.
Final Thoughts
Good systems rely on good data. Without careful validation and strong engineering, even the most advanced applications can deliver poor outcomes. As systems become more automated, keeping humans involved, especially in design, review, and monitoring, is essential. Tools can help, but human responsibility remains at the center.
Data quality is not just a technical task. It is a shared responsibility that underpins how well any organization can learn, act, and grow.
