
Cataloging items has been a process used since the early 1900s to manage large inventories, whether it be books or antics. In this age, data management has become a necessary routine.
Organizations have started to uncover large sets of data in the form of Assets typically used for analysis and decision making. Understandably, Data Catalogs are becoming a core component of modern-day data management.
Organizations with successful Data Catalog implementations have experienced substantial improvement in the speed and quality of data analysis, allowing a smooth and effective engagement of Data Analysts and Data Scientists for accurate and profitable decision making. But, for implementing a data catalog on the data within an organization successfully, one needs to understand what data catalog actually means, why it is needed and how it works. We will go through each of these topics to better understand the usage and execution of data catalogs within your organization.
What is a Data Catalog?
A Data Catalog can be defined as a collection of metadata, typically used for data management with query access to help analysts and other data users find the data that they need. It serves as an inventory of available data within the organization and provides access to evaluate the fitness of data for its intended use. With all its benefits, the effectiveness of the Data Catalog depends on the central capacity to provide a collection of metadata.
Why Data Catalog?
In the age of big data and business intelligence, data catalogs are becoming the essence of metadata management, helping and guiding data users better understand their data and its importance. A data catalog focuses on data assets and connects the data sets within the assets with its related metadata to help the users of the data understand it better.
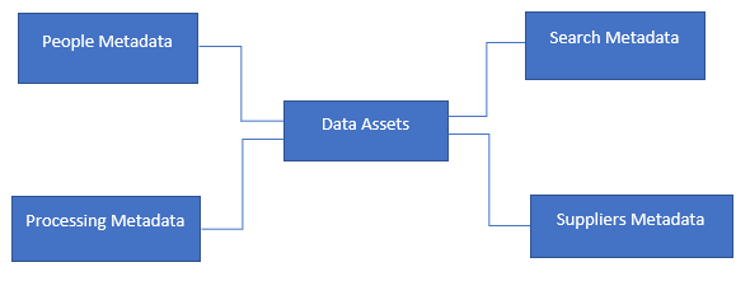
Click on image to see larger.
Data Assets can be files, databases, or applications that data users need to find and access to generate insights for decision making. They could reside in data lakes, warehouses, or any other shared data resource.
People Metadata provides information on those who work on data assets. They could be consumers, curators, SMEs, or stewards.
Search Metadata supports tagging and searching for data within the assets using keywords to help people find the data.
Processing Metadata describes the transformations and derivations data goes through and how it is managed through its lifecycle.
Supplier Metadata describes data acquired from external sources providing insights on the sources and subscription and licensing constraints.
How Does Data Catalog work?
A data catalog includes many features and functions related to the core capabilities of cataloging information – collecting the data about data that identifies and describes the inventory of usable information. With so much of usable and sharable data available, it becomes impractical to attempt cataloging as a manual effort. Automated discovery of data assets on the go has become essential. The use of techniques such as artificial intelligence and machine learning for metadata collection and tagging becomes important to get maximum value from data cataloging using minimal manual effort.
Apart from capturing metadata for the data, other essential features and functionalities captured by a data catalog include:
Data Search: This capability includes a search of facets, keywords, and business terms. Business terms search capabilities are especially essential for non-technical users of data. The search capability can be organized by relevance and frequency of use, in turn providing the search results for the most relevant information.
Data Evaluation: Choosing the right data asset depends on the ability to evaluate their suitability for the particular use case without needing to import the data first. An important feature of data evaluation includes the capability to preview data assets, see all associated metadata, access user ratings and reviews, and view data quality information.
Data Access: The data access should be a seamless user experience with the data catalog implementing the access protocols directly or using access technologies. Data access functions include protection for security, privacy, and compliance of sensitive data.
Different capabilities can be explored based on the type of data catalog. The different types of data catalogs are utilized based on metadata and its importance to the organization.
Selecting the Data Catalog Based on the Use of Metadata Categories
Different Data Catalog Tools rely on the collection and use of a combination of metadata categories.
- Technical Metadata Management Catalog: A technical metadata management data catalog captures and provides structural information about the source and target data for integration development and ETL. This data catalog mostly relies on:
- Structural metadata (e.g. data element names, data types, and data element sizes),
- Supplier metadata (e.g. data asset demographic information),
- Processing metadata (e.g. data transformations and data derivations),
- Query metadata (e.g. business glossary and data element definitions).
- Data Lineage Tool: A data lineage tool combines:
- Supplier metadata such as the data owners,
- The details of the original sources from which the data asset is manufactured,
- Data production details with the data transformations, data derivations and the structure of the data processing pipelines from the processing metadata.
- Machine Learning Data Catalog: A machine learning data asset inventory blends the practical aspects of the production of the data asset from:
- Structure metadata (data element names, lengths, types),
- Processing metadata (data transformation, derivations, and pipeline process maps),
- Query metadata, including the semantic details and historical usage, to produce a searchable data catalog.
- Data Portal: The objective of a data portal is transparency, and a data portal typically scans and then previews accessible data assets. To enable this, data portals combine:
- Structure metadata,
- Supplier metadata,
- Query metadata.
to provide a listing of available data assets, data element metadata, information about the different data sources, and data asset demographics such as a number of records or size in bytes. It also provides a means for browsing a subset of data instances within the data asset.
- Data Governance Tool: Data governance tools ensure data usability by monitoring data quality and alerting data stewards when issues emerge. These tools have evolved from metadata repository products to incorporate the definition of data quality policies and support operational data stewardship processes and procedures.
- Data Security and Protection Catalog: These types of data catalogs draw on:
- User metadata to collect information about the different users, groups, and roles,
- Different classifications pulled from the query metadata,
- Data protection directives from governance metadata to enable the definition and implementation of runtime data protection and security policies.
All solutions consist of multiple types of metadata consumed and utilized, and no single catalog tool has the capabilities to satisfy the extent of the need for a data catalog solution.
Identifying the right data catalog solution requires attention to the organization’s most critical user scenarios and requirements, such as:
- The scope of enterprise-wide business glossaries and data definitions,
- Using metadata standards and defined procedures for collecting, documenting, and sharing the different classes of metadata,
- Inferring data models and lineage through reverse-engineering,
- Attentive data curation that establishes standardized processes for data asset configuration and preparation,
- Simplifying intelligent query processing so data consumers can quickly find what they need and enabling data previewing for those seeking data assets to answer ongoing and emerging business questions,
- Engineering, implementing and monitoring data pipelines and the processing stages through which data streams for end-user reporting and analytics,
- Operational data governance and assessing existing data governance and stewardship roles and their responsibilities,
- Data validation and quality assurance for data trust,
- Collaboration among data producers and different data consumers,
- Data content classification and how it relates to data organization and data protection.
Evaluating Data Catalog to Be the Best Fit for the Organization
While not every data catalog tool necessarily fits all enterprise needs, data catalogs help establish information preparedness to respond and recover from crisis demands. Another important aspect is considering a data catalog solution is evaluating it for business needs.
- Classify members of the data stakeholder community: A data catalog’s value directly corresponds to how well it meets the needs of different data communities. Identify who the data producers and data consumers are and classify them according to their specific needs in terms of producing and/or consuming the different kinds of metadata.
- Define Use Cases: Monitor and evaluate the needs of data consumers and the processes they employ to satisfy their needs. Defining these requirements will help understand and identify the data intelligence capabilities desirable in the data catalog solution.
- Prioritize Capabilities: Based on the requirements evaluation, repeated requests for desirable capabilities will help create organizational priorities.
- Establish Evaluation Criteria: As desired capabilities emerge, consider how a Catalog Tool will be assessed in terms of supporting those capabilities. Metrics and measures need to be established for evaluation.
- Evaluating Tool Options: Instead of selecting a one-size-fits-all product, look for a combination of technologies that are suited for the organization’s use cases and expectations.
- Proof of Concept: Execute a few projects that will not just enable the organization to review the tool capabilities but also raise awareness of its value.
- Accessibility: Use the evaluation criteria for determining the overall best solution that meets the needs of the data community.
Benefits of Data Catalog
The benefits of Data Catalogs are reflected in the value and quality of metadata and the capabilities unlocked from it. The analysts observe the best benefits of data cataloging in their analysis. It provides business and data analysts complete visibility into the existing data, their content, and their quality and usefulness.
Quality and efficiency of analysis are substantially improved, and organizational analysis capacity increases without an increase in resources as analysts don’t need to spend nearly as much time in finding, sorting, and cleaning data. Some of the most common benefits that can be readily observed by the implementation of the data catalog:
- Improved data efficiency,
- Improved data context,
- Reduced risk of error,
- Improved data analysis.
Automating Metadata Management through Data Catalogs helps users understand the accurate flow of data across the organization. It provides insight on data movements and helps build, improve, and monitor systems and the data consumed by them. In today’s age, Metadata Management and Cataloging have become a necessity to facilitate Data quality, security, and accuracy.
