For years we have been reading about the statistics of failed, challenged, and successful IT projects. These statics have been popularized in the Chaos Reports from the Standish Group.
Table 1 presents these statistics over time. There has been significant discussion about these statistics, and an excellent article about the validity and reliability of the statistics, The Rise and Fall of the Chaos Report Finding, is located at: http://www.cs.vu.nl/~x/chaos/chaos.pdf. While the article is interesting and does clearly point to issues related to the clarity, precision, and accuracy of the Standish Group’s statistics, the article offers no help in figuring out why projects are successful, challenged, or failed. Or, more importantly, how to proactively prevent challenges or failures.

The article does, however, hint at one of the reasons for the dramatic Standish statistics. This is provided in the Rise and Fall article’s Figure 1. This figure shows that as the project nears completion, the estimates of the time and cost to achieve completion become more accurate. It’s tempting here to say, “Well duh!” Unsaid, however, is that what is more likely known is a clearer picture of the true requirements of the effort and the amount of work, expressed in terms of costs, that will be required to conclude the result. If more accurate requirements and amount of work were better known at the very start of the project, it’s likely that the Standish statistics would have a much larger percent in the Success column and dramatically smaller percents in the Challenged and Failed columns.
Analogously stated as to whether you, as a person, are either alive or dead, the article advocates a more refined strategy on identifying exactly when you become dead, but nothing on why you are dead or how to prevent your death. The article’s solution to this problem seems merely to add more columns in between success and failure, and to move some of the percents amounts among these new columns. While that might be more interesting, it certainly does not help. After all, if you’re dead, you’re dead. What’s really needed is knowing why you are likely to die, and taking steps to prevent your impending death.
What this TDAN article does, in contrast, is focus on the reasons why your project may be successful, challenged, or failed. Even more importantly, this article also sets out a strategy to dramatically move the failed and challenged percent amounts to success.
Key to understanding the Chaos statistics is the Knowledge Worker Framework. That is because through the Knowledge Worker Framework you can understand where the errors occur, which work products must be deficient, and the downstream implications. This framework has been addressed indirectly in the following TDAN articles:
- 1998, Database Objects
- 1998, Resource Life Cycle Analysis
- 2000, A New Paradigm for Successful Acquisition of Information Systems
- 2003, Frameworks, Meta-Data Repository & the Knowledge Worker
- 2003, Comprehensive Metadata Management
- 2007, Information Systems Development
- 2008, Data Semantics Management
In reviewing these articles, it became clear that the following has never been presented:
- The Knowledge Worker Framework itself.
- The allocation of GAO IT errors in terms of percents.
- A summary of the key IT processes that need to be accomplished to address these errors.
- The cross reference between key work products and the Whitemarsh Metabase System that can capture, store, interrelate, report, and evolve these work products.
- A cross reference between key work products as it relates to a comprehensive data architecture reference model.
This article not only presents these topics, but also it sets out strategies to both prevent IT business information system failure and to prevent challenges from occurring in the first place.
Knowledge Worker Framework
The Knowledge Worker Framework was created in response to a challenge. During a consulting assignment in the middle 1990s, a high-level manager indicated that a very popular framework looked promising and should be implemented across his IT organization. I indicated that it was too bad that the framework was not able to be successfully implemented, as specified, despite its obvious surface validity. He immediately asked why it wasn’t able to be implemented. I responded by relaying how an attempt to implement the popular framework in a Federal Agency had failed for the following reasons:
- The various work products referenced in the cells were not sufficiently detailed.
- There was no cell-to-cell integration so that the work products could reference and employ each other.
- There was no framework-based detailed business information system methodology that could be followed.
- Metrics didn’t exist across the work products that would support accurate effort estimates.
- There was no project, business function, or enterprise-wide work product database that could be used to capture, store, review, evolve, and accelerate other work products.
Almost immediately, the high-level manager asked that a valid framework be created and that its draft be delivered in a few weeks.
Rather than develop a new framework out of whole cloth, the framework was created inductively from an existing business information system’s development methodology that had been time-tested and evolved for the prior 15 years. The methodology was fundamentally data-centric; had very detailed work steps; formally defined work products that were non-redundant, integrated, and interoperable one with the other; contained detailed metrics for work product estimation; and was supported by a multi-user work-product database that enabled work product capture, interrelationship, reporting and evolution within projects, enterprise-functions, and across the enterprise itself.
The framework was set within the context of the knowledge worker as opposed to the manufacturing process worker. Hence, its name is the Knowledge Worker Framework. The overall architecture of the Knowledge Worker Framework is set out in Table 2. The architecture of the framework consists of six rows and six columns.

Table 2: Overall Architecture of Knowledge Worker Framework
The rows (that is, the levels) are essentially the same as the Zachman Framework. The six columns are divided into four sets: Mission, Machine, Interface, and Man. The Mission column of work products acts as the “Holy Grail” target of accomplishment. The Machine column work products are the computer-based mechanisms of reflecting Mission accomplishment. The Man columns are the human organizations and the human functions that, through the Machine assists, reflect Mission completion. The Interface column are the events, calendars, et al that set out the interactions between the Man column work products and the Machine column work products.
Work product creation generally proceeds from left to right for Mission, Database Object, and Business Information Systems. Thereafter, work product creation proceeds from right to left, that is, from Organization to Function. Finally, the Man and Machine work products are intersected through the Interface column work products. The reason for this left-right, right-left, and then intersection sequence is simple. The apolitical work is accomplished first and is the quickest and easiest to accomplish. Thus, almost immediately there are generated work products that can be reviewed and that have real and immediate value. Thereafter, the Man column work products, which are certainly both political and style-based, are accomplished and when done are interrelated with the already created Machine column work products. Work products across all six columns are related in a many-to-many fashion. This enables non-redundancy.
Missions are expressed in the form of idealized “Holy Grails” outcomes without any hint of either who or how. That makes missions apolitical because they are not bound or constrained by any preconceived organizations and or human style-based strictures.
The first machine column, database objects, contains the work products for resource life cycles and mission-based database domains. It also contains all the traditional data models, which, in turn, also contain the appropriate processes tied to database object components. The database objects are tied to missions in a many-to-many fashion. Hence, they too are apolitical.
In the second machine column, business information systems are tied to database objects in a many-to-many fashion and exist solely to add/delete/modify the data contained in the database objects. Because business information systems are not tied to nor based upon organizations or human-based functions, they are more long lasting and are largely devoid of any constraining styles.
The first-to-accomplish man column, organization, sets out the various organizations that are engaged in the accomplishment of the missions of the enterprise. This architecture supports multiple instances of essentially the same organization. “The” right one does not have to be chosen above all other equivalent organizations.
The second man column, function, describes either specially or generally the human functions that are performed by organizations regardless of whether these functions are ultimately assisted by “machine” work products. Like organizations, there can be multiple configurations of essentially the same set of human functions. An organization may perform different styles of essentially the same function. Similarly, a given function may be performed by multiple organization. Like organizations, “the” right function does not have to be chosen above all other similar functions.
The final column, Interface, relates human functions with their business information system assists within business events and various business accomplishment calendars.
The Knowledge Worker Framework columns, as shown in Figure 1, tell a story.

The six columns are non-redundant, independent through many-to-many relationships, are integrated across the framework, and are detailed down through its rows of unfolding specification, implementation, deployment, evolution and operation.
The Knowledge Worker Framework work products captured, created, reported, and evolved across the six rows and columns of the cells are presented in Table 3.

Government Accountability Office’s (GAO) IT Errors
Shortly after the Knowledge Worker Framework was completed and presented to the high-level manager, he demanded to know why the Knowledge Worker Framework was any more valid than the one he initially asked about.
To respond to his question, Government Accountability Office reports of IT system disasters were reviewed. 13 different studies were selected mainly because they exceeded $100 million in cost. The reasons for IT failure were allocated to both the Knowledge Worker Framework and to the popular framework that was initially proposed. Only 10% of the GAO errors were addressed in the popular framework. In contrast, 100% of the errors were accounted for in the Knowledge Worker Framework. One reason for the discrepancy could be that the Knowledge Worker Framework was inductively created from an already proven and very detailed business information system development methodology. Table 4 presents the percent distribution of the GAO IT system errors across the Knowledge Worker Framework.

Table 4: Allocation of Percents of Tallied GAO IT System Errors
Several things are very interesting in this errors tabulation. First, 41% of the errors occur in the first two rows. These rows represent Requirements Analysis and Design. Fifty percent (50%) of all the errors occur after a business information system is deployed. That is, within the Business Function and Organization columns for the System through Operations rows. Third, the actual percent of errors that occur during the actual IT development effort is just 5%.
These error percents go a long way to explaining the Standish Group’s percents. If you have not successfully accomplished requirements analysis and design, how can you possibly know what is to be built, how complicated the building effort is to be, how much it will cost, and how long it will take? It’s almost a “Duh” moment to conclude that on-time and on-budget projects are accidents.
In support of the disasters that follow from these GAO errors, Mark Vreeland wrote an article for TDAN entitled, Information Management & Governance Disciplines.
While his article described the architectural and engineering disaster known to many as the Winchester Mystery House, the problems contained in the Winchester Mystery House have a direct connection to many of the IT systems described in the GAO studies. The errors, described in IT terms included, for example:
- No clear architecture design between application, technical and data architectures
- No metadata environment
- Multiple reporting tools
- Multiple enterprise resource planning (ERP) systems
- Multiple business intelligence tools
- No common data / information architecture
- Lack of standards for acquiring architecture components
- Business unit driven solutions with no consideration given to the enterprise architecture
- Incomplete architecture design for migrating data from operational environment to analytical environment
- Lack of standards for data integration
- Multiple systems for the same business function (i.e., two accounting systems, two payroll systems, multiple claims processing systems)
- No overall governance framework that encompasses the enterprise
Error Elimination through Key IT Processes and StrategiesFrom the prior sections, it was established that 41% of IT system errors occur during the first two phases of business information development. It is also presumed that errors that occur early in the cycle that go undetected have a significant impact on the overall cost of a project. A Google search produced a NASA paper that summarized a collection of studies that computed the overall increase in costs for fixing IT system errors based on when they were discovered. The NASA paper is located at: http://ntrs.nasa.gov/archive/nasa/casi.ntrs.nasa.gov/20100036670_2010039922.pdf. The table from the study is presented in Table 5.

Elimination of errors in the first the requirements and design phases will have the greatest positive benefit on project costs and expended time. A key objective then is to eliminate these errors at the earliest possible time. That would clearly be in the creation of the work products that are created within the first two rows of the Knowledge Worker Framework.
The six key processes that occur across the Knowledge Worker Framework along with the citation of their rows, columns, and GAO percents are:
-
Building and Employing Enterprise Architecture Models:KWF: Scope and Business Rows, all columns. About 41% of all GAO IT errors.
- Creating and Evolving Information Systems Plans:
KWF: System Row, all columns. About 8% of GAO IT errors. - Architecture and Engineering of Data Models:
KWF: Technology Row, database object column. Less than 2% of Errors - Performing Reverse Engineering of Legacy Systems and Databases:
KWF: Operations, Deployment, Technology and System Rows. Database Objects Column. Less than 2% of Errors - Forward Engineering Manufacture of New Systems and Databases:
KWF: Operations, Deployment, Technology and System Rows. Database Objects Column. Less than 2% of Errors - Employment Errors:
KWF: Systems through Operations Rows. Operations and Functions Columns. About 49% of Errors.
The focus clearly has to be on the first key process, Building and Employing Enterprise Architecture Models. An interesting problem, however, occurs during the development of the first two rows of work products. How do you know the work products are correct? While reviews are important, the most credible source of proof is implementation. When errors are observed during implementations, the work products of the first two rows can be corrected and the work products of the remaining rows can begin anew. A strategy to accomplish this is through iterations of:
- High level data modeling.
- Business information system generation based on the data models.
- Hands-on demonstrations with business-functional users.
- Subsequent revision of work products, high-level data models, and generated business information systems.
The work products from the first two rows provide a great assist in this effort. The database domains from the database objects column contain sufficient information to support the quick development of first-cut data models. These data models can be easily exported into a data definition language form that can be read, for example into the Clarion (www.SoftVelocity.com) business information system generator. Clarion, armed with a data model, easily and quickly generates a first-cut version of a business information system for a particular business function. The work products from the business function column provide the behavior model that can be used to electronically trim/style the generated business information system. The organizations identified in the last column provide the ready-to-review audiences.
What is being reviewed through the use of the Clarion generated business information system generations are the missions, first-cut database object tables, business information systems, and business functions. After a demonstration, feedback is obtained and the work products in the first two rows are adjusted. Since there is virtually no effort expended in the development of the prototypes, they can be discarded and regenerated. What results is from three to five evolutions of the overall architecture that is thereafter implemented. By cycling this over several months, the following benefits are manifest:
- Significantly refined mission, organization, and function models.
- Good approximations of ready-to-implement data models
- Good approximations of the type, quantity, and complexity of the ready-to-implement business information systems.
- A collection of enterprise architecture models that are at Version 4 or 5 versus an untested version 1.
These iterated work products can be used to dramatically increase the accuracy and quality of business information system implementation efforts. Figure 1 from the Rise and Fall paper shows that the forecast and actual ratios do not trend towards 1.0 until about 60% into a project. From this paper’s Figure 2, that would be about month 15 of a 30 month time line. That’s well into implementation, and by that time the majority of the funds have been expended. Worse even more, all the time and effort has been expended on a Version 1, rather than on a Version 4 or 5.

Figure 2: Traditional Business Information System Development Time Line by Phase
In contrast, Figure 3 illustrates the iterative requirements development approach. The time lines are generally the same. What is critically different is that through the traditional approach the first operating version of the system is Version 1 and through the iterative approach, the first operating version of the system is Version 5.

Figure 3: Traditional business information system development time line by phase
That will largely eliminate the 41% of the first two rows of errors. These errors are eliminated because the functional uses will be reviewing and reacting to actual business information system executions (although not production class) instead of reviewing documents and drawings.
As to the other and more significant class of errors, those that occur after the business information system is deployed, they too will be largely eliminated because these very same functional users will be interacting with the evolving system during each of the design iterations. This will give a good heads-up to those persons charged with changing the work products such as organization charts, best practices, activity sequences, procedure manuals and the like. These changes will largely be known at the end of 18 to 20 weeks during the iterative requirements approach. Under the traditional approach, these changes would not surface until about 18 months after project start.
Key Work Products and Metabase System Cross Reference
A very critical and key component of this iterative requirements approach is the existence of the metabase system and its database of work products. These work products are identified in the Table 2, Knowledge Worker Framework. The metabase system functional modules that enable these work products to be captured, reported, and updates are set out in Table 6.

Table 6: Metabase System modules with respect to Knowledge Worker Framework
| Metabase Module | Description |
| Administrative Module | The Administrative module of the metabase system supports the creation of new metadata databases. Part of the creation of a new metabase database, is the loading of default values. Included as well are the creation of users with names and passwords. These new users are mapped to metabase modules and metabase databases. This enables a level of security. The metabase administrator can terminate a user’s access to a given metabase database, and can delete a metabase user. |
| Business Information Systems | Business Information Systems are the necessary computer software systems triggered by enterprise business events instigated by functions. Business information systems are directly related to mission, organization, function, and databases. Business information systems are interrelated to each other including their calendar and business event execution schedules? Collectively, business information systems are the mechanisms that carry out the automation aspects of enterprise policy. |
| Data Element | Data elements are the enterprise facts that are employed as the semantic foundations for attributes of entities within data models of concepts (Specified Data Models), columns of tables within database models (Implemented Data Models) that support the requirements of business and are implemented through database management systems (Operational Data Models), that, in turn, are employed by business information systems (View Data Models) that materialize the database objects necessary for within the resources of the enterprise that support the fulfillment of enterprise missions. Data elements are derived through the specification of concepts, conceptual value domains, data element concepts, and value domains. Additionally, the data element model supports the definition of a full complement of semantic and data use modifiers that can be allocated to data element concepts, data elements, attributes, and columns. Because of these allocations, naming and definitions can be fully automatic. |
| Database Objects | Database Object Classes represent the identification of 1) the critical data structures, 2) the processes that ensure high quality and integrity data within these data structures, 3) the value-based states represented by these data structures, and 4) the database object centric information systems that value and transform database objects from one state to the next. Database Objects are transformed from one valid state to another in support of fulfilling the information needs of business information systems as they operation within the business functions of organizations. Database objects are encapsulated within database management systems (DBMS) so that they can be independent of any end-user environment or programming language. |
| Documents and Forms | Documents and Forms enable the structuring of both documents and forms into documents/forms, their sub-sections, and cells. Documents and Forms can be interrelated with network data structures. Both Document and Form section cells can be mapped to mission-organization-functions, and also to view columns. |
| Implemented Data Model | Implemented Data Models, are the data models of databases that are independent of DBMSs. These models, which are comprised of data structure components: schema, tables, columns, and inter-table relationships. Relationships are restricted to tables within a single schema. While each implemented database data model can address multiple concept data models from the collection of concept data models, each implemented data model should address only one broad subject. Every table column should map to a parent Attribute. Every column can be allocated both semantic and data use modifiers. There is a many-to-many relationship between the Specified Data Model and the Implemented Data Model. |
| Information Needs Analysis | Information Needs Analysis represents the identification, definition, and interrelationship of the information needed by various organizations in their functional accomplishment of missions and what databases and information systems provide this information? |
| Mission, Organization, Function and Position Assignments |
The Mission, Organization, Function, and Position Assignment module represents the identification, definition, and interrelationships among the persons who, through their positions, perform functions within their organizations that accomplish enterprise missions. Missions define the very existence of the enterprise, and that are the ultimate goals and objectives that measure enterprise accomplishment from within different business functions and organizations? Functions represent the procedures performed by enterprise organization groups as they achieve the various missions of the enterprise from within different enterprise organizations? Organizations represent the bureaucratic units created to perform through their functions the mission of the enterprise. Position Assignments represent the identification of both persons and position titles that are both interrelated and allocated to the various functions performed by organizations that achieve enterprise missions. |
| Operational Data Model | Operational Data Models, are the data models of databases that have been bound to a specific DBMSs. These models, which are comprised of data structure components: DBMS schema, DBMS tables, DBMS columns, and inter-table DBMS relationships. DBMS Relationships are restricted to DBMS tables within a single DBMS schema. While each operational database data model can address multiple implemented data models. Every DBMS Column should map to a parent Column. There is a many-to-many relationship between the Implemented Data Model and the Operational Data Model. |
| Requirements Management | The purpose of this Metabase System module, Requirements Management, is to provide:
The Requirements Management module permits recording of the characteristics of the requirements associated with the enterprise. Each requirement can be described and interrelated with other requirements. Once requirements are identified and described, they can be allocated to any of the “mapping” items above. This permits enterprises to know the requirements needed by whom within the different organizations in the performance enterprise missions. |
| Resource Life Cycle Analysis | Resource Life Cycle of Analysis identifies, defines, and sets out the resources of the enterprises, the life cycles that represent their accomplishments, and the interrelationships among the different enterprise resource life cycles. Resource life cycle nodes represent the end-state data resulting from the execution of business information systems. The end-state data is represented through database object classes. |
| Specified Data Model | Specified Data Models are the data models of concepts. These models, which are comprised of data structure components: subjects, entities, attributes, and inter-entity relationships. Relationships can span interrelate entities within multiple subjects. Each data model should address only one concept such as a person’s name, or an address, etc. These concept data models can then be templates for use in developing database models (Implemented or Operational). Every entity attribute should map to its parent Data Element. Every attribute can be allocated both semantic and data use modifiers. |
| Use Cases | The use case module enables the creation, updating, and interrelationships of detailed function model specifications. The use cases contain use case networks structures, use case events, pre conditions, post conditions, special conditions, use case facts, and use case actors. These use case components are able to be interrelated with business information systems, database table columns, and mission organization functions, and persons functioning with positions. |
| View Data Model | The View data model represents the interfacing between operational data models and business information systems. View and their view columns can be characterized as Input and/or Output. Additionally, these views can be mapped one to the other on a view column basis and processes can be specified to define any appropriate data value transformation. |
Key Work Products and Data Architecture Reference Model Cross Reference
Figure 4 provides a cross reference between the data models contained in the data architecture reference models. From this Figure, it should become very clear that data models are the ultimate “associative” entity among work products.

Figure 4: Cross reference between data architecture reference model components and business information system work products

From Figure 4 and Tables 8 and 9, it should become abundantly clear that virtually all work products are related to a number of other work products. Work on one work product clearly involves and affects others. If work products are accomplished in isolation, it is virtually assured that there will be conflicts, disconnects, redundancy, and specifications that are out of date, one with the other. Such problems complicate and possibly even cause business information system projects to fail, be late, have conflicting data, business rules, and the like. It is very likely that these types of problems contribute to the Chaos statistics.
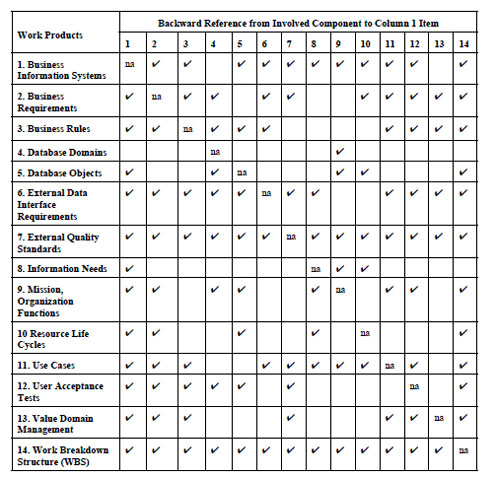
Table 9: Cross reference among work products
Our Challenge
- Adoption a framework such as the Knowledge Worker Framework that clearly identifies and defines each work product and precisely sets out their interrelationships.
- Recognition and proactively address the 90% or more of IT failure reasons that occur outside the formal domain of IT by ensuring that all IT projects holistically treat the entire spectrum of Knowledge Worker Framework work products appropriately within every project.
- Acquisition or development of a metadata management systems such as the Metabase System that can capture, store, report, and evolve all the IT-related work products such that they are visible and are able to be used and reused at a minimum across projects, and better across business functions, and ultimately across the enterprise.
- Engineering of work teams that are heavily populated with functional users while ensuring that all generated work products are non-redundant, integrated, and interoperable, and that they are stored and made visible through an enterprise metadata management system like the Metabase System.
- Ensuring that work accomplishment metrics are continuously captured so that real work plans and effort estimates can be quickly produced.
- Acknowledgment that enterprise data architecture models are the center of the IT universe and ensure that all IT projects ensure data consistency and interoperability.
- Ensuring that “local definitions” exist for all the business fact work products that exist for meta category value taxonomies, data elements, attributes, columns and DBMS columns so that naming and definitions can be automatic.
- Ensuring that all business information system analysis activities that detail use cases from business functions are cross-referenced to data models.
- Ensuring that all user acceptance tests are completely cross referenced to, for example, use cases, requirements, mission-organization-functions, and database models.
- Business Information System projects will be more accurate and features will be better known because the iterative requirements strategy will be eliminate requirements analysis and design errors that occur because the solution domain is not fully known prior to a project’s plan, time line, and resource estimate.
- Business Information System projects will have to be implemented in production systems only once because the vast majority of uncertainty will be eliminated.
- Business Information System projects will accelerate accomplishment because new ones will be able to be built upon pre-existing, well defined data and business information system work products that are enterprise mission-based rather than ever changing business organization and function based.
The following are Metabase System projects that will contribute the achievement of the challenge objectives:
- Enterprise Mission Architecture
- Enterprise Data Elements
- Resource Life cycle Analysis
- Database Objects
- Enterprise Data Architecture
- Reverse Data Engineering
- Fact Semantics Management
- Fact Name and Definition Management
- Information Systems Plans