
You would think that after knocking around in semantics and knowledge graphs for over two decades I’d have had a pretty good idea about Knowledge Management, but it turns out I didn’t.
I think in the rare event the term came up I internally conflated it with Knowledge Graphs and moved on. The first tap on the shoulder that I can remember was when we were promoting work on a mega project in Saudi Arabia (we didn’t get it, but this isn’t likely why). We were trying to pitch semantics and knowledge graphs as the unifying fiber for the smart city the Neom Line was to become.
In the process, we came across a short list of Certified Knowledge Management platforms they were considering. Consider my chagrin when I’d never heard of any of them. I can no longer find that list, but I’ve found several more since.
Before I go too much further, let’s attempt to figure out what knowledge management is. Warning most of what follows has that combination of authority and vacuousness that we’ve come to expect from ChatGPT. But here goes.
Let’s start with IBM:
Knowledge management (KM) is the process of identifying, organizing, storing and disseminating information within an organization.1
Sounds good, doesn’t it? Until you think about it. How is this distinct from any other kind of data management, information management, knowledge graph, or frankly any computer system?
In all fairness, after telling you that not having KM is bad, and that having it is good, they start to wander into what knowledge is. This is promising. They tell us that there are three types of knowledge: tacit, implicit, and explicit. Tacit knowledge (how to speak a language, ride a bike or lead a group) is typically not able to be codified. Implicit knowledge on the other hand merely hasn’t been documented, yet. When it is documented, it becomes explicit, and therefore as far as knowledge management is concerned there is one type of knowledge: explicit.
Explicit knowledge, they go on to say, is captured in manuals, reports, and guides. Okay, now we’re getting somewhere. They go on to say the main types of KM systems are: document management, content management (I’ve always found that to be a difference without a distinction), intranets, wikis and data warehouses. (As they say on Sesame Street, which two of these are not like the others?)2
Let’s quit picking on IBM and pick on someone else for a while. KM World goes with Tom Davenport’s 1994 definition of Knowledge Management:
Knowledge Management is the process of capturing, distributing, and effectively using knowledge.3
They go on to quote Gartner as the go to authority on the topic:
Knowledge management is a discipline that promotes an integrated approach to identifying, capturing, evaluating, retrieving, and sharing all of an enterprise’s information assets. These assets may include databases, documents, policies, procedures, and previously un-captured expertise and experience in individual workers.4
They go on to outline what Knowledge Management5 consists of:
- Content Management
- Expertise Location
- Lessons Learned
- Communities of Practice
This especially rang a bell, as one of our knowledge graph projects was an expertise locator system. I’m feeling a bit like Mr. Jourdain from The Bourgeois Gentleman, who was delighted to know that he had been speaking prose all these years without knowing it. Perhaps I’ve been doing Knowledge Management all these years without knowing it.
Indeed, when I found out that the only KM tool that was on both the lists of KM tools that I found was Atlassian’s Confluence (an internal wiki platform that we and many people use). I thought, maybe we have some knowledge. Alas, a quick skim of the contents of our site disabused me of that notion.
Maybe we haven’t been doing knowledge management. Let’s take a deeper look.
Is all this stuff we’ve been putting in Knowledge Graphs, knowledge? If so, what type? If not, what is it?
Let’s start with some good old facts.

Let’s say we discover that:
- The Empire State Building is at 350 Fifth Avenue, New York NY
- It is 1,454 ft tall
- It was designed by the firm Shreve, Lamb, and Harmon
(By the way, this isn’t any kind of secret, I got it from Wikipedia). Is this knowledge? Some people would say it is, but in semantics and knowledge graphs we’d say these are assertions. We implement them as triples. They are in the “ABox” (the Assertional Box). We don’t need any special knowledge management system to manage this type of information. In fact, it would get in the way. When we reduce this kind of information into triples it has all sorts of emergent properties that don’t exist in a KM system. We can join this information with a multitude of other information (in a graph!). We can query it, it aggregate it, apply graph analytics, and much more. Also, it scales far better. It is far easier to deal with a billion triples than find the equivalent information in a hundred million documents.
Let’s return to the Empire State Building and consider what other knowledge we might have.
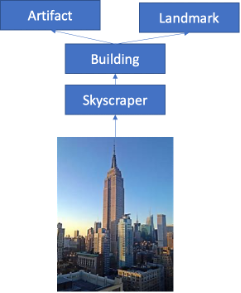
We might know:
- It’s a skyscraper,
- And therefore, a building, and therefore
- An Artifact, and also
- A Landmark
And we can infer a great deal from these simple realizations. We can also make it far easier to find these nuggets of information if we can search at any level of this class hierarchy. We handle this in the class structure, the “TBox” (Terminological Box). But again, we don’t need KM to help us do this. Indeed, it isn’t much help with this at all.
One more candidate set of artifacts that might be knowledge and might benefit from KM:

We could categorize the Empire State Building. There are probably dozens of ways we could categorize it for different purposes. This is one realm where we seem to be getting closer to traditional KM. But really, this is closer to Taxonomy management. Taxonomy management is the art and science of creating and using categories. As a standalone exercise, it is kind of pointless, but when combined with the things it is categorizing it can be useful. In a content management system or an authoring system, this usually manifests as key words. These categories can be reduced to labels and then applied to documents in a process professionals call “tagging.” In a Knowledge Graph, we use triples to categorize. It is just far easier to have a single unifying approach to querying that includes taxonomic categories. We call this the “CBox” or categorical box.
So, I think we’ve undermined Knowledge Management’s role in a great deal of the information typically found in an enterprise. Is there anything left? Yes, it turns out there is a role for Knowledge Management. Is there a way to integrate Knowledge Management and Knowledge Graphs? Again, yes, I think there is.
First let’s go back and debunk some of the lofty language we opened this paper with. Recall this part of Gartner’s definition: “Knowledge management is a discipline that promotes an integrated approach to identifying, capturing, evaluating, retrieving, and sharing all of an enterprise’s information assets.” Could anyone believe that a KM system could do even a tiny percent of all of an enterprise’s information assets? Really? Payroll data? Inventory? Click stream analysis?
If it isn’t all information, then what subset is it, and how do we integrate the knowledge with everything else?
After reflecting on this a lot, I would say that knowledge, is currently bound tightly to content (documents, videos, etc.). The problem with content is that it mostly requires humans to read or watch and understand to apply it. That’s not all bad. If we can get the right document to the right person at the right time, that can be helpful. But we can do better.
Let’s assume for the moment that an enterprise will still have a lot of content. What is the best we can do?
We did a project with Sallie Mae (the student loan company). What we discovered was that most of the content they had either related to their customers (students and universities) or their own products (what was the procedure for requesting forbearance on a particular type of loan).
A knowledge graph is an excellent way to integrate data from diverse structured data systems (and most firms have thousands of such structured data sources). Since the content of interest is generally related to the data from the structured sources, this seems to be the logical level of integration. In other words, connect the structured data, as normalized and rationalized in the graph, directly to content where it refers to specific people, organizations, events, products, and the like. At this level, nothing extra is needed from the document or content management system other than access by an NLP crawler to find all the points of connection.
Does this mean there is no role for knowledge management software in the enterprise? No. As it turns out, there is one category of information that fell through the cracks of the above decomposition.
Distilled, or Aggregated Knowledge
As demonstrated, there is a category that doesn’t naturally lend itself to knowledge graph representation. (It is occasionally done, but it’s an unnatural act).
That category is information that is currently the human distillation of lots of other data. We think of it as experience or insight. In the Empire State example, we would include observations such as the recognition that:
- It’s a skyscraper, and
- Typically, skyscrapers have steel frames that support curtain walls.
- Wind is usually a more significant load factor than earthquake or weight in the design of skyscrapers.
- Skyscrapers have elevators.
- Skyscrapers are built in large cities where the price of land is high.
The reason this isn’t a natural match for knowledge graphs is because knowledge graphs are typically built on specific instances. In the student loan knowledge graph, there are billions of factoids (triples) about millions of students and their loans. There is a bit of categorical information and things that are true of all instances of a given type of loan or type of student, but not a normal place for the qualitative and population-based information. We need to be able to say that students that drop out of college have a higher default rate than students that complete their degrees. This is not a fact you attach to an individual student, but a learning you attach to a population of students.
At Semantic Arts, we are now working on a Knowledge Ontology. Up to a month ago, I would have thought this redundant, that all ontologies are knowledge ontologies. But now I’m getting a different perspective.
This will be an ontological structure for storing and interrogating this type of knowledge. Our working title for this is the “typically” ontology because most of the information in it is typically true. Brent Crude Oil is typically found in the North Sea. Gout is typically caused by elevated levels of uric acid. The incidence of successful phishing attacks is typically reduced by internal simulated phishing drills. Sovereign currency inflation typically weakens exchange rates.
We think the highest use of a Knowledge Management platform
is the development and codification of this type of curated and distilled
knowledge. And the role of a knowledge graph is to organize most of the rest of
the information of the firm. The role of the Knowledge Ontology specifically is
to provide the link between the two.
[1] https://www.ibm.com/topics/knowledge-management
[2] Ok, I’ll help you with this one. An intranet is a network more than a content management system. And a data warehouse would be an odd place to find knowledge. You can find a lot of data but bring your own knowledge.
[3] https://www.kmworld.com/About/What_is_Knowledge_Management
[4] ibid (I always wanted to say that in an article, and somehow it never came up)
[5] ibid (two ibids in one paper! I’m living the good life here)
