
Tucked away in portals across the internet, in different formats, with bad headers, strange encoding, and more – the world of data can be treacherous, and despite ‘data scientist’ being dubbed the sexiest job of the century, every data professional knows that it’s not all glitz and glam.
There are plenty of steps between getting your hands on the data and when it’s ready for modeling and analysis. Today, let’s look at the difference between data cleansing and data enrichment.
Think of data cleansing like the work of a prep cook: separate the good from the bad, wash off the dirt, measure, cut to size, and then put the pieces in labeled containers. Data enrichment, on the other hand, is the chef’s touch: combining different ingredients to create a dish that’s greater than the sum of its individual components.
What is Data Cleansing?
Broadly, data cleansing consists of inspecting and formatting the data to make it suitable for analysis. Problems in the data need to be rectified in order to make the data useful for data scientists – they can be simple or complex, quick and painless, or time-consuming and tedious. Common data problems include:
- Incorrect data types (such as text cells in a currency field, or integers in a name column)
- Data that does not conform to requirements or patterns (such as dates and times, postal code formats, e-mails, phone numbers)
- Inconsistencies within the data (such as conflicting addresses for the same business, duplicates of rows), and many more.
What is Data Enrichment?
After the data is cleansed, it can be enriched. Data enrichment is the process of enhancing data by appending additional information to an existing dataset. The result is a richer dataset that makes it easier to derive more data and get better insights. For example, imagine you have a dataset containing a business name, their phone number, and address. Now we can enrich that data by pulling records from the stock market indices to get the stock price and valuation for each publicly-traded business. Additionally, we can pull from an online Maps API to get the precise location or add additional geospatial information. The possibilities are almost endless, and it’s critical to fully understand the problem you’re trying to solve when sourcing and combining data.
The Impact of Data Variety
Data coming from a multitude of sources, both inside and outside an organization, introduces data variety. Depending on who you are, data variety can sound like a blessing or a curse. While variety is vital to getting unbiased, corroborated data, it also means jumping over massive hurdles to achieve data parity before any data can be engineered efficiently or used together in a meaningful way. Like anything, an ounce of prevention is worth a pound of cure – having a data variety solution from the start of a project is the easiest way to ensure consistent progress throughout.
Why Do These Things Matter?
Why does data need to be cleansed? Why does it need to be enriched? And most importantly, why are data cleansing and prep so important to your organization?
The one-word answer is: “Money.” Insights-driven organizations are growing annually at a rate of 30% and are on track to earn $1.2 trillion by 2020 – looking at these numbers, it would be downright bad business to ignore the value in a data-driven strategy.
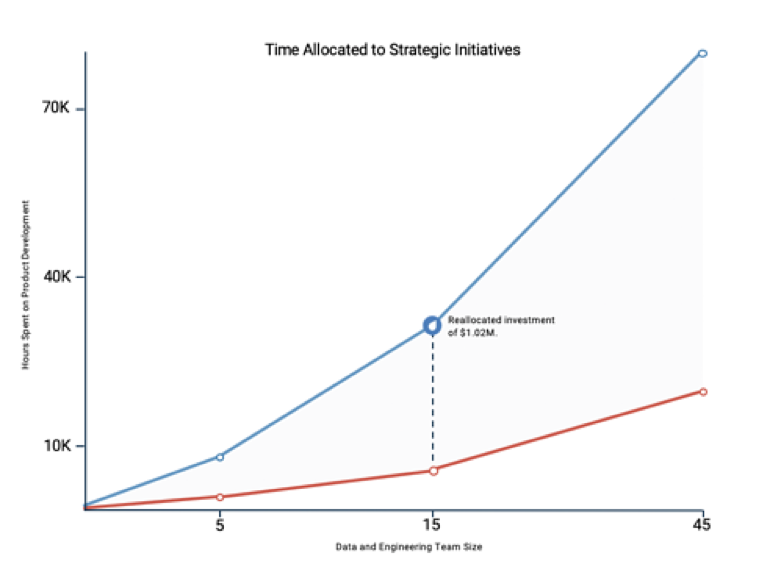
Data variety is an obstacle for everyone, no matter how large the team. Although, the majority of companies are worried about a talent shortage when it comes to data, the root of the problem is a strategy shortage. Finding and preparing data is the most time-consuming and least enjoyable part of a Data Scientist’s job. The below graph highlights the reallocation of investments when teams leveraging data prep automation tools.
As more and more organizations begin to adopt a data-driven approach to business, relying solely on internal data is no longer enough to be competitive. To stay ahead, organizations need to introduce external data sources into every piece of their data pipeline – and that means implementing adoption strategies and methodologies (like DataOps) to ensure high performance and consistent successful outcomes.
