
In her groundbreaking article, How to Move Beyond a Monolithic Data Lake to a Distributed Data Mesh, Zhamak Dehghani made the case for building data mesh as the next generation of enterprise data platform architecture.
Data mesh is a distributed platform that is organized based on subject-specific data domains which are owned by independent cross-functional teams. It is a socio-technical approach to share, access, and manage analytical data in complex environments that could span across multiple organizations or within.
The concepts lay out an approach to modern data platform architecture.
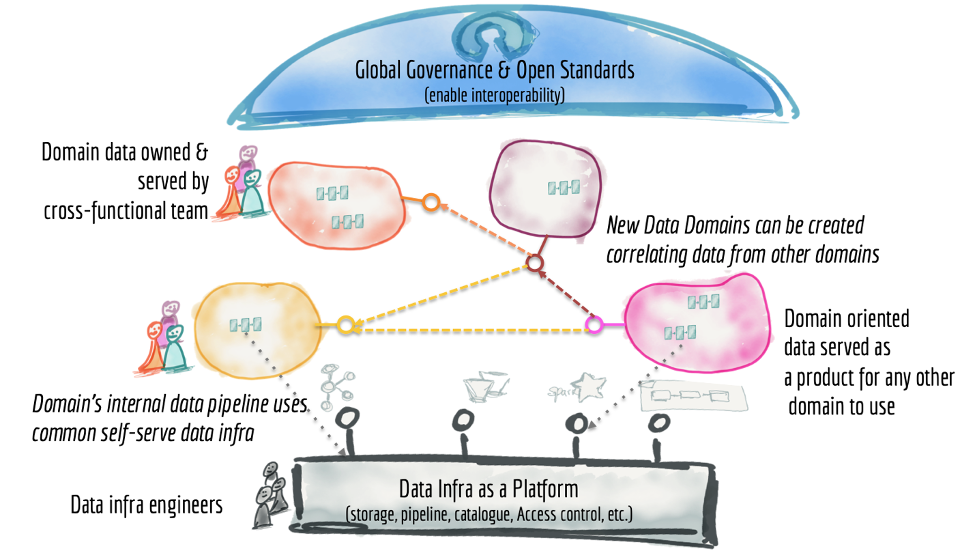
diagram by Zhamak Dehghani.
Click to view larger
Some of the main benefits of adopting data mesh are:
- Enable autonomous teams to get value from data
- Exchange value with autonomous and interoperable data products
- Accelerate exchange of value by lowering the cognitive load
- Scale out data sharing
- Support a culture of embedded innovation
From EDWs to Data Lakes – the Challenges of Shifting to a More Agile Architecture
If we were to review the history of analytical data, the enterprise data warehouse (EDW) has remained the mainstay of analytical insights till recent times when cloud migration accelerated. This movement was motivated by the advent of the data lake which provided newer abilities to answer the questions that analysts or data scientists needed to answer as part of their data projects. EDWs and data lakes suffer from a combination of architectural limitations that put their long-term viability into question. As new data sources are added and more data is brought into the enterprise data ecosystem, an enterprise’s ability to bring all the data to a centralized location, integrate and transform it decreases over time. Various components of a data pipeline tend to be highly coupled and interdependent which makes adding new data sources to support new functionality or use cases a significant change to the entire data pipeline.
In addition, because the engineering teams were separated from the operational data sources there was a disconnect on how data was sourced and utilized to build analytical Insights. This created an unenviable position for this team to continuously build new data pipelines and transformation either to enhance current business understanding or implement new use cases. The ability to embrace rapid, adaptable and agile methods ran counter to the ability to add new source systems.
Zhamak pointed out that over the last decade organizations have successfully applied domain-driven design and context to their operational systems, but they have largely disregarded applying the similar concept to their data platforms. For their analytics initiatives, companies have largely moved toward centralized architecture. Whereas for their operational systems, they have adopted domain-driven modeling and other decentralized methods to keep up with the speed of business. Meanwhile, data projects remained characterized by data warehouses and data lakes with domain-agnostic data ownership. The ability to build out systems that supported the ambition of self-service analysis eluded. This was further complicated by the raising of the bar around how to govern and manage data to preserve privacy and ensure compliance.
To the Rescue: Data Mesh and its Guardrails
The data mesh seeks to provide a recipe to solve these complex scenarios based on the concepts of domains and data products. A data mesh treats originating sources and use cases in which data assets are stored and transformed as nodes in a subject-specific domain to produce various data products. These nodes acknowledge upstream as well as downstream systems such as EDWs. In a data mesh, instead of extracting data from originating data sources into a central data warehouse or a data lake, originating domains or repositories themselves host their applicable datasets and serve them to data consumers based on their business context and use cases. This basic principle has brought a seismic shift to the modern data governance architecture.
For some time, organizations have been operating on a faulty assumption that centralized data governance goes hand-in-hand with centralized data management. Organizations planning to implement a data mesh must recognize a new paradigm of data governance and ownership. Data mesh decouples data governance and data management so that data is managed in unique domain-specific repositories. However, data governance is accomplished by focusing on policies that can be globally applied to manage user’s access. The framework accommodates each domain’s ability to apply unique mechanisms of data policy overall providing more effective access control. This new form of delegative access control and scalability are critical enablers that support a self-service form of Analytics.
Another key concept in data mesh is federated computational governance. This concept leans heavily in favor of a data access governance platform with native enforcement across domain-specific sources. In fact, it might be the only viable way to administer fine-grained access control for each data domain. For example, a simple data mesh composed of three unique data domains – such as customer data in a cloud database, web tracking data in S3, and an analytical data domain on Amazon EMR (Hive and Spark) – is a complex technical implementation. The data sources here represent different states of unstructured and structured data implemented using diverse technologies. It requires a method to unify these concepts and create the boundaries of governance. A data access governance platform could natively administer consistent access policies on:
- tables and columns in a database;
- files, objects and buckets in S3 object store;
- and the combination of the two in a cloud big data platform such as EMR.
This keeps the boundary of access consistent, secure, and adaptable to rapidly changing requirements.
Conclusion
Data mesh supports a wide variety of analytical use cases ranging from 360-degree customer view, segmentation, next-best-offer, churn prediction to name just a few. However, when data is distributed across a number of domains, security and access control plays a critical role. For example, data products need to be easily discoverable through a catalog while the underlying data sets are classified based on sensitive elements. To deliver on its promise, data mesh requires robust capabilities relating to data masking, filtering, encryption, regulatory compliance and auditing, enabling data consumers such as BI analysts and data scientists to not only find the data of interest to them, but also foster their confidence in its usage.
Secure data democratization is the foundation on which data mesh rests, and it cannot be achieved without implementing a scalable, effective governance framework. Effective governance removes the technical complexities of managing domains, while enabling consistent and secure access across them. Most importantly, an effective governance framework ensures data is controlled and secured at a granular level. These controls, when applied consistently across data sources, provide detailed visibility of how data is accessed and used, which eases the compliance process by removing uncertainty and being able to test and audit controls comprehensively.
