1.0 Introduction
The purpose of this paper is to present and discuss the loading processes of the Data Vault™. A patent-pending approach to modeling the enterprise data warehouse, it is an evolutionary
approach to solving the problems of active data feeds and large volume batch feeds that load data warehouses today. The audience of this paper should be those whom are interested in implementation
of architectures and processes for getting the data into the proper data entities. We also discuss the templates from a perspective of SEI/CMM Level 5 – repeatable, reliable, and quantifiable
results. The topics in this paper are as follows: (all topics are at a summary level)
- Loading Hub Entities
- Loading Link Entities
- Loading Satellites
- Summary and Conclusions
Several of the objectives that you may learn from this paper are:
- How to develop consistent and repeatable ETL processes.
- Best Practices for the types of information in each Entity
- Overview of the loading paradigm for the Data Vault
This paper discusses these processes from a repeatable, consistent design approach. These are the concepts behind loading the data and do not include any of the actual “code” that is required to
achieve these results. Depending on the loading mechanism chosen, the “code” or design may vary somewhat. What this article will do is present the suggested best practices from a strategic and
tactical (near-real-time) perspective.
While designing the Data Vault, I have considered the best practices for building highly scalable and repeatable warehouses – including load processing and query processing. In order to meet these
needs I have designed an implementation methodology known as The Matrix Methodology™.
2.0 The Matrix Methodology – Overview
The Matrix Methodology is defined to be a repeatable and consistent architecture for loading, processing, and retrieving data from an Enterprise Data Warehouse. At its heart beats the Data Vault as
the architecture of choice for the Enterprise Data Warehouse. So this leaves us wondering, what exactly does TMM have? What does it do? Why is it as important as the Data Vault? We will explore
these questions shortly – first below is a figure that explains in a nutshell what TMM is comprised of:
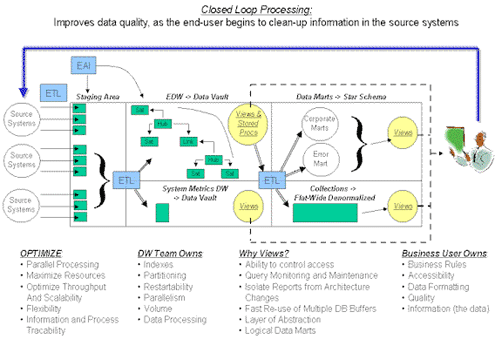
number of templates and designs that are easily followed. These templates are available for sale.
So why call this “The Matrix Methodology?”
It’s a matrix of solutions. Dividing this up by components vertically and horizontally for scope – dramatically reduces risk of failure, promotes re-use and delivers answers rapidly. The Data
Vault is only one component and happens to be the main component to the heart of the architecture. A horizontal line across the components provides us with a bottom up implementation – implementing
only what the end user has signed off on for a given result set.
The closed loop processing puts the data squarely in the hands of the user; it also puts the ownership of the information (accountability for its quality) back in the hands of the user. We use a
technique called an Error Mart for delivery of data that simply doesn’t fit the mold. Enough of TMM – feel free to email me directly if you have questions regarding the methodology. The point here
is to share the next diagram: the loading phases of the Data Vault.
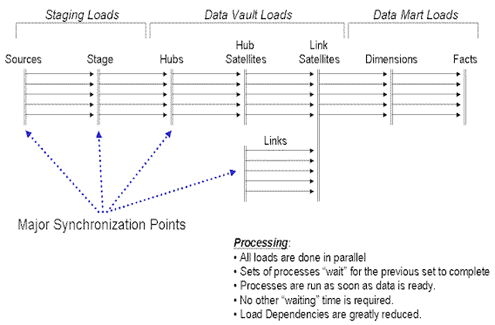
templates for loading the staging areas nor the data marts.
What makes the Data Vault Loads special?
The Data Vault is based on consistently inserting data. The information in a Data Vault should remain consistent – always inserted, not deleted nor updated (except with data feed problems). In
other words, unless the data set is being rolled out/rolled off, or it is discovered that the data set is in error it will not be deleted, and it will not be updated. The following notions are in
place when the templates for the load processes are built:
- Volume Requirements
- Latency Requirements
- Repeatability
- Consistency – Load the same way for historical, current, and initial load.
- Reliability
- Restartability – no more than a simple re-start button to recover where it left off.
As already indicated, the Data Vault is the modeling architecture for the enterprise data warehouse, and therefore becomes a system-of-record for the enterprise. The system of record
must be reliable and consistent in all manners and aspects.
With data sources producing massive volumes and the need to have compliance and international regulations enforced – it is imperative that we establish a trusted loading mechanisms. Our loading
mechanisms must be as reliable as possible. Of course there are other items like establishing load-dates and record sources that are not defined in the scope of this paper. The typical best
practice is to define these items as the information is staged (loaded to the staging area).
With that, let’s examine the actual loading processes.
2.1 Loading Hub Entities
Hub Entities record the FIRST time a business key has reached the system of record (Data Vault). They do not record subsequent loads, or any other changed data. To load a hub, we must first test to
see if the record has already been loaded (already exists). This will account for a previously broken load process, as well as duplicate information within the same loading mechanism. Change Data
Capture on the source system helps a great deal, until the actual loading process into the Data Vault (EDW) itself breaks. At that point, we require a standardized mechanism for detecting change
going into the hub processes. Below is the process flow for loading a hub:
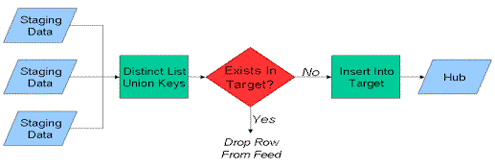
Loading a hub is fairly simple. There are a few things to remember about loading Hubs. The following is a list of items to consider.
- All Hub Business Keys must be unique, and 1 to 1 with the surrogates.
- Hub Keys are NOT time based
- Hub Keys do NOT support duplicates
- Hub Keys are defined at the same semantic layers
Loading a hub consists of first, identifying the “master” system, the system where the business thinks most of the keys are actually generated; of course this assumption must be tested against
the actual data set arriving from that system. Once the master system has been identified it is pulled from first. The keys that do not exist in the target are loaded as a distinct/unique list, and
provided a surrogate key at load time. Then, the rest of the systems are ordered in terms of importance. The second system (most likely to produce a key), even if the business states that this
system never produces keys, then is pulled from in the same repeatable fashion.
This process is repeated for each source system that contains a hub key field. This notion of containing a hub key has no bearing on the actual source system’s design – in other words, the field
used to populate the hub key may or may not be a foreign key in the source system design. What we record is the fact that a key exists, and therefore must be placed in the Hub. Finally, those
components of information that have no key; say a table contains product master information, and is a secondary source for customer number, and customer address; in this case the customer number is
blank or null, and customer address is filled in. What do we do? We populate the customer number with nothing (attach it to a hub row called a zero row key or UNKNOWN), so that the customer address
data is not lost during the load of the Satellites.
Duplicates in Hubs will cause many other issues ranging from SQL query problems to additional modeling problems. It is not recommended to load Hub Keys with duplicates. Ok, so what about “bad
data?” There is a specific case for bad data. In other words, a source system has a customer account number, but the source system has been “sold” to different states, and therefore there are
duplicate account numbers (for different customers) across the states. How do we load this data?
One idea is to include the record source as a part of the business key, this is the typical solution usually offered (for uniqueness), but there has been another approach on the horizon: add the
“state-code” or another piece of identifying data to the customer account number to synthesize uniqueness. This will work, but only scale so far. Eventually if the secondary or tertiary key is
chosen to be added to the business key, and that particular field begins to have “qualifying” or independently identifiable properties, then it will have to be broken out into it’s own Hub.
In other words, we can get away with using State Code for a while, but if we must begin capturing information about the state code, we will be forced to create a separate Hub for it. The ground
rules here are: poorly identified elements coming in, force architecture breaks – which lead to a break down in the Data Vault design. It usually means the source system has some issues with its
design that go deeper than just the data set.
When we look at the actual loading processes, all Hubs can and should be loaded in parallel as the first step. In this manner we can produce a highly scalable architecture – more data, more Hubs,
more simple loading processes all in parallel. We can also utilize the investment in the hardware that has been provided – and show or even project when new hardware will be necessary to increase
the loads. This is for a batch oriented solution, when the data is ready, load it.
2.2 Loading Link Tables
The Link tables without surrogate keys are loaded in exactly the same manner as the Hubs. However, since a majority of the EDW’s today utilizes surrogate key structures, we will indicate an extra
step in the load process to locate those Hub rows.
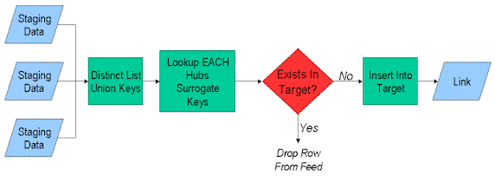
In this context, loading of the Link Tables performs the following; keeping in mind that this presentation of the load sequence is based on a puritanical approach. First, we formulate a unique list
of all the business keys that make up the relationship data for the link. Then, we lookup or locate each of the Hub’s corresponding surrogate keys. Finally we check to see if it exists in the
target, if not, it is inserted with a new Link Surrogate, if it does exists, it is dropped from the stream.
Duplicates in Link Tables usually mean a poor definition of grain, or mis-modeled Link Entity. In this case duplicates represent (again) duplicate business keys, not necessarily duplicate
surrogates (of course). The problem is usually the grain. If the processes can’t find an old satellite record to end date (even though it exists), then there is a grain flaw in the Data Vault
model of the link table. The Link must then be re-designed to fit the grain, and usually another level of Link (grain) is pulled from this table.
Link table loads are successful when ALL relationships between business keys have been recorded. If there are missing business keys then just like the Hubs, we load “zero” keys and tie the
relationships to “unknown” Hub records. This allows the data to continue loading into the model without breakages. Capturing all the relationships, even the broken ones provides a full audit
trail capability to the business users, so that we (IT and Business can trace the information back to the source systems). All the Link Loads can be run in parallel as well. In fact, if there is
enough hardware available it is recommended to load the Links while the Satellites for the Hubs are loaded. This allows maximum throughput to be achieved.
2.3 Loading Satellite Entities
Loading Satellites is the easy part. End-dating the Satellites sometimes takes a bit more work. Of course this is a high-level overview of the loading process. The full details of the loading
process will be covered in my upcoming book (which you can find parts of on www.DanLinstedt.com). To load the Satellites, the following architecture is
utilized:
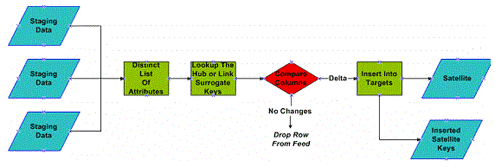
This figure represents the loading of the Satellite. In this loading process we first, establish a unique list of attributes. This is required in order not to load “duplicate attribute rows” into
the Satellite target. All rows that have data in the staging sources must be accounted for and loaded to the targets. This means utilizing default data sets for some columns, which is why we
suggest default values as a part of the process. However defaults are not used for numerics, those are left NULL. Of course the ultimate value is to leave all fields NULL if they arrive in that
format, however that makes querying and comparison difficult.
From there, we lookup either the Hub key or the Link parent key so that the Satellite row can be attached to the proper place. If the parent key doesn’t exist – we have a mechanical error in our
loading processes of the Hubs or Links – an alert must be generated at this point, and the load process stopped. Once the error is fixed, it should remain fixed for a long time. From there, we
compare the columns of the data coming in with the most recent picture of the data currently in the Satellite. This is done to ensure we do NOT load duplicate data. We do not want a data explosion
problem within the Satellites, this is where we get Satellites to comply to rates of change and type of information.
If the detail of the row actually has a delta, or simply doesn’t yet exist in the target, it is inserted. There is a secondary table that is maintained in the staging area. For each load it is
truncated, and re-loaded with just the primary keys of the satellite record that is inserted during the processing. This makes it easy to pick up the primary keys of the Satellite, and finalize the
end-dating process of existing records without scanning the entire set of data in the Satellite to find out what’s new and what’s not. The end-dating process architecture might look like the
below diagram:
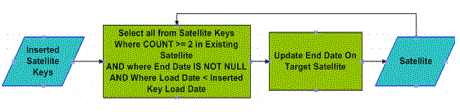
In this loading process, the most recent Satellite record that has not been end-dated, but is a part of the PK load will be end-dated during the run. This particular process is fully restartable,
and completely scalable. Only the rows on the Satellite that need to be end-dated will be. If the inserted keys were already updated, then they would not be “end-dated” again. End-dating
satellites is critical to knowing which data is active. All processes are designed to be repeatable, consistent, scalable, and restartable in nature. With that, please be aware that loading data in
near-real-time changes the design of the load process a bit.
2.4 Real-Time Loading (EAI)
Typically in a real-time system the transaction carries: Hub Business Keys, the relationship (the transaction itself), and transactional descriptive data (or a Link’s Satellite information). Also
in these systems the data arrives too fast and too furious to spend time putting it into a staging area, then trying to “clean it up” so that it’s ready for the Data Warehouse. The minute we
spend time cleaning, cleansing, or integrating the data – it’s decayed or “dead”, and the transaction has either been updated, or deleted. In any case, capturing transactional data to any sort
of “staging” area is difficult to near impossible without some requirements that allow for “lag time”.
An example transaction might be an ATM withdrawal where the account was just opened at 8:00am, and the withdrawal was made at 9:00am. The transaction that arrives in our system only indicates the
account number, the total amount withdrawn, the date/time it occurred, and probably the branch. It might also indicate the total in the account available for withdrawal. Most likely that
transaction contains no information about the customer name, address, or credit score. Those details will arrive in a nightly batch at the headquarters (main banking computer) probably late
tonight. So, we need to store the account number in the Hub, The Customer number in the Hub, and the account-customer withdrawal in the Link table to make the association. If we have the branch
number of the withdrawal, that might also be recorded in the Link table as the location. Finally, the Satellite on the link is built with the total in the account, the date/time and the amount of
the withdrawal.
In a real-time environment, the keys will be pulled from the transaction, the Hub will be loaded on the fly, and the link tables populated at the same time. Finally it is most likely that during a
real-time load, the Satellite information for the Link (transactional detail) will also be available, so it will be loaded either at the same time or near the same time as the Link table parent.
Real-time environments change latency requirements. Usually there is less volume to deal with, but a shorter time-frame to load the volume as it’s received. If the onus is put on the loading
processes, there is less opportunity to build real-time systems. In other words, additional heavy lifting of data quality, cleansing, and mixing, matching, purging, etc… all causes latency
slow-downs that are not affordable during load of real-time data. In a final example of this: take any transaction arriving on a real-time basis (5 second updates). We receive a transaction that
says: insert me, I’m new. Our rules prohibit the data from making it into the warehouse – so the load process fails the row and puts it in a flat file, then alerts us to fix it before it can go in
to the warehouse.
If it takes us 5 minutes to fix the data and 5 minutes to re-load it, then by the time we’ve fixed and re-loaded it, it has received additional “update/delete” transactions. We are already
behind. A loading architecture designed like this will not work in real-time. Unfortunately the data model choices force us into these beliefs, and these paradigms. Using the Data Vault will help
avert some of these disastrous results during the load cycle.
3.0 Summary
In summary, this article covers an introductory look at the loading processes for each of the key table structures. These load architectures are based on the pure approach to the design of the Data
Vault. Deviations will be accounted for as you go along. However 80% or better of the designs (whether written in ETL like Informatica, Ab-Initio, or Ascential, or written in SQL in the database
all follow the same standard paradigms. Don’t touch or change the data on the way into the Data Vault, manipulate it according to business rules on the way out – to the Data Marts.
Furthermore if there needs to be some interpretation, some layer of “roll-up” or aggregation, then implement a hierarchical Link table and make the record source equal “SYSGEN” or some similar
value. This will keep the generated data separate from the source system data, and still allow trace-ability. There are several Data Vault projects under-way, and one major implementation that has
been completed. The next series will explore some of the query techniques needed to retrieve data from the Data Vault structures.
