
Canonical Data Models and Overlapping Connections
In the previous article, I introduced and explained the approach to application development called ‘Domain-Driven Development’ (or DDD), explained some of the Data Management concerns with this approach, and described how a well-constructed data model can add value to a DDD project by helping to create the Ubiquitous Language that defines the Bounded Context in which application development occurs.
In this article, I’d like to explore in more detail a point I made in the earlier article about the importance of defining and persisting data entities at the correct level of the application and data architecture. I remarked that defining and persisting data at the wrong level can create massive headaches, not only for the project team, but for anyone else in the organization who needs to use that data for any other business purpose.
Remember that in DDD, it is assumed that data will always be persisted at the subdomain level; that is, each subdomain will have its own dedicated persistence store. In this persistence store, data is only defined to the extent necessary to support the services defined within the subdomain. Similar entities and attributes in two different subdomains may have different names. Different entities and attributes may have the same names (like the Product entity in the Bounded Context example shown below). Entities may be only partially defined and implemented within each subdomain. This results in what Martin Fowler refers to as “Multiple Overlapping Canonical Models,”[i] as shown in the following example:
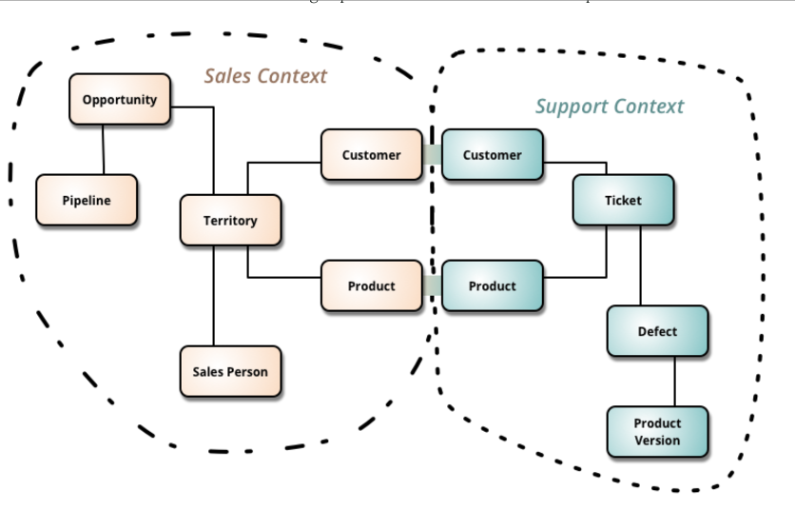
In this example, Customer and Product data are split between two different Bounded Contexts, and two different data persistence stores. The same attributes may exist in both subdomains, with different names and datatypes, or a given attribute may exist in one subdomain, but not the other.
Forcing all data to be defined and implemented at the subdomain (or Bounded Context) level can be problematic for a number of reasons. I’ve already mentioned that it makes it harder for developers working within one Bounded Context to create services that communicate with a different Bounded Context, if similar data elements aren’t similarly named and defined. It also makes sharing knowledge with team members across subdomain boundaries more difficult.
But there’s an even more important reason: When entities are only partially defined, and implemented at the subdomain level, services may need to connect to multiple subdomains in order to get all of the data needed to fully define an instance of an entity. A service defined on the Sales subdomain may need to get Customer data from the Customer entity in the Support subdomain, and vice-versa. A similar situation may exist with the Product entity. This results in a situation that Martin Fowler refers to as the “NxN Connections” problem, where services are having to make a number of unnecessary calls to other subdomains to get data needed by the service. Also, where similar entities and attributes are not similarly defined across subdomain boundaries, each service will have to “translate” the Ubiquitous Language of the target subdomain into its own language. For example, the service will have to know that Customer Phone Number in the Sales subdomain is called “CustPhoneNo”, is defined as Integer, and contains 10 numeric digits while in the Support subdomain it is called “CUSTOMER_PHONE”, is defined as char(12) and contains values like ‘206-555-1234.’
To resolve this issue, Fowler recommends the creation of what he calls a Canonical Data Model (CDM) for the multiply-referenced data entities. This brings together all of the disparate data and resolves the language differences. He further recommends that this data be persisted at a higher level than the individual subdomains (perhaps, he suggests, in a single database on the ESB Hub if your organization uses service-oriented architecture) and referenced there as needed by services in the various subdomains.
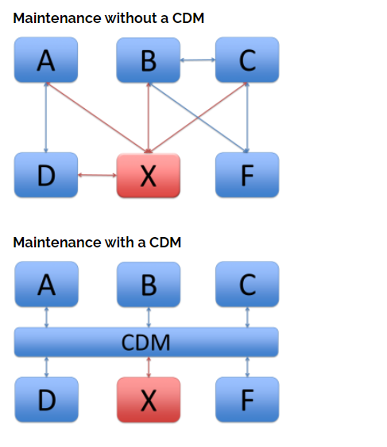
Right now, all of you Data people are saying, “Well, duh!” Defining the data model properly up-front solves a lot of problems. For one thing, it reduces the number of translations required when multiple services connect to multiple applications (the NxN Connections problem). In the example shown below, 16 translations are required when a CDM is not used versus 12 translations using the CDM. The number of translations required increases significantly as the number of applications being connected increases.[ii]

A CDM also reduces translation maintenance when one of the applications is changed (perhaps to a completely new application) and all the service connections to that application need to be changed. In the following example, application E has been replaced with a new application X. Without a CDM, there are 8 translations that need to be changed (to and from for each of the four applications that interact with application X). With the CDM, only two translations (between application X and the CDM) need to be changed.
Here’s an example: I worked on a project that involved setting up a new manufacturing plant in a South American country. We used mostly packaged vendor software to support processes such as Customer Relationship Management (CRM), Enterprise Resource Planning (ERP), Manufacturing Execution Systems (MES) and so on. We created services to pass data as needed between each of these applications. To do this, we created a Canonical Data Model for our most-used data entities (Customer, Product, Order, etc.). Then we used this data model to construct XML schema definitions for this data and used these schema definitions for the XML services that connected the applications. If application A needs to send data to application B, it puts the data into the canonical format and sends it via a service. Application B then takes the data from the canonical format, puts the data into its own preferred format and stores it.
Even in cases where data for the same entity needs to be persisted in more than one subdomain, having a CDM to ensure that the data is named and defined the same way across all the subdomains ensures that services don’t need to “translate” the data. This simplifies application coding and testing, improves application performance and scalability, and reduces maintenance and support costs for the application.
So, where should data be defined, and where should it be persisted? My stock answer to this is, at as high a level as possible. This ensures the maximum amount of usability (and reuse) of the data, across multiple applications and multiple business uses of the data (e.g., for organization-wide reporting and analytics). However, we also need to be cognizant of the requirements of projects to get new application functionality deployed as quickly as possible, and we need to be able to support Agile application development processes.
My approach to resolving this dilemma is what I call “Modeling Up and Building Down.”[iii] In other words, while trying to deliver what developers need in a reasonable amount of time (within the confines of a Sprint), I’m also trying to ask sufficient questions to determine whether the data requirements represent entities and attributes that are unique to a subdomain, are unique to a domain, or are canonical (that is, are more enterprise in nature, and span domains).
If my subdomain model needs an entity (say, Customer or Product Model) that is canonical, I will bring it in from my higher-level canonical or enterprise model, rather than remodeling it from scratch. If it needs an entity that has been (or can be) defined at a domain level (say, Warranty), I will model this at the domain level and then bring it into the subdomain. I’m always modeling at as high a level as possible, and then I bring entities down into the subdomain model for implementation for a particular application or service. So, the data model for my Warranty domain contains Customer and Product Model entities copied from my Canonical model, and the data model for my Product Registration subdomain contains the Warranty-related entities from my Warranty domain model, and so on.
This approach ensures that, even when the data itself is fragmented across subdomains, the underlying data models are not so that data is at least consistently defined across the multiple data persistence stores.
Before I close, one additional point needs to be made: Martin Fowler recommends that data be initially persisted at the subdomain level, and then moved up if and when it is found that the data is needed by multiple subdomains. Then the application services are refactored to work with the new canonical data structures. However, there are a lot of problems with this “harvesting” (Fowler’s term) approach. First, of course, is the amount of time and effort involved in refactoring both the data structures and the application services, and the impact of this refactoring work on the project schedule. Second, as I pointed out in my book, Building the Agile Database, unless the canonical data is properly modeled and implemented up-front, you may discover that it’s not possible to refactor the data into a canonical model, as critical data values may be missing or invalid. I gave an example of this from my own experience: the poorly-defined database for a time reporting application needed to be refactored, but all the data had to be thrown out and re-entered because critical key data values were either missing or incorrect.[iv]
I should also point out that this refactoring forces us to do the exact things we were trying to avoid doing by defining the data at the subdomain level in the first place: We have to find a way to resolve data meanings from multiple subdomains into a single Ubiquitous Language, and we have to integrate multiple applications or services through a database!
What this means is that we can only defer, not avoid, the work of correctly defining, modeling and implementing our data and data structures. And the longer we put it off, the more it will eventually cost us. This is yet another example of the fundamental economic principle known as TANSTAAFL (There Ain’t No Such Thing As A Free Lunch). We may decide to forego planning and provisioning of Canonical data to save us some up-front work in data design and application development, but we will end up paying for that choice later on when we have to shoulder the burden of refactoring. Pay now, or pay later.
To Be Continued…
[i] Fowler, Martin. “Multiple Canonical Models”. July 21, 2003. https://bit.ly/3xf6WgA.
[ii] Examples taken from Paasschens, Emiel. “Benefits of a Canonical Data Model (CDM) in an SOA Environment”. AMIS Technology Blog, August 8, 2016. https://bit.ly/35g1Rsy.
[iii] Burns, Larry. Data Model Storytelling (New Jersey: Technics Publications LLC, 2021), pp. 181-182 and 208.
[iv] Burns, Larry. Building the Agile Database (New Jersey: Technics Publications LLC, 2011), pp. 112-114.
