 Recent advances in data analytics have produced an insatiable appetite for data. Satellites, cell phones, and computers constantly churn out streams of information. Data flows from its point of origin to a target site and, in the process, is molded into shapes conducive to analysis. These strategically cleansed and canonically shaped bodies of data are carefully examined and parceled to make management decisions more precise and gain an advantage over the ever-present competition. The challenge is to quickly collect, process, and store vast quantities of data so that historical information can peacefully coexist with that which is newly collected.
Recent advances in data analytics have produced an insatiable appetite for data. Satellites, cell phones, and computers constantly churn out streams of information. Data flows from its point of origin to a target site and, in the process, is molded into shapes conducive to analysis. These strategically cleansed and canonically shaped bodies of data are carefully examined and parceled to make management decisions more precise and gain an advantage over the ever-present competition. The challenge is to quickly collect, process, and store vast quantities of data so that historical information can peacefully coexist with that which is newly collected.
The demand to efficiently deliver reliable, analytics-ready data in whatever form best meets constantly changing business requirements puts stress on an organization’s technological infrastructure. As a business evolves, its tactics and strategies change. This results in a steady stream of business requirements that are often in direct conflict with those established only a few weeks prior. This constant flow feeds directly into an IT layer with the expectation that IT teams will deliver in a very short amount of time. Complicating matters are the rapidly changing business requirements that have the potential to break existing data models and thrust IT teams into a downward spiral. Data models are especially important because they serve as any application’s backbone. There is nothing wrong with changing requirements. Changes are propelled by a business’s innate need to evolve to retain a competitive advantage. Once existing data models stop satisfying business needs, the time required to answer relatively simple business questions increases exponentially and IT teams’ workload multiplies.
What methodology should we follow to create data models that are less brittle and susceptible to changes, and at the same time more fluid and dynamic?
A High-Level Introduction to the Corepula Method
The Corepula Method is deeply rooted in the ideas championed by Chris Date and Bill Inmon. It provides a set of guidelines for designing highly fluid and customizable database schemas that can support diverse requirements such as Enterprise Data Warehouse (EDW) and Master Data Management (MDM). The Corepula Method is based on the notion that most data – but not all – will undergo some type of change. Static pieces of information, that which has been defined by the business as unchangeable, should be collected and stored separately. The Corepula Method splits attributes into static and non-static and applies 6NF principles to the non-static attribute group. The resulting schema falls into a hyper-normalized design pattern that helps absorb and amortize various schema changes. Database schemas based on the Corepula Method enjoy the following overall benefits:
- The ability to model enterprise data layers in a way that is conducive to change. Semantic changes, driven by constantly shifting business requirements, can be incorporated into already existing models with relative ease, thus improving the turnaround time for IT deliverables.
- An overall reduction in project costs. Database schemas can be proactively managed and expended well into the future. Less rework is required, allowing IT professionals to focus on code optimization instead of constant schema redesign.
- Well-defined data modeling building blocks that produce predictive, robust, and consistent database schemas. The predictive nature of the resulting database schemas simplifies construction of Extract Transform Load (ETL) layer code, making it cheaper to build and maintain. Schemas share a similar structure and access pattern, and facilitate “build once, reuse multiple times” ETL design patterns, since ETL templates can be built once and reused multiple times throughout the same project.
- Indexing and partitioning scheme guidelines. Because the schemas result in the creation of well-defined and predictive sets of database tables, recommended indexing and partitioning schemes already exist. Physical schema developers must adhere closely to the indexing and partitioning guidelines to produce highly tuned and optimized database systems.
- Natural treatment of NULL attribute values. Unless business requirements explicitly state otherwise, a piece of data with a NULL (or unknown) value must be stored according to the method’s schema. Integration specialists should not invent data. For auditing purposes, a NULL value in the source system must match a NULL value in the method’s schema.
- An insert-only data loading paradigm. Data updates and deletions are not allowed. Insert-only data loading creates a high-octane, extremely efficient ETL process that loads data in parallel.
- Highly efficient storage and complete removal of data redundancy. Storage costs are declining, but are still a substantial part of any IT budget. There is also another, more subtle benefit to the Corepula Method. Some Database Management System (DBMS) vendors are now incorporating raw data size into underlying database licensing costs. By eliminating data redundancies, businesses can potentially save money.
The Corepula Method recognizes that each entity has temporal and non-temporal attributes, and classifies them into their respective attribute groups.
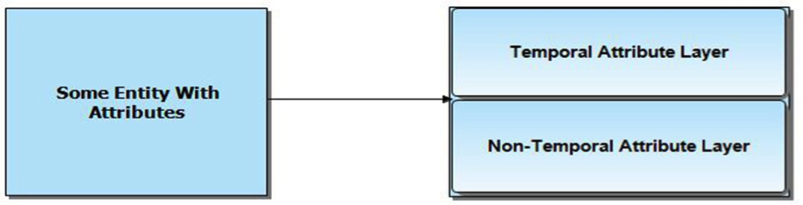
Figure 1: Attribute classification.
During the definitional stage, domain experts classify the attributes of a given entity into temporal and non-temporal attribute groups in preparation for the subsequent modeling stage. This classification is necessary because the attributes in each group are modeled differently. The Corepula Method strategically splits every database entity into four distinct building (or modeling) blocks:
- Core – business entity
- Non-historized – attribute entity
- Historized – attribute entity
- Copula – entity modeling construct whose main task is to store a given entity’s underlying foreign key attributes
Using these predefined building blocks and a set of Corepula Method guidelines, data modelers can construct highly fluid and customizable database schemas. Below is a diagram that illustrates these modeling blocks and the various relationships among them.
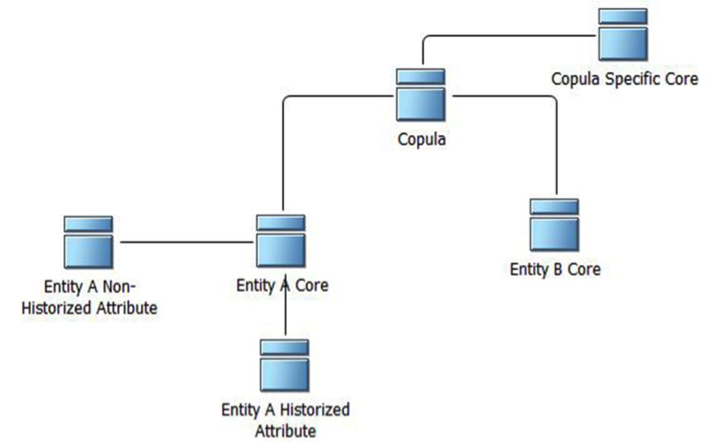
Figure 2: High-level view of the Corepula Method’s modeling constructs.
An Overview of the Core Entity Type
A core entity helps modelers identify the key business concepts that need to be modeled. These core entities can be visualized as abstractions that correspond one-to-one with concrete items in need of modeling. These entities are structured simply, consisting of surrogate key/identifier and a date attribute. The date attribute helps identify the beginning of the time slice for when a particular record came to exist in the source system.
In the diagram below, a SECURITY CORE entity was created as an abstraction for the SECURITY business concept. A SINCE DATE is a temporal attribute that identifies the beginning of the time slice for when a particular source record came into existence. The SECURITY CORE KEY attribute helps uniquely identify each security record; it is system-generated.
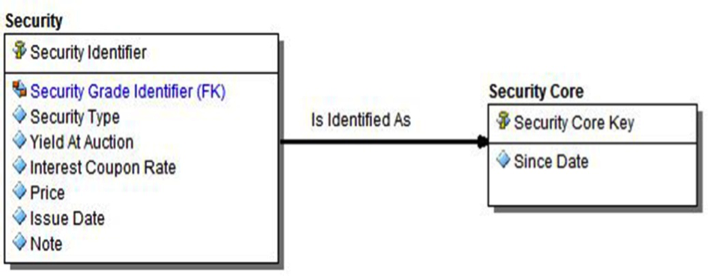
Figure 3: Modeling a CORE entity.
The reasoning behind such a simple and minimalistic core entity design is to keep such structures immune to change. A core entity can be viewed as an interface to a business concept (SECURITY in the above diagram). An interface is a contract that acknowledges that a particular business concept exists and hides the underlying data management complexities from the rest of the data model. As an interface, the core entity never changes and semantic alterations to the underlying business entity have minimal impact on the rest of the database schema. Core entities act as pillars of stability, shielding the rest of the model from the impacts of change. The only way entities can be linked is through core entities and their synthetically generated primary key attributes (SECURITY CORE KEY in our example). If a given entity undergoes a semantic change, that change is localized to a set of non-core entities and strategically managed. Note that every core entity has the same structure, consisting of the two above-mentioned attributes.
Core entities inherit names from their corresponding business counterparts. The entities and CORE KEY attribute names of the corresponding core entities depend on the underlying names of the business concepts being modeled. In our example, the main business concept is SECURITY; we’ve leveraged this name in naming the core entity: SECURITY CORE.
The SINCE DATE attribute is consistently named. It is recommended that data modelers not change the name of this attribute. The resulting simple and predictable core entity structure helps in designing the ETL templates that will eventually be used in loading these same entities with data, once a physical model is deployed. ETL templates, based on database metadata, can be developed once and reused in multiple places throughout the model.
An Overview of the Non-Historized Attribute Entity Type
A non-historized attribute construct stores a set of non-historized attributes. Non-historized attributes are those whose value should never change (at least in the eyes of the business). One creates a pool of non-historized attributes by stripping away all static attributes from the underlying source entity. The final list of non-historized attributes must be approved by the business. Each non-historized entity is directly linked to one and only one core entity type.
From the data management point of view, a source system’s natural keys must be added to the non-historized attribute pool. These natural key attributes play a crucial role in tying together source and Corepula Method-based schema records. In addition, they are leveraged by the resulting ETL process in the record-matching phase to help identify whether a given source record already exists. Attributes such as GENDER CODE, EYE COLOR, and BIRTH DATE are good candidates for being classified as non-historized. The list of non-historized attributes is typically industry and business-specific.
An Overview of the Historized Attribute Entity Type
A historized attribute layer consists of attributes whose underlying values the business expects to change. The rate of change is insignificant. As long as the value of a given attribute has the potential to change, in all likelihood it will change. Such attributes must be identified and grouped together in a stand-alone “historized” pool. In the data-modeling phase, historized attributes are modeled separately and confined to individual, 6NF-compliant entities. All historized attribute entities have a similar structure. This sameness facilitates the creation of reusable ETL templates.
An Overview of the Copula Entity Type
We’ve discussed core entities, as well as how each structure acts as an interface and has a one-to-one correspondence with a concrete business concept. We’ve also defined and explored historized and non-historized attribute types. In this section, we will briefly discuss the last of the Corepula Method’s building blocks: an entity type called a copula. The Corepula Method strips away foreign key attributes from underlying business concepts and stores them separately in copula entities. Below is a list of rules that govern the modeling of copula entities:
- This entity type only stores foreign key links. The exception to this rule is surrogate foreign key attributes (see below).
- The Corepula Method assumes that a set of all copulas’ foreign key attributes uniquely identifies a given copula record, including surrogates.
- Each foreign key attribute must have a value. NULL values are not allowed. Examples in subsequent sections will demonstrate how this can be accomplished when one of the source system’s foreign key attributes is nullable.
- By design, copula entities only store foreign key attributes and cannot have attributes of their own. There is one exception to this rule. When modeling entities whose primary (or alternate) source composite key consists of foreign and non-foreign key attributes, the non-foreign key attributes are treated as surrogate foreign keys and must be added to the resulting copula entity as regular foreign key attributes.
- Each copula entity must be linked to a copula-specific core (called a copula core entity). This makes each copula record historized. Copula-specific core entities are structured the same as other core entity types.
- All copula-specific attributes are linked to this copula-specific core entity. Quite often an intersection entity, in addition to storing foreign key links, has attributes of its own. These attributes are indirectly attached to the copula entity through a copula-specific core entity.
- Copula-specific attributes can be either historized or non-historized.
Tying Things Together: A Complete Example
An example will clarify the key concepts mentioned above. A sample source schema is shown below. Next, we demonstrate all of the necessary steps required to translate it into a corresponding Corepula Method-based schema.
As a first step, to convert any source schema into a Corepula Method-based schema design, we must map key business concepts onto the corresponding core entity types. In this example, we create two core entities (one for each business concept) and name them: CHILD ENTITY CORE and PARENT ENTITY CORE. These core entities encapsulate underlying business concepts and hide potential future semantic changes from the rest of the data model.
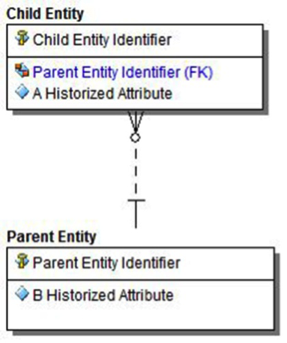
Figure 4: CHILD-PARENT entity schema.
In the second step, with the help of a domain expert, we begin classifying attributes into historized and non-historized attribute pools. This produces the following attribute classifications:
The CHILD ENTITY non-historized attribute group:
- CHILD ENTITY IDENTIFIER, which acts as a Primary Key
The CHILD ENTITY historized attribute group:
- HISTORIZED ATTRIBUTE A
The PARENT ENTITY non-historized attribute group:
- PARENT ENTITY IDENTIFIER, which acts as a Primary Key
The PARENT ENTITY historized attribute group:
- HISTORIZED ATTRIBUTE B
The completed scheme is illustrated in Figure 5. The presence of the foreign key attribute (PARENT ENTITY IDENTIFIER) in the CHILD ENTITY source indicates that we must extract and store this relationship in a stand-alone copula entity (the PARENT CHILD ENTITY COPULA). As discussed above, a copula entity must be linked to a corresponding copula core entity (called the PARENT CHILD ENTITY COPULA CORE in this example). The PARENT CHILD ENTITY COPULA CORE is a copula-specific core entity that can easily accommodate the storage of copula-related attributes, either historized or non-historized. In data modeling, a one-to-many relationship often evolves into a many-to-many relationship. This many-to-many relationship may have attributes of its own. The Corepula Method anticipates such an evolution in entity relationships and has a pre-built mechanism for coping with such modeling situations.
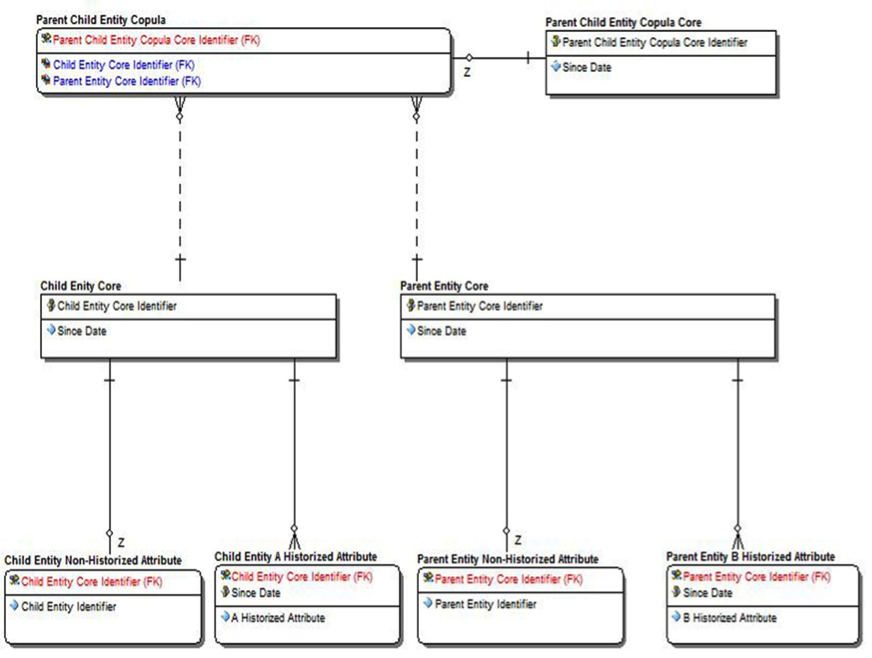
Figure 5: Schema based on the source’s CHILD-PARENT entity schema.
There is another reason why the copula-specific core structure is required. The primary key for a copula entity is provided by a corresponding copula core entity as part of an identifying relationship. For each unique combination of foreign key attributes in the copula entity during a specific time slice, a corresponding copula core entity generates a unique identifier (the COPULA CORE IDENTIFIER). This unique identifier is always dated in the corresponding copula core entity (using the SINCE DATE attribute), and identifies the beginning of the time slice during which a given combination of foreign key attributes existed in the source system. As a result, this mechanism always temporalizes foreign key relationships.
A unique PARENT CHILD ENTITY COPULA CORE.PARENT CHILD ENTITY COPULA CORE IDENTIFIER value will be generated for each combination of CHILD ENTITY CORE IDENTIFIER and PARENT ENTITY CORE IDENTIFIER attributes in the PARENT CHILD ENTITY COPULA entity. The PARENT CHILD ENTITY COPULA CORE.SINCE DATE attribute specifies the beginning of the time slice during which a particular combination of foreign key attributes existed in the source system.
The resulting Corepula Method-based schema has a well-defined and predictable structure.
Each historized entity type has the following set of attributes:
- A CORE IDENTIFIER, which is an identifying link from the underlying core entity,
- A SINCE DATE attribute, and
- An actual attribute that business wants to historize.
All non-historized entities have:
- A CORE IDENTIFIER, which is an identifying link from the underlying core entity, and
- A list of non-historized and static (according to business) attributes.
Similarly, all core entity types have a similar structure:
- A synthetically generated core identifier (CORE KEY), and
- A SINCE DATE attribute.
The copula entity consists of:
- A COPULA CORE IDENTIFIER, which is an identifier from the underlying copula-specific core entity,
- A list of core identifiers from the underlying parent and child “core” entities (these are foreign key links), and
- OPTIONAL surrogate foreign key attribute(s).
This structural sameness and consistency has numerous benefits. It drastically shortens the ETL development time and encourages the use (and re-use) of ETL templates. ETL templates can be developed once and re-used in other parts of the project. Indexing and partitioning scheme rules can be formalized, removing guesswork when creating indexing and partitioning schemes in the physical database layer.
Conclusion
If your existing data model can no longer accommodate ongoing business needs, take the time to review and assess the overall direction of your project. The same design pattern used on one successful data modeling implementation cannot be blindly carried over to another modeling project because the underlying business requirements are almost always different. A solid knowledge of various data modeling methodologies, coupled with a clear understanding of business desires and needs, will lead to robust, fluid database schemas that avoid common pitfalls.
The Corepula Method is an open source modeling technique that can be easily prototyped in the modeling environment of your choice. Don’t be afraid to try something new. Apply the knowledge you gained from this article, and take action. Use your existing data model as a baseline and see for yourself if the Corepula Method’s model will handle your ongoing business needs.
