
We are in the era of graphs. Graphs are hot. Why? Flexibility is one strong driver: heterogeneous data, integrating new data sources, and analytics all require flexibility. Graphs deliver it in spades.
Over the last few years, a number of new graph databases came to market. As we start the next decade, dare we say “the semantic twenties,” vendors that never before mentioned graphs are starting to position their products and solutions as graphs or graph-based
The two main graph data models are: Property Graphs and Knowledge (RDF) Graphs. This three part article provides a comparison of the strengths and limitations of Knowledge Graphs versus Property Graphs and guidance on their respective capabilities. Given its scope, the article is being published in three parts, each with a distinct focus, but collectively providing an integrated view on this important topic.
Part I provides an overview of the two main graph models noted above along with illustrations of their similarities and differences in graph diagrams of the same example content.
Part II builds on the terms and concepts introduced in Part I and explores the difference in the meaning of some key terms used in both Property Graphs and Knowledge Graphs. Key terms used in these respective graph models actually mean very different things, and this is important to understand to avoid confusion.
Part III concludes this white paper by discussing some important topics at a high-level, including: Graph analytics and separation / composition of graphs, limitations of Property Graphs, the inherent semantics built-in to Knowledge (RDF) Graphs and some Guidance for Moving from a Property Graph to a Knowledge Graph.
Similarities, Differences and Some Guidance on Capabilities
We are in the era of graphs. Graphs are hot. Why? Flexibility is one strong driver—heterogeneous data, integrating new data sources, and analytics all require flexibility. Graphs deliver it in spades.
Over the last few years, a number of new graph databases came to market. As we start the next decade, dare we say, “the semantic twenties,” we also see vendors who have never before mentioned graphs start to position their products and solutions as graphs or graph-based.
Graph databases are one thing, but “Knowledge Graphs” are an even hotter topic. We are often asked to explain Knowledge Graphs.
- What are they?
- Why and where are they useful?
- How are they different from “just graphs?”
Today, there are two main graph data models:
- Property Graphs (also known as Labeled Property Graphs)
- RDF Graphs (Resource Description Framework)
Other graph data models are possible as well, but over 90% of the implementations use one of these two models (see Sidebar 1). We will start by describing each of them.
| When we say that over 90% of implementations use either Property Graphs or RDG Graphs, we mean implementations that use some kind of an industry recognized graph data model. Due to the current expansive popularity of graphs, many vendors are starting to represent their technology as graph based, when in reality they use a home-grown object repository that can resemble certain aspects of graphs. This white paper is not intended to cover such implementations since they do not use a recognized data model and, thus, there is no basis for comparison. If you are considering a technology that claims to be graph based, our recommendation is to always ask what graph data model it uses. |
Property Graphs
While there are core commonalities in property graph implementations, there is no true standard property graph data model. Each implementation of a Property Graph is, therefore, somewhat different. In the following, we will focus our discussion on the characteristics that are common for any property graph database. The most well-known implementation, which popularized property graphs as a concept, is the Neo4J graph database. At minimum, everything stated here is true for Neo4J. Other examples of property graph implementations are TigerGraph and Titan. MS SQL Graph is based on the same underlying concept, but it currently offers more limited capabilities than either Neo4J or some of the other products that are using the property graph data model.
Generally, the property graph data model consists of three elements:
- Nodes: The entities in the graph. Nodes can be tagged with zero to many text labels representing their type. Nodes are also called vertices.
- Edges: The directed links between nodes. Edges are also called relationships. The “from node” of a relationship is called the source node. The “to node” is called the target node. Each edge has a type. While edges are directed, they can be navigated and queried in either direction.
- Properties: The key-value pairs associated with a node or with an edge.
If you have worked with object databases, you will find it easy to understand the Property Graph data model. It is really more of an object data model than a graph data model.
- Nodes are entities
- Edges are relationships
- Properties are attributes
Both, entities, and relationships can have attributes.
Property values can have data types. Supported data types depend on the vendor. For example, Neo4j data types are similar, but not identical, to Java language data types.
Figure 1 shows a fragment of a property graph with data about actors, directors and films or TV programs they worked on. Nodes are represented as ovals. For example, the node with ID 123, as we can see from its properties, represents Tom Hanks. Node labels are shown in dark blue. Node 123’s labels are Person, Actor and Director.
Relationships are depicted as grey arrows. Each relationship has a single type that is shown in red. Properties are shown in the rounded rectangles with the gold background. Properties are connected to nodes and relationships that they belong to using red arrows.

Click on the image to see a larger version.
A key part of any data model is having a query language available for working with it. After all, users need to have a way to access and manipulate the data in the graph. No industry standard query language exists for property graphs. Instead, each database offers their own, unique query language that is incompatible with others:
- Neo4J offers Cypher also known as CQL—its own query language that, to some extent, took SQL as an inspiration.
- TigerGraph offers GSQL—its own query language that also took SQL as an inspiration.
- MS SQL Graph has their own extension to SQL to support graph query.
- Some vendors, in addition to their own query language, also implement some subset of Cypher. For example, SAP Hana offers its own extensions to SQL and its own GraphScript language plus they support a subset of Cypher.
There is also Apache TinkerPop—an open source graph computing framework that is integrated with some property graph and RDF graph databases. It offers the Gremlin language which is more of an API language than a query language.
A key requirement for working with any data model is the ability to reference nodes, properties and relationships (edges). In the case of property graphs, internally, nodes and edges have IDs. IDs are assigned by a database and are internal to a database. Referencing is done by using text strings—node labels, relationship types, and property names.
The fastest way to load bulk data is by importing a text file. For property graph data, there is no standard serialization (a way to represent graph data as a text file). It is typical for a property graph vendor to define a CSV format that users should follow in order to prepare files for bulk load.
RDF Graphs
RDF graphs use a standard graph data model. The standard for the RDFtechnology stack is managed by the World Wide Web consortium (W3C), the same standards body that manages HTML, XML, and many other web standards. Every database that supports RDF is expected to support the model in the same way.
The RDF graph data model basically consists of two elements:
- Nodes, the vertices in a graph. Nodes can be resources with unique identifiers, or they can be “literals” with values that are strings, integers, etc.
- Edges, the directed links between nodes. Edges are also called predicates and/or properties. The “from node” of an edge is called the subject. The “to node” is called the object. Two nodes connected by an edge form a subject-predicate-object statement, also known as a Triple or a Triple Statement. While edges are directed, they can be navigated and queried in either direction.
Everything in an RDF graph is called a resource. “Edge” and “Node” are just the roles played by a resource in a given statement. Fundamentally in RDF, there is no difference between resources playing an edge role and resources playing a node role. An edge in one statement can be a node in another. We will give examples of this in the diagrams that follow that will make this core idea clearer.
There is a standard query language for RDF Graphs called SPARQL. It is both, a full featured query language and an HTTP protocol making it possible to send query requests to endpoints over HTTP. A key part of the RDF standard is the definition of serializations. The most commonly used serialization format is called Turtle. There is also a JSON serialization called JSON-LD as well as an XML serialization. All RDF databases are able to export and import graph content in standard serializations making it easy and seamless to interchange data.
Built-in Semantics
The RDF Data Model provides a richer, semantically consistent foundation over property graphs. Let’s see how a graph we showed earlier (Figure 1) is represented as an RDF Graph (Figure 2).
Note that the diagrams depict relationships using the recommended conventions of the property graph and RDF graph communities. Relationships in Property Graphs are typically capitalized with multiple words joined together by an underscore as in ACTED_IN. Relationships (or any property) in RDF graphs are typically identified using the lower camel case convention as in ex:actedIn. In both cases, these are simply recommended practices, not a “must have.” The graph in Figure 2 appears larger than the property graph in Figure 1 because all literal values are also depicted as nodes in the graph. All nodes are depicted as rounded rectangles with the light-yellow background.
AN RDF GRAPH WITH THE SAME DATA ABOUT ACTORS, DIRECTORS, FILMS OR TV PROGRAMS
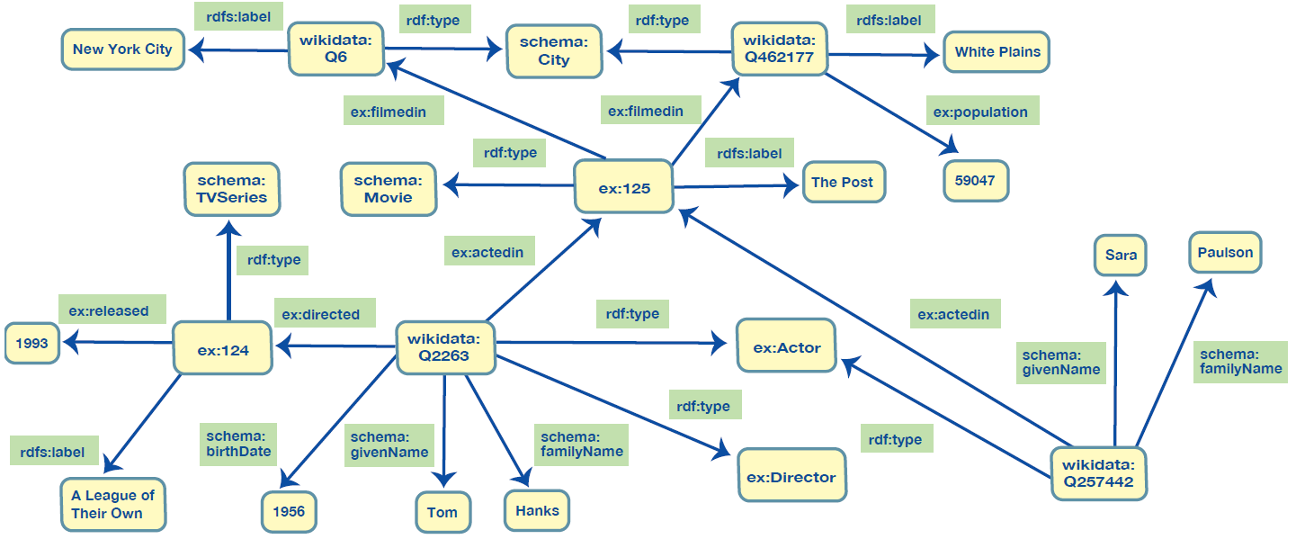
Click on the image to see a larger version.
When visualizing RDF Graph data, it is common not to show literal values as nodes in order to make a cleaner and simpler looking diagram. That said, from the data structure perspective, they are part of the graph just like any other node. The only difference is that they can’t serve as a source node i.e., a subject of a statement. They can only be targets or objects.
Although this makes the diagrams larger and busier, we believe it helps to illustrate the differences between the two data models and the implications of these differences on knowledge capture, graph design and graph evolution.
Literal values in an RDF Graph can have datatypes. The datatypes are taken from the XML Schema (e.g., xsd:string, xsd:integer, etc.) Text values can also have language tags to support internationalization of data. For example, instead of a single value for rdfs:label for New York City we could have multiple values such as:
- “New York City” xsd:string @en
- “Nueva York” xsd:string @sp
Identifier is a very important concept for RDF graphs. Every non-literal node is assigned an identifier—typically, a URI/IRI. Local, non-URI identifiers are possible, but rarely used because they are not interoperable. Globally unique identifiers bring many benefits to graph data models. An RDF- based solution can auto-generate URIs based on selected URI construction rules. Alternatively, when adding data (e.g., loading a serialized file), users can provide URIs that they want to use.
The URIs identifying nodes are displayed in the diagram using qualified names, commonly called Qname notation. To form a Qname, the namespace part of the URI is abbreviated using a prefix. For example, “rdf:” and “rdfs:” represent the built-in standard namespaces w3.org/1999/02/22-rdf-syntax-ns# and w3.org/2000/01/rdf-schema#, respectively.
These namespaces define the semantics (the model behind) the RDF Data model. The built-in resources such as rdf:type carry semantics that are defined in the standard. The built-in resources can be used as either nodes or edges in a graph. For an example of such semantics in edges, see the predicates (aka properties) rdf:type and rdfs:label in the RDF graph diagram in Figure 2. For an example of such semantics in nodes, see the node rdfs:Class that is the object of the rdf:type predicate in the diagram shown in Figure 3.
A key differentiator that we will be introducing is how the underlying model (schema) is represented in the same way as the data. Just to serve as a primer, “rdf:type” is a predicate used to connect a resource with a class it belongs to; “rdfs:label” is used to provide a display name for a resource. The uniformity of the data model makes RDF Graphs more easily evolvable and gives them more flexibility compared to Property Graphs.
Enrichment Through Composition
With the inherent composability of RDF Graphs, when two nodes have the same URI, they are automatically merged. This means that you can load different files and their content will be joined together forming a larger and more interesting graph.

Click on the image to see a larger version.
Examples of compos-ability, can be found in the use of schema.org, and wikidata. Schema.org is a namespace jointly setup by Google, Bing, and Yahoo to create and support a common set of schemas for structured data markup. The prefix ‘schema:’ stands for schema.org. Similarly, ‘wikidata:’ is a namespace used to provide DBPedia data in a structured, knowledge graph format. It provides a number of predicates and classes with commonly agreed and understood semantics. In the example, we are using schema:givenName, schema:- familyName and schema:City. In this way, graphs developed by different organizations can link and share common semantics.
When organizations create their own knowledge graphs, they may use URIs of community defined resources as well as create resources for which they “mint” their own URIs. In the latter case, they would normally use a web domain they own as a namespace because a reference to a resource in an RDF Graph is expected to resolve and return information about it. In our example, in addition to using URIs from RDF, RDFS, Wikidata and Schema.org, we are also demonstrating the use of our own URIs. These URIs have ‘ex:’ prefix—to illustrate that they are provided as an example.
For human users browsing data, a reference to a resource URI will typically return information about a resource presented as a web page. For APIs making a call, information can be returned in JSON, any standard serialization of RDF or any other machine processable format.
The part of the Qname after the prefix is called a local name. A local name could be formed by using a display label if it can uniquely identify a resource within a name-space and is considered immutable. It could also be formed using a counter; much like in relational databases a record gets the next sequential number as its ID. It could also be formed using a machine-generated random ID or be based on the value of one or more predicates that can establish a locally unique identity.
