 As the world of data management grows and changes, the roles and participants in data ecosystems must adapt. With the convergence of several influences – big data, self-service analytics, self-service data preparation tools, data science practices, etc. – we’re moving rapidly into an age of data curators and data shoppers. Data shopper describes anyone who is seeking data to meet information or analytics needs. Data curator is a role that is responsible for overseeing a collection of data assets and making it available to and findable by data shoppers.
As the world of data management grows and changes, the roles and participants in data ecosystems must adapt. With the convergence of several influences – big data, self-service analytics, self-service data preparation tools, data science practices, etc. – we’re moving rapidly into an age of data curators and data shoppers. Data shopper describes anyone who is seeking data to meet information or analytics needs. Data curator is a role that is responsible for overseeing a collection of data assets and making it available to and findable by data shoppers.
The word “curated” is used frequently today. The traditional use of the word is associated with collections of artifacts in a museum and works of art in a gallery. More recently, we’ve started to use the term to describe managed collections of many kinds, such as curated content at a website and curated music collections available from streaming services.
Curated data is a collection of datasets selected and managed to meet the needs and interests of a specific group of people. Every enterprise has groups of people with interest in collections of data. Note that the focus here is datasets – files, tables, etc. – that can be accessed and analyzed. The distinction between “collections of data” and “collections of datasets” is subtle but significant.
There are two essential components to making curated data a reality – data curating, and data cataloging. Curated data introduces a new data management role – the Data Curator. Curating data creates need for a new tool – the Data Catalog.
Data Curation – What, Why, and Who?
In the not too distant past nearly all of the data used by a business was created within the enterprise – transaction data from OLTP systems subsequently transformed to populate data warehouses. Adoption of big data changed that reality with an increasing share of data coming from external sources and, at least in an informal sense, becoming curated data. It is important to recognize that not all curated data is generated externally. Internal processes also create datasets that are curated. The trend toward data curation accelerates as the proportion of external data grows, and as datasets that blend internal and external data (data lake, data sandbox, etc.) gain attention and interest. Analytics processes may also generate new datasets that are subject to curation.
To keep pace with accelerating data trends, we need to shift from informal curating to data curation that is planned, organized, and managed. Data Curator needs to be recognized as an important data management role with responsibilities to:
- Evaluate quality, veracity, and usefulness of datasets
- Select the datasets that constitute a curated data collection
- Describe datasets sufficiently to inform about content and usefulness
- Annotate datasets with additional information of value
- Categorize datasets, providing context and making them easily found
- Catalog datasets with metadata to search, locate, understand, access, and use them
- Hear user feedback and apply it to better inform future users of the data
- Archive datasets that are rarely accessed but should not be permanently deleted
- Preserve dataset quality and accessibility through the duration of their useful lifespan
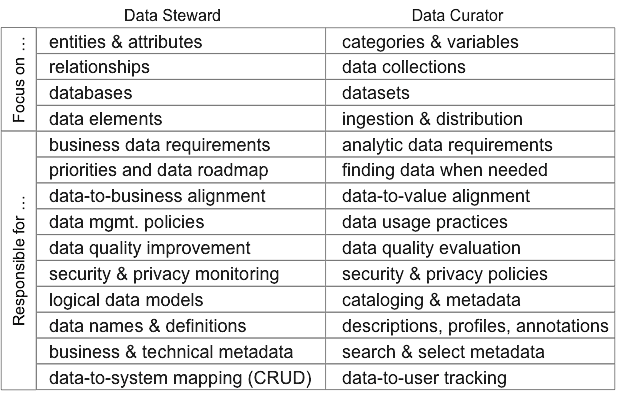
The roles of Data Steward and Data Curator are related and somewhat overlapping. Stewards and curators working together maximizes the value of a data resource. Stewards and curators have different focuses. Curators collect and manage datasets (tables, files, etc.). Stewards focus at an abstract level on data concepts (subjects, entities, relationships) and at the implementation level on data elements. This table contrasts the difference in focus of stewards and curators.
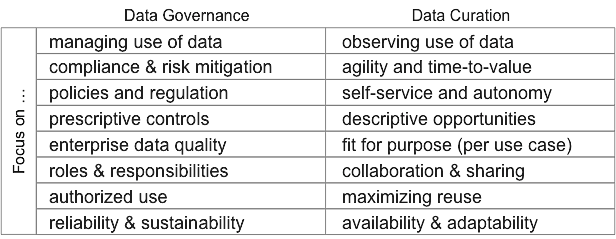
Collaboration of data governance and data curation is essential. Data curation does not replace data governance, but extends and complements it. This table compares and contrasts governance and curation perspectives.
Data Cataloging – What, Why, and How?
Data Cataloging is a data curation activity that involves collecting, verifying, and publishing metadata about datasets that are available to a community of users. Data analysis, machine learning, and crowd-sourced knowledge may be combined to collect comprehensive metadata. A Data Catalog is a collection of metadata, combined with data management and search tools, that helps analysts and other data users to find the data that they need. The data catalog serves as an inventory of available data and provides information to evaluate its fitness for intended use. Data Cataloging encompasses all of the tasks performed to build and maintain a data catalog.
Everyone has worked with data dictionaries and metadata repositories. You might question how a data catalog is different from dictionaries and metadata. A data catalog is a metadata repository, but it is a different kind of repository that is designed to facilitate people finding and selecting datasets that meet their specific needs. This table compares features and functions of dictionaries, metadata repositories, and data catalogs.
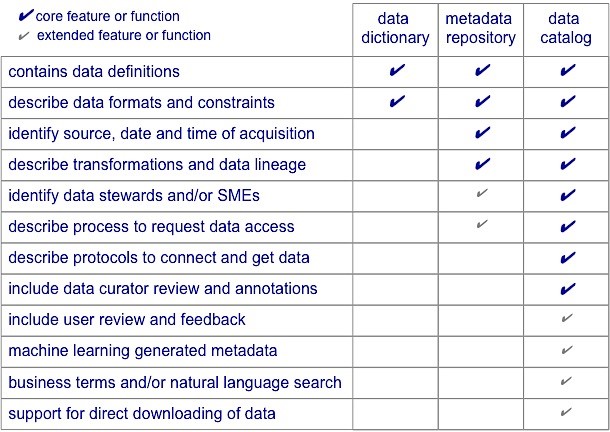
It is also important to recognize the differences of orientation and focus among data dictionaries, metadata repositories, and data catalogs. Each has its role and purpose. All are important but they vary in scope and they do different things. Dictionaries are typically application oriented. Metadata repositories are often tool-specific and proprietary. The data catalog is ideally an integrated single source of information about curated datasets. Interactivity and advanced search capabilities help to weave the data catalog into the fabric of analytics processes.
Data cataloging tools are quickly becoming available and mature. Without intent to endorse any tools or to provide an exhaustive list, I’ll name a few for those interested in exploring the range of tools. Alation, Attivio, Microsoft Azure, Tamr, Waterline Data, and Zaloni Mica provide a representative cross-section of the data catalog software market.
A Data Marketplace – A Vision of the Future
We work in an age of self-service analytics. IT organizations can’t (and probably shouldn’t) provide all of the data that is needed by the ever-increasing numbers of people who analyze data. But today’s business and data analysts are often working blind. They don’t have visibility into the datasets that exist, the contents of those datasets, and the quality and usefulness of each. As a result, they spend too much time finding data, understanding data, and recreating datasets that already exist. In the worst scenarios they work with inadequate and poorly understood datasets resulting in inadequate and incorrect analysis.
Many different sources say that a typical business or data analyst spends about 80% of their time finding and fixing data, with only 20% spent on analyzing data and finding business meaning. Cataloging and Curation are the keys to reversing these numbers.
Imagine a Data Marketplace – Amazon for Data Shoppers – with natural language search capabilities, descriptions of datasets, Data Curator annotations, ratings and reviews by others who have used the datasets, and opportunity to post your own ratings and reviews. Curating, cataloging, and the marketplace are the shape of the future where business and data analysts can work with their eyes wide open.
