 A powerful new general purpose semantic hierarchical processor model for semantic processing can supersede SQL using advanced natural operations. This new processing is accurate, flexible useful, and simple to use. This is accomplished by using the new hierarchical Left Link operation presented in this document, and not the older Cartesian product model.
A powerful new general purpose semantic hierarchical processor model for semantic processing can supersede SQL using advanced natural operations. This new processing is accurate, flexible useful, and simple to use. This is accomplished by using the new hierarchical Left Link operation presented in this document, and not the older Cartesian product model.
This paper describes how this hierarchical processing can be naturally used to support a multipath semantic hierarchical processor. This also supports dynamically querying across multiple hierarchical pathways. These advanced capabilities will be shown through working examples and descriptions that show how these hierarchical and semantic features operate together. An advantage of this is that it supports hierarchical operations by naturally utilizing the semantic processing.
—– —– —–
1. Introduction
The new semantic hierarchical processing model presented within, supports and produces many advanced features and capabilities. These include significant ways to perform the hierarchical data modeling and proven principled hierarchical processing using an advanced natural hierarchical Left Link operation. The older Left Join has been replaced with a Left Link operation that is using a virtual table linking to replace the current Cartesian product, its data replication problems, and single table limitations. This creates a powerful hierarchical data model using tables hierarchically and separately linked for a flexible advantage.
The new Left Link operation supports hierarchical semantic processing. Its Left Link processing follows the older Left Join hierarchical processing, allowing the replacement of the standard Left Join with the new Left Link operation. This uses multiple linked tables with separated table linking. This keeps the tables physically separated for maximum flexibility.
New advancements include: the new Left Link operation; flexible multipath hierarchical and semantic processing; dynamic network processing across hierarchical pathways; structure-aware processing for extended dynamic processing; advanced new lowest common ancestor (LCA) processing for deriving more meaning from hierarchical processing; naturally increased data value as the structure grows; data driven structure processing; and support for linking anywhere below the lower level root to fully support mashups.
By supplanting the standard Cartesian product operation, a more efficient and flexible relational Left Link hierarchical processing is used. The initial development of this new Left Link operation will be for a single user system, followed with a multi-user system.
2. Defining the Hierarchical Data Model
Dynamically defining the desired relational hierarchical data model using the new Left Link is shown in the bullets below in Figure 1. It defines and controls the limits of processing within the desired hierarchical structure. This processing operates following natural hierarchical, relational and semantic principles. These are further controlled by funneling all and only data modeling operations through the Left Link operation.
The Left Link inherited its hierarchical processing from the Left Join operation making it hierarchical in nature. It naturally supports hierarchical data modeling and processing that is more flexible than standard relational processing. It is made possible by naturally using the new Left Link operations to support hierarchical processing through a series of hierarchical Left Links that unify into a single virtually linked hierarchical structure. This is naturally utilized in the hierarchical structure being processed because the semantics naturally grow as more Left Links are used. The Left Link’s operation is shown in Figure 1 below. It demonstrates how to build a hierarchical data structure using the new Left Link operation.

Figure 1. Left Link data modeling definition
The last bulleted item above defines a multipath hierarchical structure. The hierarchical data structure definition above in Figure 1 shows how to data model the more powerful Left Link operation. The newer ON clause is used instead of the older WHERE clause making this new Left Link operation more flexible and precise using multiple ON clauses instead of being limited to one WHERE clause.
The new Left Link operation operates hierarchically by naturally preserving data from unmatched rows and preserving data only on the left side, naturally increasing any data value. This supports the relational data model using the powerful hierarchical Left Link operation to model the desired hierarchical structure. This naturally passes the semantic data along in the hierarchical data structure being processed. As the structure grows, the semantics grow. An example of hierarchical data modeling is shown above in Figure 1. [5]
3. Hierarchical or Flat Structure Differences
Standard processing for SQL produced a flat table processing. When multiple tables are used, the result also produced a flat Cartesian product. This generates unnecessary replicated data, which can cause accuracy and summary problems. The top SELECT statement shown in Figure 2 below is joining tables A, B, C which produces a Cartesian product that shows node A occurring two times instead of once in this very simple example. This shows a standard join operation generating replicated data that remains in place causing problems and limited to only one combined table. This is totally avoided in the Left Link.
In the bottom SELECT clause in Figure 2 below, a new Left Link operation has replaced the older Left Join. This enables a hierarchical structure to be used instead of a standard flat table processing. In the top SELECT statement in Figure 2, the Left Join is affected by the Cartesian product and the lower Left Link is not. This allows it to separately link tables. This hierarchical structure is defined by a new Left Link operation which links structures together in separate pieces rather than joining structures together into one single contiguous flat structure. Any unlinked single tables can still be used independently.
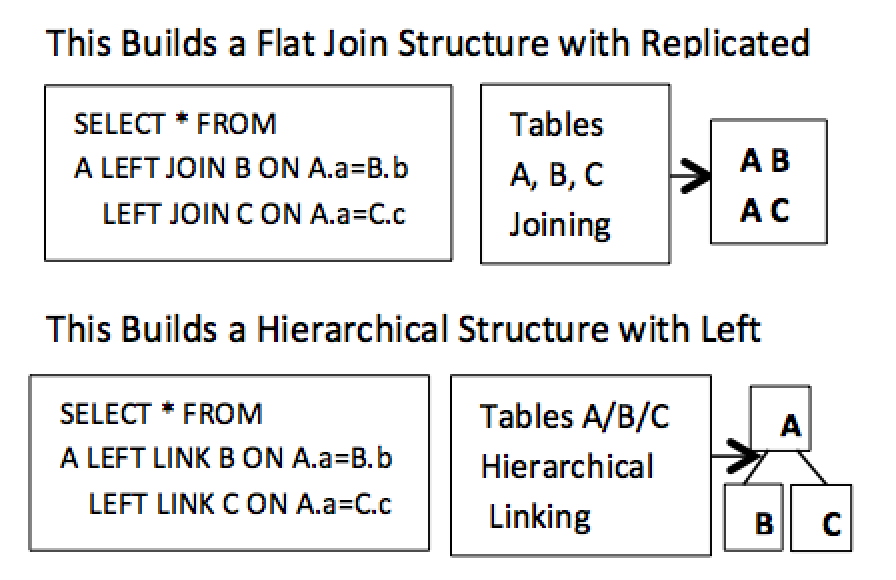
Figure 2. New hierarchical processing support
4. Relational Hierarchical Processing
Shown in Figures 3.1 and 3.2 below is how data modeling can be naturally performed in extended ways. It demonstrates how hierarchical data processing using Left Links to perform data modeling can be directly processed using only hierarchical Left Links. This uses a subset of hierarchical processing that supports an advanced hierarchical processing that can utilize the hierarchical data modeling structure and semantics in the data, creating more value than is captured. [6]
This produces a powerful hierarchical processing with new capabilities derived by limiting processing to only Left Links. This always produces valid hierarchical data structures. Hierarchical processing is controlled by a set of standard hierarchical principles defined in the data model in Figure 1. Breaking any of these hierarchical processing standards will automatically trigger an error condition, such as detecting pathways merging together, which is hierarchically invalid.
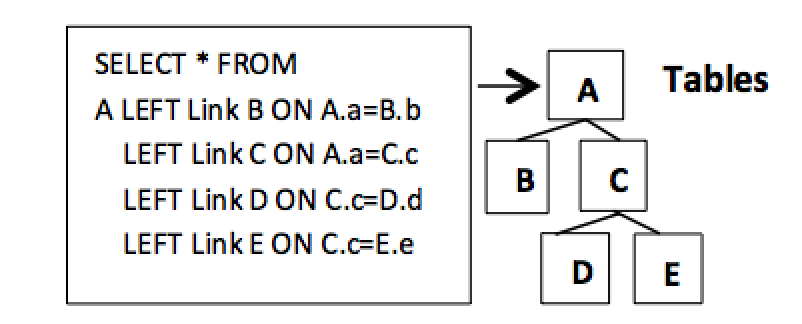
Figure 3.1. Hierarchical data model and structure
In Figure 2 above, deleteing table C will also remove tables D and E. In Figure 3.2 below, the lower data model, D is now under the A table, deleting table D will now delete table E. In Figure 3.2 below, the data definition demonstrates this more diverse multi-way structures offering more choices. Notice in table A that the relational data definition can validly specify more than two paths coming from a single node. This is a natural extention allowing more data modeling choices.
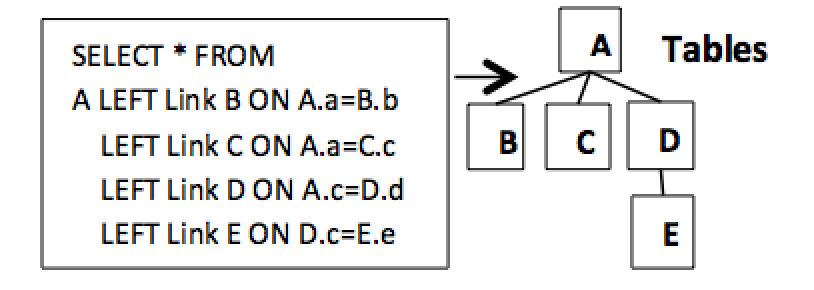
Figure 3.2. Hierarchical data structure 2
Standard SQL used flat structures with no semantics associated with it. The data modeling shown in Figures 3.1 and 3.2 above produces powerful hierarchical processing models by using self-describing hierarchical processing semantics. It naturally uses an accurate form of hierarchical Left links. This has two advantages. It naturally carries the hierarchical structure and semantic information, and can access it and make it available as the hierarchical structure grows.
5. Multipath Hierarchical Processing
These hierarchical structures are built with Left Links. This allows references of separate tables along multiple pathways, as shown in Figure 4 below. This multipath hierarchical structure also establishes the required foundation to support WHERE clauses across pathways.
There is new support for multiple data occurrence table groupings. This is shown in C1 and C2 below in Figure 4. Each has related but separate data occurrence groupings for additional flexibility organizing tables. Their data can be retrieved all at once or navigated using Get Next operations for more user control.
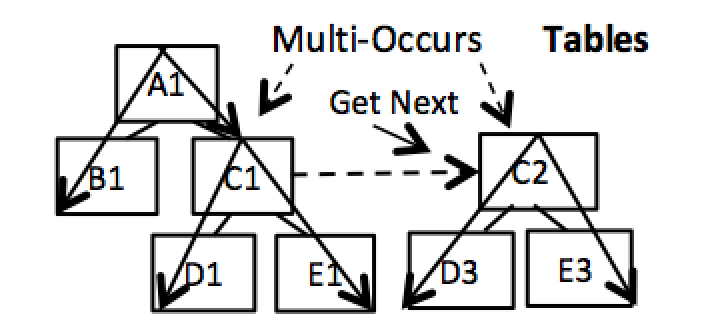
Figure 4. Multipath processing
6. Different WHERE Selection Choices
There are two choices of WHERE clause filtering. The first is the standard SELECT clause that also includes a WHERE clause. The second choice is a new selection choice where there is no SELECT clause but there is only a WHERE clause to process. In this case, the previous SELECT clause is used and appended to the current new WHERE clause to use. This can be repeated as often as necessary to process new WHERE clauses by only specifying the new WHERE clause, as shown directly below.
1) SELECT * FROM ABC WHERE C.c=B.b
2) Followed by: WHERE C.c= 10 OR …
6.1 Removing Replicated Data Values
Even though there is now a new Left Link operation that is fully hierarchical, it may be necessary to use the flat Left Join to always generate a single table from multiple tables with replicated data generated that could cause some replicated data problems. This can be alleviated after the tables are joined, expanded with replicated data, internally tracked to locate replicated data values marked “R” and removed. This is demonstrated below in Figure 5.
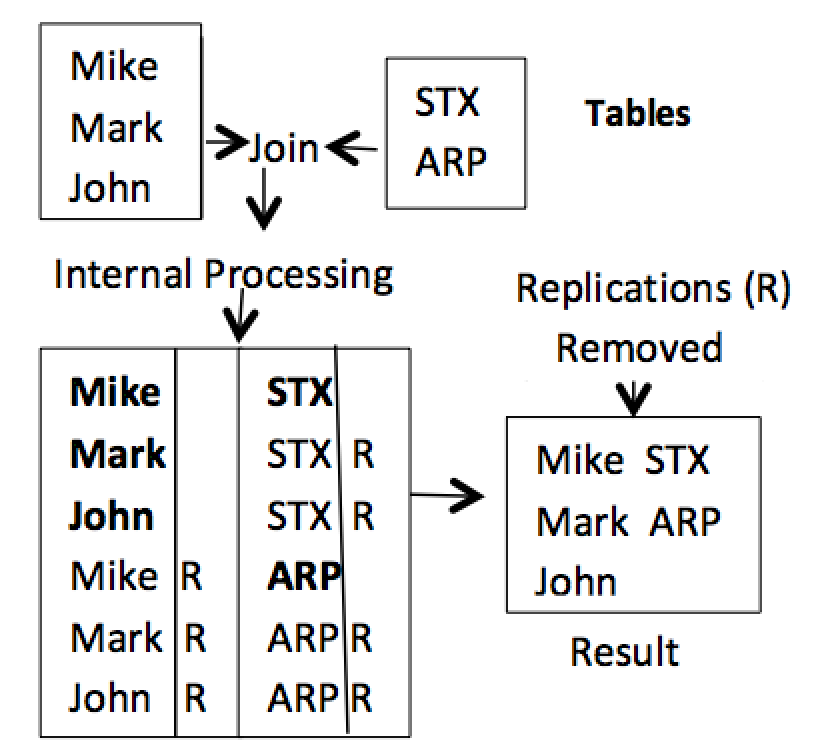
Figure 5. Removing data replications
The result shown above is produced by removing the “R” flagged rows on both sides to produce the result that can be fully accurate for correct vertical processing is needed and can support Min, Max, Sum, AVG etc., to cover all possible choices.
7. Structure-Aware Internal Processing
Structure-aware processing uses Data Structure Extraction (DSE), shown in Figure 6 below, to know the active data structure at all times. The data structure is determined by dynamically reverse engineering the Left Link operation in memory. With the data structure known, dynamic new operations become available. [12]
With knowledge of the data structures that were not previously available, this new extended dynamic level of processing can now work more naturally with the Structure-Aware interface to simplify interfacing to unknown uses such as supporting XML generation, shown in Figure 7 below.
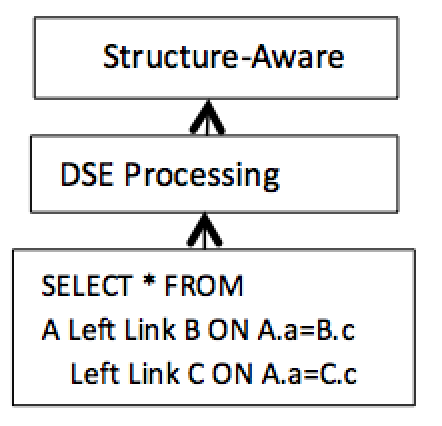
Figure 6. Structure-aware processing
8. Structure-Aware Extended Processing
Structure-aware processing can be used for extended dynamic processing for dynamic generation at run time shown in Figure 7 below. In this example, read bottom up, the active data structure Meta data definition becomes more available for unknown requests such as XML shown directly below. [10]
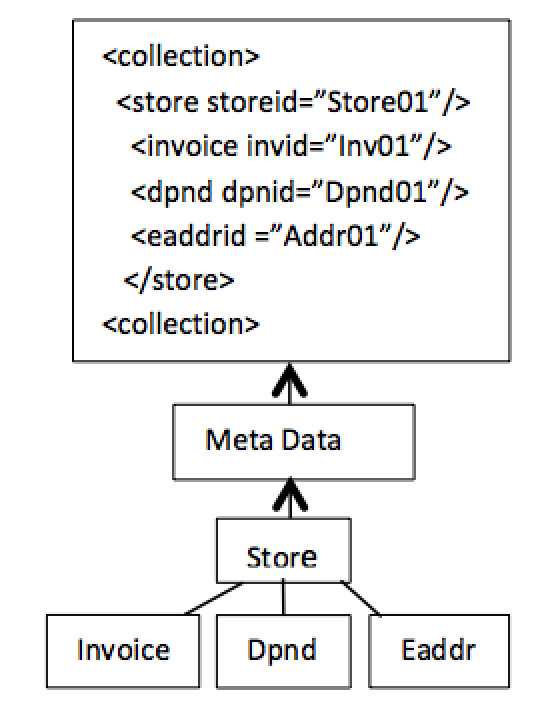
Figure 7. Dynamic structure-aware uses
9. Hierarchical Node Promotion
This is a very useful capability; the SELECT list below can be automatically changed when there is no reference of node C in Figure 8 below. This dynamically affects the result. This is performed here using data aggregation, hierarchical node promotion, and node removal. This can be performed automatically, shown below in Figure 8.
Data aggregation can be seen in the result by the node promotion of node D over missing node C replacing missing node C in memory with node D. Node E is not referenced and for this reason is not accessed or shown at all. This produces a natural optimization of node E.

Figure 8. Node promotion
10. Linking Below Root (Mashup)
Linking below a lower level view root is possible when the view has been or is materialized into a single structure when invoked. This is an advanced new capability. Before linking to the lower hierarchical structure, the lower structure view XYZ shown below in Figure 9 has already been created. Having been materialized into a solid structure, it can be linked to any node in the lower structure. This is very flexible and powerful.
For example, from the B node of view ABC to the Y node of view XYZ creating the data structure on the right side. This is built from the statement: SELECT * FROM ABC LEFT LINK XYZ ON B.b=Y.y. This allows joining to the XYZ view from any of its matching nodes while maintaining the X node as its root, since it is the only result that is hierarchically valid. This is also known as a mashup because it allows the lower level structure to be linked to at any node point in the lower structure. This is shown in Figure 9 below.
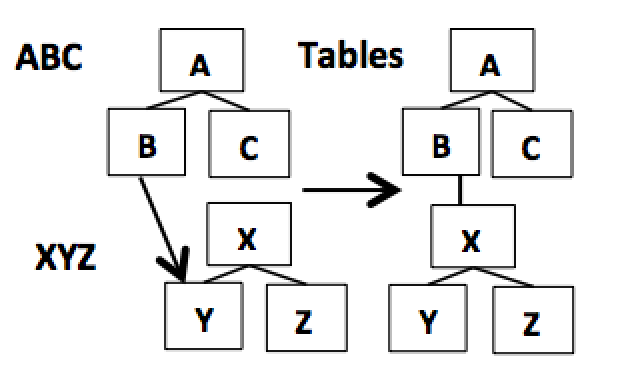
Figure 9. Supporting mashups
11. Data Driven Processing
Attaching an extra test to the SELECT statement ON clause can turn it into a data driven statement. In this example, the “AND X.x=4 OR >9” in bold print below controls whether view XYZ is attached or not attached automatically. Only if the X.x value in the XYZ view equals 4 is the Left Link performed. If not, the link is not performed and the join is not performed. This is shown here:
SELECT * FROM ABC Left Link XYX ON A.a=X.x AND X.x=4 OR>9.
12. Usual Order of Specifying Operations
The following operations numbered below in Figure 10 indicate the best order to derive and utilize results from this new hierarchical processing. Designing and connecting the hierarchical node structure enables data to be stored into a structure. Retrieving the stored data is possible at any time by specifying the coordinates. Increasing the column size is specified by specifying the new size.

Figure 10. Best order of operations
13. List of Table Processing Operations
Linking relational tables using the Left Link produces a hierarchical structure with the tables hierarchically linked; Moving a table to another location will replace the data if the table is not empty; Copying a table to another table location will append data if there is already data in the table; Appending data to a table will add to the bottom of the table or resume where left off from; Deleting tables will remove the tables specified; Deleting data will delete data and keep an empty table; Displaying the table will display the entire table or only parts of the table specified; Extending data columns is performed automatically when the table needs to be extended; Removing columns is specified by the row range to be deleted; Searching the table for certain conditions is performed by the search command; Summing data will total the columns specified; Min and max finds the lowest and highest column values; Sum and AVG find the column total and average; and Grouping and ordering will rearrange data; Replicated data values are not introduced, assuring correct results. These procedures will need refinement over time.

Figure 11. Table and data operations
14. What the New Left Link Can Do
The new Left Link operation supports multiple tables. Importantly, these tables can be hierarchically linked with any number of hierarchically linked tables such as from table A in Figure 12 below. One structure has been defined as shown, but more can be defined as needed. This is shown in the Select statement showing four tables (A,B,C,E) linked into a structure. Separate, unlinked table D can be used independently. Multi-table support and full table processing found in Figure 11 above make an extremely powerful combination.
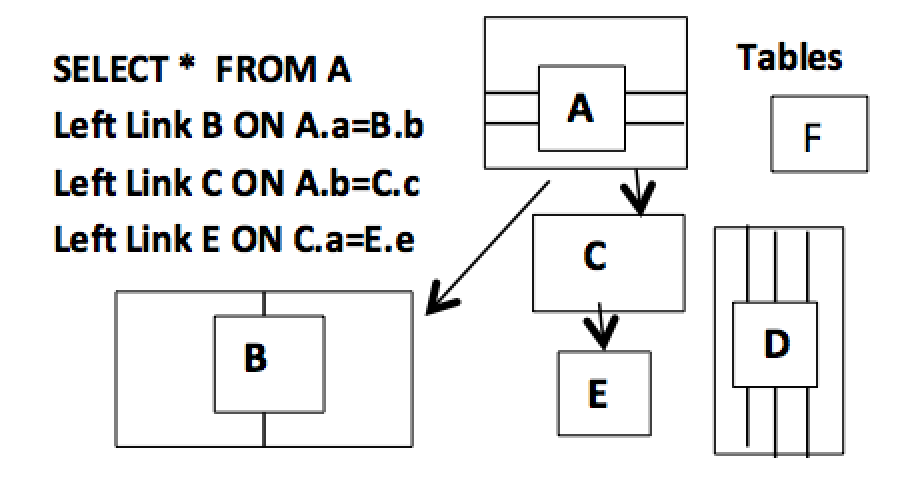
Figure 12. What the new Left Link can do
We can see from Figure 12 that there can be separate tables and multiple hierarchical structures. These can be used at the same time, or remain separate. Rows and columns are separately manipulated. This means there is no problem with dynamically and virtually linking tables into structures. Figure 12 shows these flexible structures. This is an example showing how easy it is to construct very complex structures, modifying them and adding to them.
15. Lowest Common Ancestor (LCA) Processing
This is an expanded use of the LCA term and operation for a new area of future exploration of Lowest Common Ancestor processing. This LCA processing is for use in multipath hierarchical processing. It demonstrates multipath hierarchical processing coming together in a more meaningful way. Some examples follow: [7]
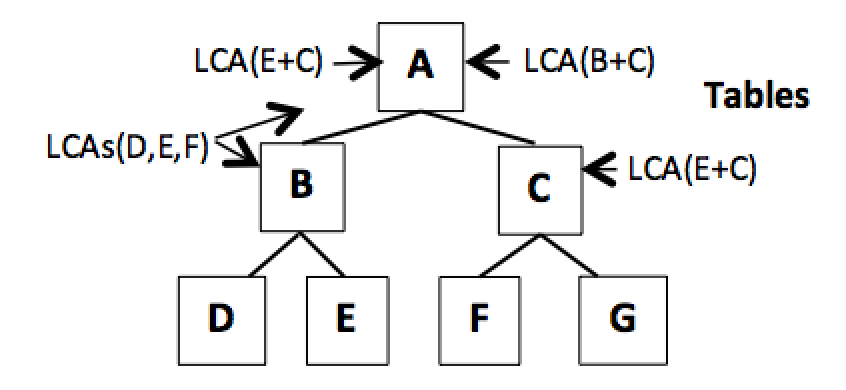
Figure 13. New LCA processing
Selecting tables B and C produces an LCA at A. Selecting tables D & F, or E & C produces an LCA at A. Selecting tables D, E & F produces multiple and stacked LCAs for both A and B. So multiple and stacked LCAs are possible. LCAs operate naturally by automatically using the smallest LCA range possible. D+E is smaller but stronger, E+F is much wider but weaker. D+E extends up to B, while E+F extends all the way up to A automatically. The smaller the range of the LCA, the more significant the value is. This makes LCA(B+C) more meaningful than LCA(E+C), which is more spread out. This is shown in Figure 13 above.
Let’s also look at selecting data based across pathways:

Figure 14. Selecting data across pathways
This cross path logic also uses LCA processing to keep the hierarchical processing meaningful across pathways. During processing, whenever two points on different pathways in the structure require being associated in anyway such as selecting data from one path based on data from another path, the LCA can determine the structure’s shortest range or area between the two points to produce the most meaningful result. The smaller the range, the more meaningful it is.
16. Transformations: Restructuring and Reshaping
Restructuring operates by taking the structure apart and rebuilding it in a different order or way using different relationships available to change the structure. This can derive new meaning and semantics. [9]
Reshaping is a molding process by shifting pieces of the structure around. This means that there are no limits to what the new structure can be. This allows any-to-any structure transforms. This preserves the semantics applied to the structure while changing the shape. [9]
17. Why Hierarchical Structures are so Useful
Hierarchical structures have tables that act as nodes. These hierarchical structures preserve correctness. They do not allow invalid structures, and do not support ambiguous structures. Hierarchical structures can access any node in a data structure. Hierarchical structures are persistent. WHERE queries are temporary. This can be expanded to allow multiple different WHERE clause queries to be sequentially processed.
18. Conclusion
The semantic Left Link and its natural hierarchical processing can significantly advance processing in many new and powerful ways. By replacing SQL with only natural hierarchical Left Links, its data modeling capabilities and uses are greatly increased while using naturally correct relational processing. Hierarchical structure growth can naturally increase semantics. This paper has shown how Left Links can be used to become a significantly more powerful semantic process while also limiting some operations to derive more power.
These new capabilities are found in relational hierarchical processing. They naturally support advanced features not known or used before in this natural hierarchical processing, such as using the new Left Link to support a powerful hierarchical data modeling. Another capability supports a flexible structure-aware processing to extend operations.
The following capabilities were shown through working examples and descriptions that show or explain how these new features work naturally. These capabilities demonstrate that these features can produce a new hierarchical processing with the following Left Link capabilities:
New Features and Capabilities:
- Processing is principled, accurate & simpler to use
- Operates are at a more powerful hierarchical level
- New Left Link replaces Left Join and Cartesian product
- Joining structures can naturally increases semantics
- Hierarchical structures create more semantic value
- Structure-aware & Data Structure Extraction
- Automatic data driven processing
- Linking below lower level root to support mashups
- Automatic node promotion
- Lowest Common Ancestor (LCA) processing
- Automatic replicated data removal
- Restructuring and reshaping
References
[1] Abiteboul, S., Quering Semi-structured Data, Procedings of the International Conference on Database Theory,1997
[2] M. David. Advanced Standard SQL Dynamic Structured Data Modeling. Artech House, 2013.
[3] M. David. ANSI SQL Can Combine Advantages and Principles of Relational and Hierarchical Data Processing. Database Journal, Jan 2011.
[4] M. David. SQL Peer-to-Peer Dynamic Structured Data Processing Collaboration. SOA World Magazine, June 2011.
[5] M. David. Naturally Increasing Data Value with Hierarchical Structures. XML Magazine, March 2011.
[6] M. David. Extending SQL’s Inherent Hierarchical Processing Operation. Database Journal, Nov, 2010.
[7] M. David. The Power of SQL’s Inherent Multipath LCA Hierarchical Processing. Database Journal, May 20, 2010.
[8] M. David. Automatic Full Parallel Processing of Hierarchical SQL Queries. DevX, Feb 22, 2009.
[9] M. David. Performing Hierarchical Restructuring Using SQL. DevX, April 2009.
[10] M. David. ANSI SQL Hierarchical Processing Can Integrate XML. Sigmod Record, Vol. 32. March 2003.
[11] M. David. Advanced ANSI Data Modeling and Structure Processing. Artech House Publishers, 1999.
[12] M David. Method of Data Structure Extraction for Computer Systems Operating Under the ANSI 92 SQL2 Outer Join Protocol. US Patent 5625812 A. Apr 1997
[13] M. David. Advanced Capabilties of the Outer Join. ACM Sigmod Record, Vol. 21, No. 1, March 1992.
[14] M. David. The Outer Limits of the Relational Join. 370/390 DATA BASE Management, Oct 1991.
[15] A. Eisenberg, J Melton. SQL/XML Making Good Progress. SIGMOD Record, Vol. 31, No.2, June 2002.
[16] M. Fernandez, A. Morishima, D. Suciu. Efficient Evaluation of XML Middle-ware Queries. Proceedings of the 2001 ACM SIGMOD International Conference on Management of Data, May 2001.
[17] J. Shanmugasundaram et al. A General Technique for Querying XML Documents using a Relational Database System. SIGMOD Record, Vol. 30, No. 3, Sept. 2001.
