
DevOps. Lean. Kaizen. What do all these disciplines have in common? Continuous improvement. Simply put, these systems pursue progress through a proven process. They make testing and learning a part of that process. And they continuously improve by integrating new insights into future cycles.
Borne of the Japanese business philosophy, kaizen is most often associated with Toyota today. The car manufacturer leverages kaizen to improve productivity. Using this methodology, teams will test new processes, monitor performance, and adjust based on results.
The goal of DataOps is to create predictable delivery and change management of data and all data-related artifacts. DataOps practices help organizations overcome challenges caused by fragmented teams and processes and delays in delivering data in consumable forms.
So, how does data governance relate to DataOps? Data governance is a key data management process. For this reason, it needs to operate on the same DevOps/continuous improvement principles. But how would this work?
Continuous Improvement Applied to Data Governance
For data governance to continuously improve, practitioners need to think of data governance as a cyclical process. This process embeds continuous improvement into the system through steps that monitor and measure performance to (1) glean insights and (2) integrate those lessons into the governance system.
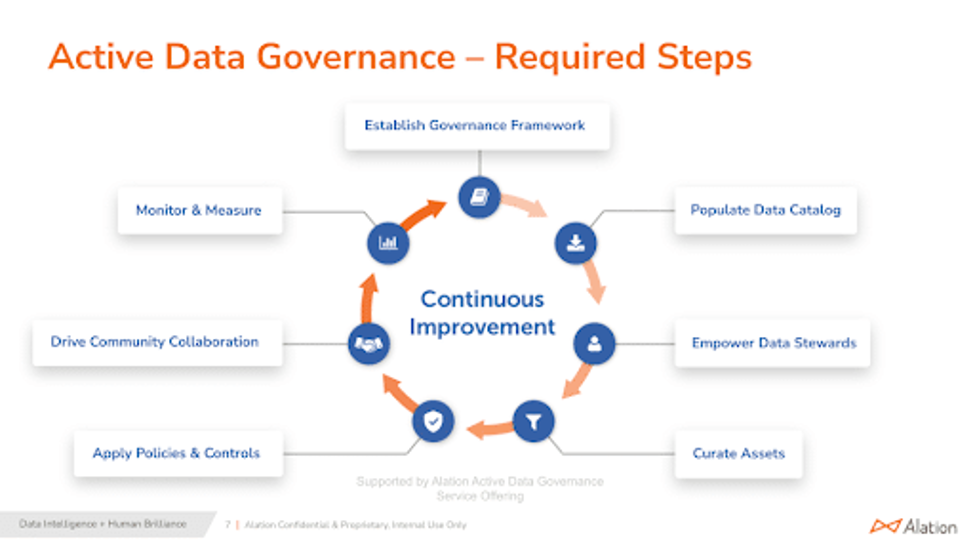
Data governance is a continuous process, not a “one and done” task. Data is “always on,” living, and in constant motion and thus, the act of governing it is never done. In fact, the governance process should get better and better over time. For example, previously identified data stewards should become natural candidates for new and related assets as those assets are discovered. And with AI and machine learning helping along the way, less and less work will be required in successive cycles.
Like other elements within a DataOps process, data governance should become less and less human-intensive over time. Using the above continuous improvement cycle as the model, let’s look at each element and what can be accomplished during its portion of the process.
Steps to Continuous Improvement Data Governance
Establish Governance Framework
An effective data governance process aligns people, process, and technology in advance. In other words, leaders must clarify how things will be governed, who is responsible, and how success or failure will be measured.
These target commitments, expressed as policies and standards, should define completeness, quality, accuracy, timeliness, usage, access, and classifications for both metadata and data.
Traditionally, governance programs suffered from a reliance on dusty and inaccessible policy documents, which were organically meant to influence everyday business activities. These documents were, for the most part, overlooked, which is why traditional governance failed.
Modern governance is more effective because it takes a different approach, integrating policies into user workflow so people can see if the data they seek is bound by any regulations. This is why strategic policies must be linked to actionable implementation, in the form of data control rules, which connect to a variety of technology tools and platforms. As successive cycles create new insights, these rules can be adjusted accordingly.
Populate the Data Catalog
Governance requires knowledge and content. Historically, this knowledge has been gathered by assembling experts, stewards, and SMEs who identify key assets on a one-time basis. But today, the complexity and ongoing transformation of a modern enterprise make this approach unsustainable.
In an approach based on continuous improvement, organizations must identify key assets so their metadata can be ingested and analyzed. This process translates technical labels into natural language, making abbreviated, cryptic, and technical terms understandable to the wider community. As a goal, business stewards should have the tools to measure the gap consistently and easily between the governance standards and existing performance. This gap perpetuates an active cycle of assignment and continuous curation.
Empower Business Stewards
As implementation of governance begins for each business area, it’s critical to recognize and identify business stewards. As a goal, stewards should sit inside the business area and play a critical role in driving awareness, onboarding, moderating, and guiding participation. They are accountable for ensuring the targets in the policies and standards are maintained. Historically, governance teams have tasked stewards with primary responsibility for this enforcement work — they are the so-called policy enforcement officials of data.
However, in the modern era, there’s too much data and far too much change for stewards to keep up. To address this problem, potential stewards need to be discovered based on their current contributions and actual use of data. Those who use the data most often will most likely truly understand the data, so the goal is to build a community of stewards based on who knows the data best. Stewards and governance teams must build and foster a community of willing participants who are recognized and rewarded for making data governance a key piece of the organization’s culture.
Curate Assets
Curation is the governance subprocess of populating and refining the attributes of an asset; these details grant users greater trust through insight and knowledge. One objective of the governance process is to maintain the required attributes for each asset, as stipulated in the policies and standards. The business steward is accountable for operating by standards and making those standards known to top users and other volunteers. The key is to have training and recognition in place, so participants realize they have an ownership stake in the quality of the content.
Apply Policies and Controls
Once overarching enterprise data policies and standards are established, the next step is to implement data controls. This involves the creation of rules that are applied within a data source for the purpose of adjusting entitlements and monitoring. The rules are specific instances of the standards for each data source environment and are bi-directionally synced with the catalog. They could be created in the data source or a data governance application and then related to the enterprise policies and standards.
Drive Community Collaboration
A continuous governance process will create a self-perpetuating cycle of engagement and adoption. Community is the key to driving a data culture that scales while following quality norms and enforcing behaviors and policies. After new community members are onboarded and trained, they participate by sharing their knowledge on data quality and appropriate use of data. This increases the breadth, depth, and quality of information, which in turn attracts more new community members.
Monitor and Measure Curation
To establish a data governance process that improves over time, you need monitoring and measuring tools to understand how well the governance process is working. Business stewards should measure curation progress against the policies and standards. Data leaders also need to measure whether data usage conforms to policies and compliance standards.
Parting Words — No data governance process is a walk in the park, but a process built on continuous improvement will transform your data processes and allow you to establish a DataOps framework. For many, this may be a new way of thinking. But those who are open to it will find it transformative. It is time we move up the success rates for using data and data governance.
The original article appeared on Alation’s blog post, “How to Ensure Continuous Improvement With Data Governance“.
