
In the cloud-era, should you store your corporate data in Cosmos DB on Azure, Cloud Spanner on the Google Cloud Platform, or in the Amazon Quantum Ledger? The overwhelming number of options today for storing and managing data in the cloud makes it tough for database experts and architects to design adequate solutions. However, they can overcome this challenge by following a three-step approach based on these questions:
- 1. What is a fitting database type?
- 2. Which deployment model is adequate?
- 3. What are the exact service features?
In the following, we explain the questions in detail.
Database Types – How to Store and How to Manage the Data
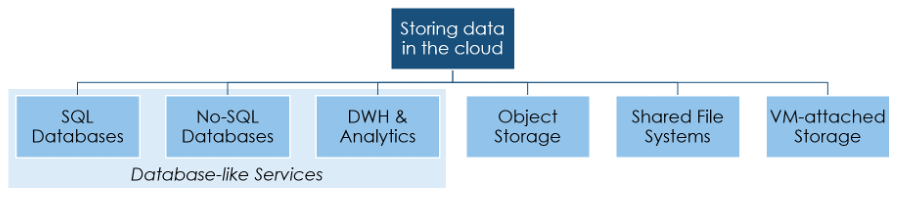
The big cloud players offer a large variety of technologies for storing data including database solutions for the cloud. First, all of them provide relational databases. Examples are Amazon RDS or Microsoft SQL Server on Virtual Machines. They are designed for the typical online-transaction workload. Second, all of them also offer No-SQL databases such as Azure Cosmos DB supporting document and graph data or Google Cloud Datastore. Third, there are data warehouse and big data solutions such as Google Big Query (an SQL Data Warehouse) or the Hadoop-based Azure Data Lake Storage Gen2. There is often a mix of proprietary and open-source technologies. However, the basic decision whether a solution requires a relational or a NoSQL database, a data warehouse respectively big data technology, or a mixture – is the same as known from the on-premises world. Once the decision is made, only very few technology options remain.
Storing Data in the Cloud
Click on image for larger view
However, databases are not the only option to store data, neither in the cloud nor in the on-premises world. The cloud providers offer file shares (e.g., AWS Elastic File Service or Amazon FSx for Windows File server) as well. They allow applications to store data in files and to share and exchange information with other applications. For this purpose, AWS provides the Elastic File Service for Linux respectively Amazon FSx for Windows File server. Furthermore, virtual machines need a local “disk,” storage attached to a virtual machine. The cloud providers brand these services giving them names such as AWS Elastic Block Storage. Such fancy new names for existing concepts can confuse newcomers even though the concepts are well-known.
Finally, the cloud popularized object storage technology. The best known is probably AWS S3. In the cloud, binary large objects such as pictures or documents are stored in object storage. The same applies to log data, i.e., massive numbers of small files. Object storage handles large data sets even in the petabytes range efficiently. Managing and identifying relevant objects bases on two concepts: globally unique identifiers and (highly customizable) metadata. This metadata allows describing the objects in detail and querying for the exactly relevant ones.
Deployment Models
The cloud changes the work distribution between internal IT staff and IT service providers respectively the cloud providers. Responsibilities are clear in many areas, but there are variants when it comes to running the data management infrastructure of an organization. The deployment model decides, for example, who patches the software or the operating system and who ensures scalability.
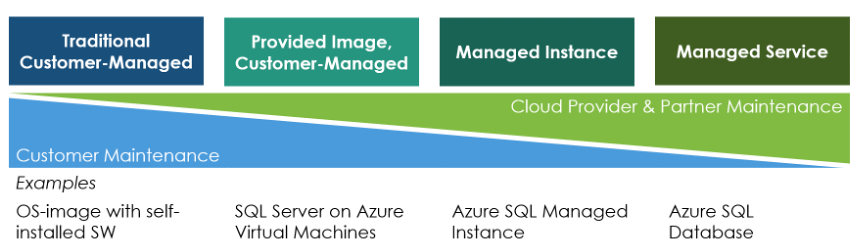
In the traditional customer-managed deployment model, a database administrator (DBA) of the customer deploys infrastructure-as-a-service components: virtual machines, storage, etc. Next, the DBA uploads the installation files to his VMs in the cloud. They start the installation routine for the database software and configures it afterward. During the operation phase, the DBA installs patches, monitor the stability, or adds missing storage. In short, in this deployment model, a database administrator has the same task as in the on-premises world.
The provided-image, customer-managed deployment option is popular with 3rd party software vendors. The vendors can offer ready-to-use images of their software via the marketplace of the public cloud providers. This reduces dramatically the time for setting up and configuring the software. Furthermore, all new installations have always the latest patch-level. However, afterward, during operations, the database administrators perform the same tasks as before: updating and patching, monitoring the stability and performance, adding storage, etc.
A managed database instance shifts more work to the cloud provider. Customers get a ready-to-run installation plus the cloud provider operates the instance. The cloud provider is responsible for the operational stability and for securing the application, e.g., by deploying the newest security patches. Still, the customer chooses the sizing of the database and the underlying infrastructure. If the customer wants to scale horizontally by running multiple database instances, he has to ensure that applications can take advantage of them.
Managed database instances, as well as the deployment models discussed before, still allow for traditional CPU-based software licensing. Depending on the database vendor, the cloud environment, and the exact deployment model, customers can reuse their on-premises licenses in the cloud, thereby protecting their earlier investment.
The last variant is the managed service deployment model. The cloud provider ensures the availability of the service and additionally scalability. Customers do not have to make any sizing decisions. There is no need to reconfigure the managed service if the workload increases from 3 SQL queries per hour to 1000 SQL queries per minute and then drops to 30 queries per minute. Whether the cloud provider requires hundreds of servers to manage the workload or only one, this is transparent to the customer. Managed services are often charged consumption-based, e.g., based on the number of submitted operations or the amount of data read and transferred.
The four deployment models have different strengths. Managed services minimize engineering and operational work for IT departments. They are easy to implement for greenfield applications, but result in high vendor lock-in. Managed services can also result in extra work when moving legacy applications to the cloud. Small feature variations between the cloud-managed database service and the previously used on-premises software might require code adaptions – something known from release upgrades or switching database software vendors. In such cases, lift and shift can be used to get the application in the cloud: move the existing application and their databases (more or less) unchanged to virtual machines in the cloud. The deployment model for the database is then traditional customer-managed on a customer-managed virtual machine or a managed database instance from the cloud provider. Lift and shift is a good choice when organizations want to shut down their on-premises data center and, therefore, have to move many applications and their databases within a short period to the cloud.
Options in Azure Cloud
Click on image for larger view
Service Options
The database type and the deployment model are the important initial decisions. Afterward, there is one last challenge: choosing suitable configuration options.
The AWS S3 object storage, for example, can be deployed as S3 standard with 99.999999999% durability and 99.99% of availability per year. S3 One Zone IA comes with the same durability, but only 99.5% availability. There is also an S3 Glacier option for archiving etc. Google CloudSQL can be configured with read-replicas, e.g., in the same or a different availability zone.
In general, cloud services come with many options, often allowing for a better fine-tuning of solution architectures than traditional IT departments. The latter can, in theory, tune every parameter. In reality, most IT departments or IT service providers just offer one, two, or maybe three service level agreement options for storage or virtual machines. In contrast, the many options in the cloud can complicate finding a good or optimal configuration because there are simply too many. The main point, however, is that these decisions are at the end of the architectural design process. No architect should get into such details before the database type and the deployment model are defined.
The Conclusion
The public cloud providers offer various types of databases, deployment models, and further configuration options such as replication strategies and uptime-guarantees. The underlying trend is that cloud providers offer (and want to sell) managed services. Managed services make routine admin jobs such as installation and patch management on the customer side obsolete. Still, there are more traditional deployment models where customers continue to manage their databases (partially) themselves. What might sound complex and overwhelming can be streamlined and simplified with a three-step process: choose the database type, choose the deployment model, choose the service options – in this order. This simplifies your architectural design process and leads to better solution architectures.
