
In the September issue of TDAN.com, Anthony Algmin denounced Data Catalogs as a “1980’s solution to a 2020’s problem.” Wow! Really?!
What is the state of data science today? As I state in my book, The Data Catalog: Sherlock Holmes Sleuthing for Data Analytics and in many articles, 80% (or more) of a data analyst’s and a data scientist’s time is spent looking for data and associated tasks. All the data scientists I know, both at my current company and others, agree. Data is not organized, not curated, not managed, very distributed, redundant, inconsistent, undocumented, etc. Where to start? Where to look? And when you find a data set, how do you know it is any good and well suited for your needs?
“1-800-GIMME THAT DATA”
Mr. Algmin’s main criticism of data catalogs is that it is a separate product from that with which you are going to use to do the work. He is proposing that you “lose the interface” and have the data catalog functionality embedded in the technology that you are using to build your model (or whatever it is you are building or using the data for). I see this in several different ways:
- This assumes that the intended consumer is allowed access to the underlying data. Many times, they must request access from a data owner or steward. The data catalog helps with this by connecting the intended consumer directly with the granting authority. In this case, therefore, there is an intended break between the search for metadata and the actual use of the data.
- Some data catalog products come with data prep and/or query capability within the tool itself, so you don’t have to necessarily leave the catalog’s interface—you can get to the data right away, from within the catalog itself. The difficulty level of these products varies; most cater to business people whose knowledge of SQL or other query languages is limited, and therefore they provide a wizard-like interface which walks the user through each step of query creation. Even experienced users appreciate the simple interface, enabling them to write queries quickly without a lot of manual coding and troubleshooting. In this case, the data catalog does provide the means to get to the data right away.
- Many tools have APIs that enable you to create the link between the catalog and other tools yourself. These APIs can help you create “catalog as a service” which can invoke search capabilities from your other tools or workbenches.
It is only a matter of time before data catalog vendors will enable more “catalog as a service” capabilities or interfaces with data science workbenches and other tools that Mr. Algmin alludes to that do the actual work.
Data Management & The Catalog Interface
Data analysts, however, are not the only ones who would use the catalog; data management personnel and data architects also must understand and manage the data. They are doing their “actual work” right in the data catalog product. The catalog interface is often well suited for data governance and data architecture. A single interface can provide many data management functions in one platform, “under one roof.” For many, it is the place where their actual work is done, and they don’t need to leave the interface at all. They have a unified data management platform with all the functions in one application.
In Defense of the Catalog Interface
Most tools’ catalog interfaces provide many helpful features that together provide the context behind the data. The interface has many visual features that are certainly not vintage 1980’s. For example, many data catalog products have data quality metrics built in, which show dashboards of an asset’s quality on many of the “data quality dimensions.”[1] These dashboards can be visible to the user and can help them determine if the data is suitable for their purposes. See Figure 1 from Collibra.
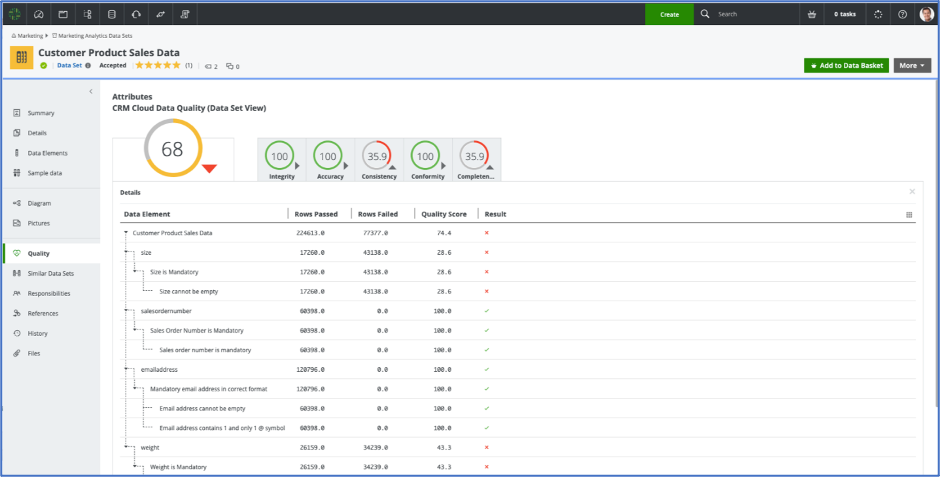
Click on the image to see a larger version.
Data Lineage
Data lineage is an extremely important feature of data catalogs; the products vary in how they perform it and how deep the lineage goes. One of my government sponsors felt data lineage was critical to their understanding, especially the visual depiction of the lineage. The data catalog’s data lineage diagrams tell the whole “back story” of the data: where it comes from, where it’s going, how “good” it is (based on whatever quality metrics are relevant), and some products even show the level of protection in the lineage diagram. The interface is important because it displays a visual diagram of the data flow along with descriptive metadata. See Figure 2 from Informatica which shows column-to-column mappings as data flows from one system to another, from source to warehouse or data lake. Notice that the actual transformations can also be shown for a given column.
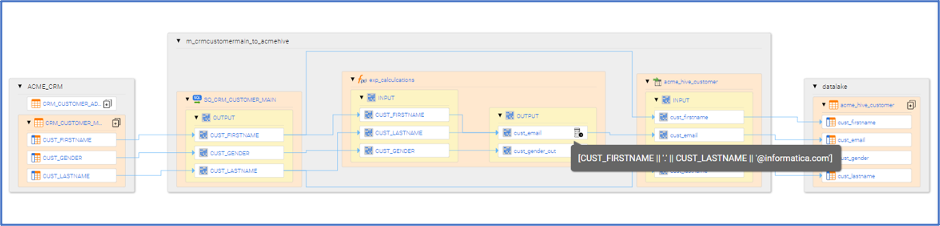
Showing a Transformation
Click on the image to see a larger version.
Integration with Reports
Most data catalog products have integration with Tableau and other visualization tools built in. A report is an “asset type” managed like any other asset, and a picture of the report can be shown right in the asset page in the catalog; see Figure 3 from Informatica. Some catalog tools allow the Tableau application to be invoked right from the catalog with a simple click. The catalog is not just a “stand alone affair”!
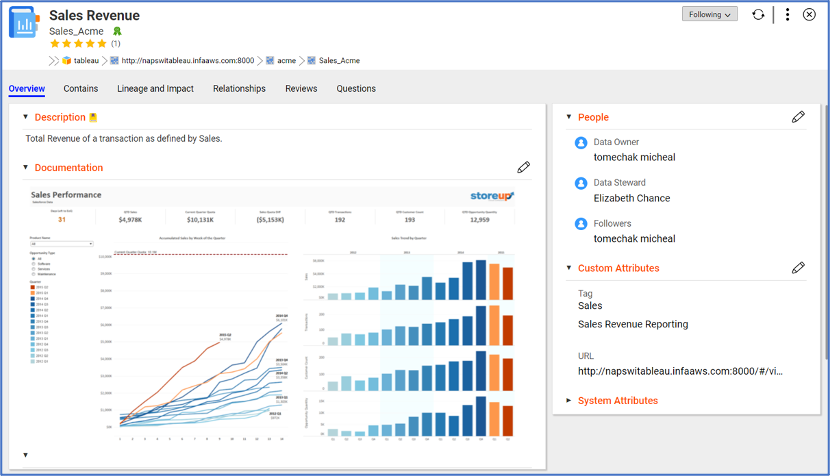
Click on the image to see a larger version.
Data Profiling
Data profiling as a discipline has been with us for a very long time, since the 1990’s. It has been used by smart data warehouse practitioners and data migration/integration projects to avoid the “load, code and explode” syndrome. You would create ETL to move and transform the data, and lo and behold! The code bombs because there is an anomaly hiding in the data that you didn’t know was there. Data profiling displays helpful statistics that tell you if your data adheres to expectations, such as discovering patterns, the percent complete (number/% NULLs in a field), etc. Some data is system-generated and therefore the field names are no help to indicate what data is in a column. Data profiling is a huge benefit and adds a lot of knowledge to catalog metadata. Empowered and augmented with Machine Learning, the catalog can make educated guesses as to what the data contains, especially helpful in fields with cryptic names. Figure 4 from the Hitachi Vantara Lumada Data Catalog (formerly known as Waterline) shows the educated guesses in dotted red boxes along with the probability that the guess is correct. Do you have email addresses in a name field? Notice how the field CV56 looks at first glance to be a name field but it actually contains some email addresses.
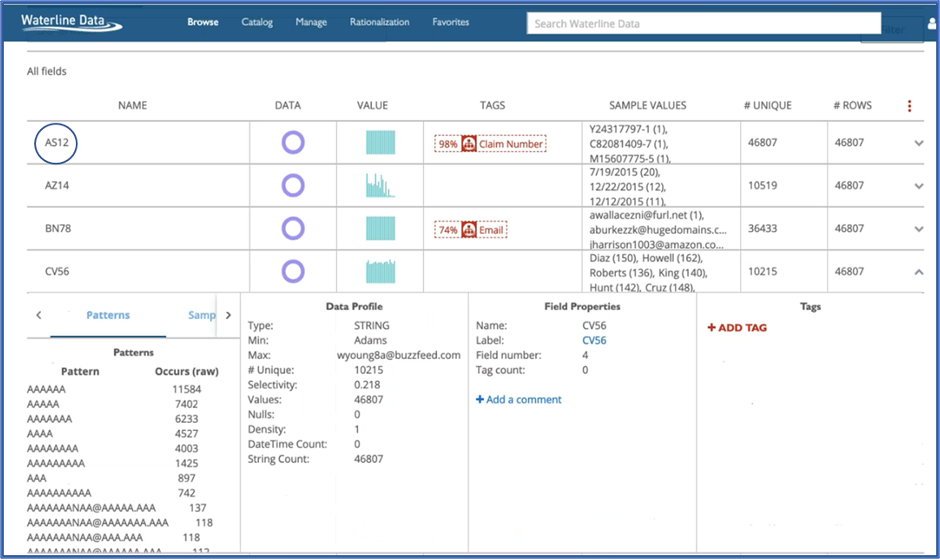
from Lumada Data Catalog
Click on the image to see a larger version.
Browsing the Catalog
Most data catalogs are easy to use for browsing and provide many insights with just a few clicks. How could you have Amazon without its interface? How do you decide what to buy if you had no browsing capability? You must be able to see descriptions, profiling statistics showing what is actually in the data itself, data quality, data lineage, etc. before you determine which data set fits your needs.
The criticism of needing to pick up the phone and call “1-800-GIMME THAT DATA” after browsing is whimsical, but if you look at Algmin’s “Option 2 -Expand the Data Catalog to Knowledge Engine” section of the article, this is exactly where some of the catalog products are going. Several products are providing a “one stop shop” where you have many or most data management capabilities in one interface, and most products provide an assortment of these capabilities. Instead of losing the interface, they are expanding it to encompass all the parts of the data lifecycle, just like he recommends. The last part of the data analyst pipeline may not always be provided, because most data scientists have their own tools they like to use and interfacing with them may be complex or custom by necessity. This is where APIs come in, as discussed earlier. Plugging into R Studio or Python may be straightforward, but other tools may not be so easy, especially if they are custom-built.
Keeping Current & “Stand Alone Affairs”
The criticism that catalogs are “stand alone affairs” seems strange to me. Mr. Algmin mentions that data catalogs cannot keep up with updates, however he does acknowledge that some tools crawl and get updates using automation and scheduling. This is an important feature that a “good” data catalog should have. One of the reasons you should have a data catalog in the first place is because of its ability to keep up with the volume and velocity of data, which is why a manual data inventory fails. The data catalog should update its statistics periodically and should have the means to automate it, especially those products that provide data profiling. The data profiling page for any data asset should show when it was last updated. In my opinion, this criticism is unwarranted.
In Sum: Baby & Bathwater
The cliché that comes to mind is, Mr. Algmin is “throwing the baby out with the bathwater.” Data catalogs are a huge step forward for the world of data management: they save users lots of time, and time equates to money and productivity. They combine many aspects of data management into one major capability, platform and interface. Are they all that they should be? No; are they an evolving technology? Of course. In the last chapter of my book, I envision where data catalogs can go in the future. I believe this technology is just getting started. Fasten your seatbelts! Let’s see where it is going to go! But in the meantime, if you want to do some serious sleuthing through your data, there’s nothing like the Data Catalog!
Note: This article provides screen shots from several different vendors, with no partiality to any specific product. The MITRE Corporation does not endorse any one vendor or product.
[1] The list of Data Quality Dimensions varies based on the author. There may be six, seven, ten, etc. The list includes dimensions such as accuracy, integrity, completeness, timeliness/currency, and others.
