 The concept of linking business processes with data is not a new concept. But, as with many core architectural components, it seems to be seeing a resurgence and is as important as ever in relation to many of the hot topics in data management today. In working with a number of clients in various industries with quite different data management projects underway, it occurred to me that a similarity across all of them was the importance of linking to business priorities and the business processes that support them. Following are some examples of how business process came into play in several different scenarios: Master Data Management, Data Governance, Data Quality, and Big Data Analytics.
The concept of linking business processes with data is not a new concept. But, as with many core architectural components, it seems to be seeing a resurgence and is as important as ever in relation to many of the hot topics in data management today. In working with a number of clients in various industries with quite different data management projects underway, it occurred to me that a similarity across all of them was the importance of linking to business priorities and the business processes that support them. Following are some examples of how business process came into play in several different scenarios: Master Data Management, Data Governance, Data Quality, and Big Data Analytics.
Master Data Management
Master Data Management (MDM) is the discipline that strives to achieve a ‘single version of the truth’ for core business elements – customer, product, supplier, etc. However, like the famous story of the blind men and the elephant, a ‘single version of the truth’ is made up of various perspectives on that truth. For those of you not familiar with the story of the blind men and the elephant, it is a classic tale of a group of blind men who each touch the elephant to discover what it is like. One man touches the trunk, another the tusk, another the tail, and another the hide and all, of course, have a different definition of what it means to be an elephant. All are correct in their own way, but the true ‘single version of the truth’ is a superset of all of their experiences. Master Data Management poses a similar scenario.
Take a common master data domain such as Product. While there is a comprehensive view of a ‘Product’ with a superset of attributes that supports multiple user groups across the organization, each user group has its own view of what ‘Product’ information entails and what the usage of that data is. Each group along the supply chain may view, create, edit, or delete certain pieces of the information that makes up the concept of ‘Product’. To make MDM successful, it is important to identify each of these stakeholder groups, and work with them to understand their usage and requirements around the data domain in question.
One helpful tool is a process model mapped to data elements. Figure 1 shows a subset of a sample business process for product development. Using a swimlane-style BMPN diagram, it shows the stakeholders along the left-hand column, with their key activities shown within their swimlane. In this small subset, we show a hypothetical product development lifecycle from product development, to product costing and pricing, to market testing.

Figure 1 – Mapping Business Process to Product Data
In this example, certain aspects of Product data are clearly ‘owned’ by a certain stakeholder group. For example, the product development team is responsible for defining the product components and assembly instructions. When it comes to product pricing, however, you’ll see that while supply chain accounting determines the initial price, this price may be modified by marketing during the market test phase. Marketing is responsible for product naming and the description that appears in the catalogue.
To keep track of the usage and lifecycle of data elements, a CRUD matrix is a helpful tool. The CRUD matrix keeps track of which groups Create, Read, Update, and Delete data. Figure 2 shows an example of a CRUD matrix that could be used in our scenario.
| Product Development | Supply Chain Accounting | Marketing | |
| Assembly Instructions | C | R | |
| Product Components | C | R | |
| Price | C | U | |
| Name | C | ||
| Etc. |
Figure 2 – Sample CRUD Matrix
Where information is modified by more than one group, it is particularly important to establish the proper workflow and governance. For example, in the case of Price, it could very likely occur that both supply chain and marketing both feel that they ‘own’ the information. By clearly mapping out the workflow and data lifecycle, it helps both stakeholders and MDM developers understand the correct data responsibilities for stakeholders and create the appropriate workflow, business rules, security rules, etc. around the solution. In many cases, redundancies and inefficiencies in the process can be identified and improved with the MDM solution, making MDM in effect a business process optimization tool. Often master data management is as much a business process initiative as a data management initiative.
Data Governance
Data governance is an area of data management that is particularly focused around people and process, and which can benefit from the use of a structured process model. As we saw in the previous example, identifying how data is used throughout the business process, and by whom, can help determine the proper data stewardship and ownership of data. Where there are conflicts over ownership, it can help resolve those differences. For example, in our pricing example above, both supply chain accounting and marketing contribute to the product price, but in different phases of the product lifecycle. Looking at the data through the business process lens can also help vet out the data model and design. For example, should there be an additional characteristic of ‘theoretical price’ that is created by supply chain accounting and ‘market price’ from marketing? Are there different pricing tiers by region, and/or effective dates for the market price? Seeing data in the context of real-world business processes can help clarify both its ownership and usage across the organization.
Data Quality
Similarly, data quality is an area where business process plays a key role. There are many ways to cleanse, validate, and enrich data, and many tools and methods in the market to support data quality in this way. But if data quality techniques are used in a vacuum, without taking business process usage into account, they are bound to be ineffective. A common analogy used is that of a lake that has been polluted by toxic chemicals. Biologists can work to clean the water in the lake, but if they don’t take into account the streams that are feeding that lake with pollutants, the water quality improvements will be short-lived. The polluted water from the streams will once again contaminate the previously-clean lake.
The same is true with data. If upstream business processes are not taken into account, data quality efforts are bound to be degraded by the same processes that originally caused the data quality issues. For example, a common data quality effort is focused on customer name, address, and contact information. In such a data quality initiative, it is important to understand the source of this customer information and how it was created and updated along the business process lifecycle. In Figure 3, the business process model shows that customer information is initially collected by marketing when they initiate a campaign.
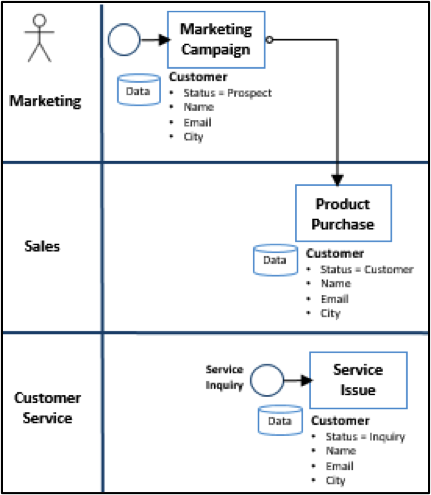
Figure 3 – Business Processes affecting Customer Data
When a given customer purchases a product, similar information is collected and/or updated by Sales. If an issue arises with the product and the customer contacts Customer Service, their information is once again collected. Are these three departments in synch and using the same source of customer information? Or are there siloed and disjointed data sources? There is nothing more annoying for the customer than to have to provide their same details again and again. If the three departments are using the same data source, is there clear governance and ownership around the data and how data is to be sourced and updated? Are staff members incentivized to enter data correctly? A salesperson may be incentivized to close the deal, but are they incentivized to ensure that the customer information is correct? There are both hard and soft incentives. A hard incentive would be actually tying data quality to a bonus or review criteria.  A soft incentive might be understanding how quality data affects their job. Similar to the labels on public drainages that state “No Dumping, this drains to the Ocean” that help citizens understand where pollutants in the drain ultimately land, explaining to staff how the data that they enter is used downstream helps understand the importance of keeping data clean. For example, if the sales rep realizes that customers won’t receive a renewal notice if the email address is wrong, and subsequently the rep won’t receive his or her commission for that renewal, there is a stronger incentive to make sure data is accurate. Both hard and soft incentives can be used together to promote data quality, and both should be tied to the business processes that affect key data.
A soft incentive might be understanding how quality data affects their job. Similar to the labels on public drainages that state “No Dumping, this drains to the Ocean” that help citizens understand where pollutants in the drain ultimately land, explaining to staff how the data that they enter is used downstream helps understand the importance of keeping data clean. For example, if the sales rep realizes that customers won’t receive a renewal notice if the email address is wrong, and subsequently the rep won’t receive his or her commission for that renewal, there is a stronger incentive to make sure data is accurate. Both hard and soft incentives can be used together to promote data quality, and both should be tied to the business processes that affect key data.
Big Data Analytics
Big data analytics can provide rich information for disparate sources that can augment current traditional data sources such as a data warehouse. In the case of customer data, for example, social media sentiment analysis, purchasing patterns, footfall analytics, and more can be derived to create a ‘360 view of customer.’ But this analysis is of little value if it is done in a vacuum. For example, if we have information on customer sentiment, it is important to understand where the customer is in their product lifecycle when this sentiment is expressed. Have they recently purchased the product, opened a service issue, returned the product, etc? Tying their sentiment to their stage in the purchasing lifecycle is critical to truly understanding their experience. Customer Journey maps are often created to help understand the customer lifecycle, and how data is affected at each stage of this journey. The value of big data analytics is enhanced when tied to business process.
Conclusion
Data is only valuable when placed in context, and business process provides important context around how data is used in an organization. Business process models help identify where information is used and by whom, which has clear impacts on master data management, data governance, data quality, big data analytics, and other data management initiatives. And, importantly, it helps establish business priority. It’s impossible to closely manage all information in an organization, and prioritizing business-critical data is an important step in any data management discipline. Business process helps create the context to establish priority. For example, does this data support the sales cycle that drives revenue? Is this data used by multiple processes across the organization? Does this information help make our supply chain more efficient? A ‘yes’ to questions such as these help determine the critical data that helps drive the success of business. In a business environment that is always driven by cost-benefit, using process models to more fully understand data’s usage helps both understand the benefits and help drive efficiencies that lower costs. I encourage you to consider using business process models in your next project – even if informal ones – and I hope you’ll see these benefits in your next data management initiative.
