 At some point, there will be full stack data-centric architectures available to buy, to use as a service or as an open source project. At the moment, as far as we know, there isn’t a full stack data-centric architecture available to direct implementation. What this means is that early adopters will have to roll their own.
At some point, there will be full stack data-centric architectures available to buy, to use as a service or as an open source project. At the moment, as far as we know, there isn’t a full stack data-centric architecture available to direct implementation. What this means is that early adopters will have to roll their own.
This is what the early adopters I’m covering in my next book have done and—I expect for the next year or two at least— what the current crop of early adopters will need to do.
I am writing a book that will describe in much greater detail the considerations that will go into each layer in the architecture.
This paper will outline what needs to be considered to give people an idea of the scope of such an undertaking. You might have some of these layers already covered.
Simplicity
There are many layers to this architecture, and at first glance it may appear complex. I think the layers are a pretty good separation of concern, and rather than adding to the complexity, I believe it may simplify it.
As you review the layers, do so through the prism of the two driving APIs. There will be more than just these two APIs and we will get into the additional ones, as appropriate, but this is not going to be the usual Swiss army knife of a whole lot of APIs, with each one doing just a little bit. The APIs are of course RESTful.
The core is composed of two APIs (with our working titles):
- ExecuteNamedQuery—This API assumes a SPARQL query has been stored in the triple store and given a name. In addition, the query is associated with a set of substitutable parameters. At run time, the name of the query is forwarded to the server with the parameter names and values. The back end fetches the query, rewrites it with the parameter values in place, executes that, and returns it to the client. Note that if the front end did not know the names of the available queries, it could issue another named query that returns all the available named queries (with their parameters). Also note that this also implies the existence of an API that will get the queries into the database, but we’ll cover that in the appropriate layer when we get to it.
- DeltaTriples—This API accepts two arrays of triples as its payload. One is the “adds” array, which lists the new triples that the server needs to create, and the other is “deletes,” which are the triples to be removed. This puts a burden on the client. The client will be constructing a UI from the triples it receives in a request, allowing a user to change data interactively, and then evaluate what changed. This part isn’t as hard as it sounds when you consider that order is unimportant with triples. There will be quite a lot going on with this API as we descend down the stack, but the essential idea is that this API is the single route through which all updates pass through, and will ultimately result in an ACID compliant transaction being updated to the triple store.
I’m going to proceed from the bottom (center) of the architecture up, with consideration for how these two key APIs will be influenced by each of the layers.
A graphic that ties this all together appears at the end of this article.
Data Layer
At the center of this architecture is the data. It would be embarrassing if something else were at the center of the data-centric architecture. The grapefruit wedges here are each meant to represent a different repository. There will be more than one repository in the architecture.
The darker yellow ones on the right are meant to represent repositories that are more highly curated. The lighter ones on the left represent those less curated (perhaps data sets retrieved from the web). The white wedge is a virtual repository. The architecture knows where the data is but resolves it at query time. Finally, the cross hatching represents provenance data. In most cases, the provenance data will be in each repository, so this is just a visual clue.
The two primary APIs bottom out here, and become queries and updates.
Federation Layer
One layer up is the ability to federate a query over multiple repositories. At this time, we do not believe it will be feasible or desirable to spread an update over more than one repository (this would require the semantic equivalent of a two-phased commit). In most implementations this will be a combination between native abilities of a triple store, reliance on support for the standards-based federation, and bespoke capability. The federation layer will be interpreting the ExecuteNamedQuery requests.
Shared Meaning Layer
For the architecture to be coherent, it needs a minimum set of semantic concepts that all layers and all parts of the architecture understand and implement consistently. We call this the shared model. It consists of concepts that the architecture must understand to executive its basic functionality. It includes such concepts as the concept of a stored query, or a constraint, or the classes that make up the basis for a model driven UI.
In addition, it consists of a small set of concepts to which behavior will be coded. Rather than require custom code to be written for every new concept introduced to the schema (which is the norm now), this architecture postulates a small number (a few dozen, at most) of domain concepts to which code will be written. For instance, nominating the classes to which geospatial reasoning will be applied, to those that temporal reasoning will be applied, to those that message-based communication will be applied, etc.
Data Security
Role and rule-based security will be applied at this level. Depending on the underlying capability, different approaches may be taken. One approach will be to re-write queries before they are executed in order to implement the intent of the authorization policy. Another possibility is chaining a series of filters together to get the same effect. Other possibilities include relying on capabilities in the storage layer.
The security rules will describe access, which will be interpreted on the ExecuteNamedQuery messages, as well as update access, which will only apply to the DeltaTriples interface.
Implementation of audit log functionality will also be at this layer, as well as the possibility of implementing metering as a way to enforce licensing restrictions or look for suspicious activity.
Identity Management
One of the primary duties of the identity management layer is to determine whether or not, at the time of creating a new instance, the referent has already been stored in the system. For instance, if we are storing a new customer, the system should first be able to know whether or not we have done business with this customer before. Additionally, we should be able to determine if we have done business with this individual in any capacity (as a vendor, employee, patient, or whatever). If we have, in fact, already encountered this individual, then we should return the existing URI (global identifier) to the client, rather than mint a new one. This part of the architecture is being implemented on DeltaTriples.
Most firms already have an algorithmic means to determine whether two things are the same (sometimes called a “match spec”). This is about making that capability a routine part of the architecture.
Additionally, there is functionality to handle the fact that duplicate identifiers have already been assigned and it is impractical to change either of the source systems. In this case the identity management layer maintains the list of synonyms and can mediate requests. That is, when a client requests “employee 123,” the architecture will return all information from the known synonyms of “123.” Pushed update messages will include all the synonyms so that subscribing systems can consume based on identifiers they know. This part of the architecture is being implemented on ExecuteNamedQuery requests.
Integrity Management
This layer, more than the ones below it, focuses on updates to the curated data stores. There is nothing to be done for identity management at query time, and the non-curated data sets are by definition not participating in integrity management.
The integrity management layer is primarily concerned with detecting which constraints need to be evaluated for a given update, executing those constraints, and rolling back updates that would violate them. This is entirely on the DeltaTriples interface.
Behavior
The behavior layer is where standardized-custom application behavior is implemented. This sounds a bit like an oxymoron, but bear with. There are bits of behavioral logic that are implemented in many systems, such as converting units of measure, calculating distances between points, queuing tasks for schedule, notification of exceptions, etc.
In most environments, this functionality is coded over and over again for each similar application that requires it. By basing all the application concepts on a limited number of primitive concepts, and then in turn coding the behavior to those primitives, we can implement this type of behavior logic only once, which can then be applied to a large number of applications.
Message Management
This layer is about communicating with existing systems on a messaging basis. Updates are disseminated to subscribing systems using canonical message models. Incoming messages are translated and treated as though they were originated within the architecture.
Domain Ontologies and Taxonomies
Much of the spread of shadow IT has been necessitated by the difficulty of adding a few new concepts or categories to an existing system. Faced with the need to do some analysis, most people in a corporate environment will extract the set of data they are interested in, and then load it into Excel or Access to apply the additional attributes or categories they care about in order to do their analysis.
Besides creating brittle systems integrations that must be maintained, this approach means that no one other that the extractor has access to the additional data added, nor to the analytical result.
This layer encourages the extension of the core model by using the capabilities lower in the stack. A domain specific extension can be created that has no adverse impact on anyone else. If it is communicated to others who find it worthwhile, they merely have to be given permission to access the repository and/or concepts added to be able to make use of them and any insights created.
Authentication and Repository Access
At a higher level, we must determine who the logged in user is and what repositories they have access to. This is a coarser grained security than the authorization-based one lower in the stack, but it’s effective and efficient for sorting out the first level concerns.
For instance, if we have public data harvested from the web in one of our repositories, we do not need to apply the same kind of fine-grained security as we do to some of our internal data sets.
Model Driven UI
Many parts of the application ecosystem can and should be model-driven. For instance, we can have model-driven user interfaces for many of the simple form-based interactions.
This layer will understand the model portion of the architecture (the difference between forms and fields) and how default values are expressed and implemented in a model driven environment.
There will also be a model-driven API layer. Public APIs will be defined in the model and exposed consistently through the architecture. Adding a new API to the model portion of the architecture will make it immediately available to consuming applications.
Bespoke UI
But the architecture will not limit all interaction to model-driven UIs. For a small number of the most important UIs, a developer will be able to write custom code to interact with the system.
This custom code will be executed against the exact same APIs, which will primarily be the ExecuteNameQuery API to get data and the DeltaTriples API to write data. All lower layers of the architecture (security, integrity, identity, and the like) will be executed identically for bespoke applications as for model-driven applications.
Model Builders UI
The Model Builders UI is essentially a specialization of the bespoke UI that has internal knowledge of the parts of the architectural model that persist the models. For instance, the Query Interface will understand where in the model named queries are persisted and how their parameters are stored. It will also understand how referential integrity between the query and the domain model is maintained. We expect that each query will be parsed on write; references in the query to parts of the domain model will be identified and written as annotations to the triple store, thereby allowing the system to know what queries would be affected by a change to the domain model. The model building UI operates primarily on the DeltaTriple interface, although it will also be using what it knows about the models to interpret the results it gets back from a query (e.g., a named Query).
In a similar way, there will be model builder UIs for:
- Constraint Writing
- UI Definition
- Match Spec (Identity Rules)
- Authorization (Rule Based Access)
- Taxonomy Management
- Constraint Definition
- Ontology Maintenance
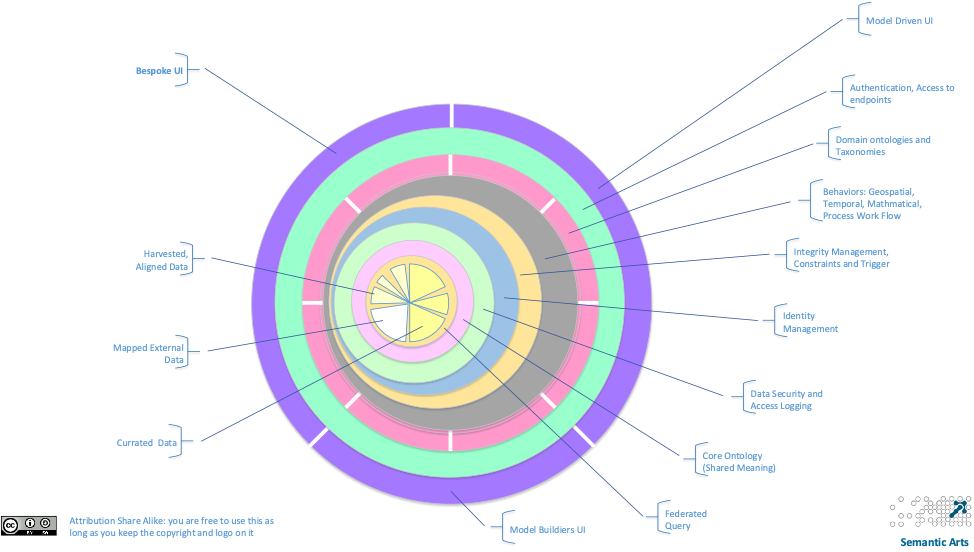
Figure 1: Sketch of the data-centric architecture
To Pursue this Further
For practitioners interested in pursuing these ideas further, we are conducting a very participatory conference in Colorado in early February: https://www.semanticarts.com/dcc/
Attendees will treat the figure above as a strawman version of an architecture and will discuss pros and cons of approaches to various layers within the architecture.
Vendors of products that could help with any part of the architecture are encouraged to attend and demonstrate their capability.
