
Many developers pooh-pooh OWL (the dyslexic acronym for the Web Ontology Language). Many decry it as “too hard,” which seems bizarre, given that most developers I know pride themselves on their cleverness (and, as anyone who takes the time to learn OWL knows, it isn’t very hard at all). It does require you to think slightly differently about the problem domain and your design. And I think that’s what developers don’t like. If they continue to think in the way they’ve always thought, and try to express themselves in OWL, yes, they will and do get frustrated.
That frustration might manifest itself in a breakthrough, but more often, it manifests itself in a retreat. A retreat perhaps to SHACL, but more often the retreat is more complete than that, to not doing data modeling at all. By the way, this isn’t a “OWL versus SHACL” discussion, we use SHACL almost every day. This is an “OWL plus SHACL” conversation.
The point I want to make in this article is that it might be more productive to think of OWL not as a programming language, not even as a modeling language, but as a discipline. A discipline akin to normalization.
Normalization
Normalization is a set of methods that lead to better relational database designs. However, it is more often practiced in the breach. How often have you heard someone say, “Here, just take this denormalized (flattened) version of the data from this database.”
Normalization, as introduced by Ted Codd, the creator of the relational calculus, is a step-by-step method for improving naïve data designs, and turning them into table structures that are robust to insert, update, and delete anomalies. There is no “normalization language” or syntax. Normalization is a process you go through to get from an initial data model to a refined one.
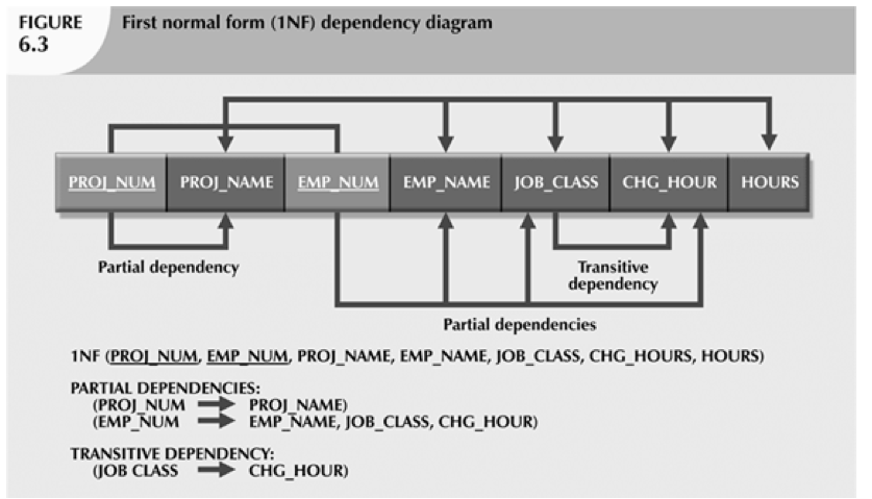
Most database designers take the process through the first three steps, called first normal, second normal and third normal form. First normal is about getting rid of repeating values in a column. Second normal is about rationalizing attributes that only depend on part of a composite key off to another table, and third normal is about getting rid of data that depends on something other than the primary key of the table. Some practitioners call this “the key, the whole key and nothing but the key.”
Most people think fourth through sixth normal form are “too academic.” Sixth normal form curiously requires that every table have just two columns, one for the primary key and one for the single attribute. In most literature, this is dismissed as requiring too many tables. But that is exactly what a triple store is. The subject is the primary key, the predicate is the column, and the object is the value. Triple stores got around the problem of too many tables by not having any.
Normalization then is a discipline, not a language. Semantics too is a discipline. It is not a discipline that takes over where normalization ends, though, it is the discipline that takes over before normalization begins.
Every normalization exercise I’ve ever seen assumes the initial data is “right” in some primitive way. The starting assumption is that the raw data is correct, at the right level of abstraction, has good identifiers, and all that it needs is to be better organized.
Semantics
This is where we believe semantics comes in. Most data that we have looked at is more like “a finger pointing at the moon” than it is the real moon. Implementors, people who capture data, are usually taking a superficial view that satisfies their immediate itch. But this is why systems integration is so hard. Trying to reconcile a bunch of superficial simplifications rarely gets at the deeper things being represented.
Semantics attempts to peer behind the surface presentation and glimpse reality. Our interest in semantics started in the early 1990’s. Having observed the cacophony that results when individual systems are independently designed with no common reference point, we yearned for something to bring it together. At one early client, we discovered that they had implemented what was essentially the accounts-receivable functionality 23 times in 23 different systems. They didn’t see it when they implemented the systems because each system had completely different terms. When they overpaid a claimant and had to get money back, they called it claims overpayment. When they billed for an elevator, it was an elevator permit. When a provider needed a license, it was a license bill. The frustrating thing was that when this was all uncovered and they began writing the “global AR” service, they began reimplementing all 23 transaction types as if they were different.
In the early 90’s, we still did research at the library. We rounded up everything we could find on semantics in enterprise information systems (four articles). By the end of the nineties, there was more activity (and it could now be found on the World Wide Web). We quickly went from Shoe, to DAML, to OIL, and finally to OWL.
Affordances
An affordance is an intrinsic property of an artifact that strongly suggests its preferred use. The affordance “handle” on a door is what makes people pull on it even when the sign says “push.” The affordance is more compelling than the words.
Software and modeling languages have affordances. There is something about how they are expressed that encourage some types of behavior and discourage others.
What OWL encourages is the formal definition of meaning.
OWL
Just because a language has affordances, doesn’t mean people will use them.
And so, it is with OWL. Our observation is that most OWL-based ontologies push where they should be pulling. Taxonomists create deep class trees, with little more than their labels distinguishing them. Object-oriented programmers create classes that are subclasses of restrictions (it’s their way of saying, “I know members of this class should have this property,” but it isn’t a way of saying what that class means). JSON developers have a strange fascination with blank nodes. Relational database designers seem to like renaming any common property every time it is used to link two different pairs of classes. And for reasons none of us understand, biologists seem to create ontologies where all the classes are really instances and so couldn’t possibly have instances.
What is the affordance that OWL is trying to tell us?
That many classes can have a machine-readable and unambiguous definition. The main ones that don’t are the foundational building block classes. But once you have the building blocks in place, creating new domain-specific classes is just a matter of applying the “distinctionary” pattern.
We might say that a patient is a person that has had some medical procedure performed at some authorized medical facility.
:Patient == :Person and :had some :MedicalProcedure and :receivedCareAt some :AuthorizedMedicalFacility .
Assuming you know what a person, medical procedure, etc., are, you have an unambiguous definition. You will not consider someone treated on the road by a good Samaritan as a patient, nor will you consider someone who has medical insurance to be a patient until they show up for care. Note: if this is not the definition you want to share, then change the formal definition. For instance, if you are a veterinary clinic you will probably substitute :Animal for :Person in the above.
What we have found is that using a well-curated set of building blocks (gist is an excellent and free place to start) coupled with applying the distinctionary patten results in models (ontologies) that are unambiguous, easy to explain and surprisingly elegant.
An elegant enterprise ontology built this way is a cornerstone to the Data-Centric organization.
