
I recently gave a presentation called “Knowledge Management and Knowledge Graphs” at a KMWorld conference, and a new picture of the relationship between knowledge management and knowledge graphs gradually came into focus. I recognized that the knowledge graph community has gotten quite good at organizing and harmonizing data and information, but there is little knowledge in our knowledge graphs. At the same time, I noticed that the knowledge management community is skilled at extracting and curating knowledge but doesn’t know where to put it.
These two communities are like two ships passing in the night. They may notice each other, but that’s about it. What we want to do (starting with this column) is to begin to integrate these two communities.
What Is Knowledge Management?
There are many definitions of knowledge management, but they all seem to be overly generic and therefore less than useful. As a practitioner of the art of semantics, my goal is to distinguish knowledge from data or information. Which begs the question of what knowledge is. I reject the standard DIKW (Data, Information, Knowledge, Wisdom) pyramid because it implies that knowledge is somehow filtered up or down from data and information. That is just too woolly to be of any use.
More important is the distinction between tacit (or implicit) knowledge that is gained through experience and explicit knowledge that can be articulated, stored and shared — like the kind of knowledge that can be stored in a content management system. The best we can do for tacit/implicit knowledge is to build some form of expertise locator system.

Where Is the Knowledge in a Knowledge Graph?
I will posit that low-level assertions of fact are different from “knowledge” with a capital “K.” It seems to me that if every fact and every bit of content were “knowledge,” there would be no difference between data processing, content management, and knowledge management. But there is a difference. Knowledge management deals with a special subset of data, information, and content.
Now, back to knowledge graphs and what makes me say there isn’t much “knowledge” there. To understand my orientation, let’s look at history. Once upon a time there were graph databases and later a standard called Resource Description Framework (RDF). Neither fully caught on until Soren Auer from the University of Hannover scrapped the information panels from Wikipedia and put them in an RDF triple store which gave birth to the Linked Open Data movement. Notice this was Linked Open “Data” and not Linked Open “Knowledge.” What you can scrape from the info panels of Wikipedia is not deep knowledge. It’s how many home runs Barry Bonds hit and what the population of Bratislava is. I would contend that these facts and assertions (while useful) are short of knowledge.
The term “knowledge graph” didn’t come into widespread use until Google acquired a Linked Open Data RDF vendor and rebranded it as the “Google Knowledge Graph.” But just calling it a knowledge graph didn’t mean there was much knowledge in it.
What Is Knowledge?
One of the challenges with “knowledge” is the lack of a good definition for the concept. From my perspective the best definitions are those that allow a large population of users to identify the same items in the same way as we do with full formal definitions in OWL.
Anyone who agrees on the predicates and the primitive classes will agree on the classification of items to the class membership. We can’t always achieve a full formal definition of a class, so the next best we can do is very clear and unambiguous annotation definitions. To get there, it often helps to start with examples that everyone can agree on and work backward from them to figure out what makes it different. Let me illustrate this challenge with an example that will represent the differences between data, information and knowledge.
I have radiant heat in my house and woke up one morning to it being cold. I checked the boiler which had a display presenting “E110.” Most people would agree that E110 is “data” without meaning for most people. The owner’s manual indicated it was an error code and noted that the likely cause was a problem with the input filter or the output filter. Most people would also agree that knowing that E110 is an error code is “information.”
I have no idea what the input or output filter of a boiler looks like or where to find it — so I called a plumber. The plumber knows where the input filter is located and also knows that “this is hardly anything.” This is not the problem. He tries rebooting the system and leaves. The next morning the floor is cold, and we have the E110 code again. The plumber returns and we call tech support. The technician and the plumber agree that the likely cause is the condensate trap and that a system flush was in order.
From the knowledge perspective, the E110 error code is clearly data. Knowing that it is an error code, and its likely cause are information. Everything else (i.e., the location of the input filter, how to remove it, how to infer the exhaust filter was functioning, and the role of the condensate trap) was all knowledge. Some of which might be written into a content management system. After this, my initial definition of knowledge was the “distillation of experience.”
I’ve modified my definition based on another scenario. For instance, there might be a tax code that is hundreds of pages — which could also be part of a legal contract. You want to know the few key facts that apply to you. For example, you might want to know the tax consequence of early IRA withdrawal. Out of the hundreds of pages of regulation and interpretation through court cases there might be a few sentences that summarize our situation. This is the distillation of content for a specific purpose. Just because we can reduce a 100-page document to two sentences doesn’t mean the other 99 pages are unnecessary. It’s just that they aren’t germane to the issue at hand. So, my revised more complete definition is…
“Knowledge is the distillation of experience, or the distillation of lengthy prose, to its essence for a given purpose.”
This is the way I think most knowledge managers tacitly understand the definition. I have just taken a stab at making it explicit. Distilled the essence is the first part, they still need to put the content somewhere so that consumers can find it when needed. This is usually a knowledge management system — which is really just a content management system that only contains good stuff. Most knowledge management projects focus on extracting these nuggets and putting them where they can be found by an enterprise search.
Put the Knowledge into a Knowledge Graph
The obvious answer to where we should put knowledge is into a “knowledge graph.” This will have the benefits of tying it to its source (so it can be challenged) and bringing it to bear more automatically at its time of need.
Some knowledge is knowledge about things that are already in the knowledge graph. For example, if we learn that Judge Jones is more lenient on parole offenders before lunch (and notice how this fits the definition about, this is the distillation of experience, or observation of maybe hundreds of Judge Jones’ verdicts). It isn’t hard to imagine that we should attach this knowledge to Judge Jones. Judge Jones is an instance, probably of the class “Judge” and certainly of the class “Person.” We don’t need any new classes, but we might need some more predicates.
In the tacit/implicit side of knowledge management, we need a taxonomy rich enough to distinguish individuals who are likely to have some implicit knowledge from those who don’t. Taxonomic categories are generally good enough for this purpose. Often, we find a need to distinguish between whether people are able (“can”) versus whether they are permitted (“may”) do a particular thing. For instance, if you want someone to extract the vacation accruals from a DB2 database you need someone with the skills, someone who “can” use the tools (maybe SQL) to do the extraction and someone who has permissions, or entitlements to where they “may” extract the data.
For the rest of the explicit knowledge, eventually we recognize that we will need to invent some new instances of some new classes in order to capture some knowledge. There are instances that are “made up.” Many were made up long ago and are generally agreed to, but that doesn’t mean they weren’t made up.
Once upon a time we “made up” that there were four elements (earth, wind, fire and air). We accreted a great deal of knowledge onto these made-up concepts. Later the alchemists refined this, adding things like “phlogiston” which was the element in wood that made it combustible.
Today we have 118 elements. We think they are real, but they are the product of many detailed observations. We have learned a lot about each of these elements, not only their atomic weights, typical isotopes, melting and boiling points, and how they combine with other elements, but much, much more. Add to that what we’ve learned about all chemical molecules, proteins, and genes.
It is tempting, and we can see how tempting it is by observing that most of the ontologies in the OBO foundry have fallen into this trap, to create a class, a subclass of Physical Substance (or independent continuant/material entity for the BFO crowd), but this really doesn’t work on a number of levels.
The first is that it promotes hundreds of thousands or even millions of classes and even this isn’t enough for the variety that exists. The second is that it doesn’t provide a good place to attach knowledge when we acquire it.
It turns out what we need is a place to put these “made up” concepts to which we attach knowledge. They are a bit like skos:Concept, though skos:Concept is broader and more general, indeed almost anything ends up being a skos:Concept in a skos-based ontology/taxonomy. We’re looking for the class of things that we need to handle what we learn, if it isn’t an already existing instance in the rest of the ontology and isn’t a taxonomic category.
Up until now, we have sort of punted and just made up an orphan class for these concepts when we stumble upon them. In our parlance, an “orphan” class is one that we make up that isn’t a proper descendent of an existing gist class. In the next version of gist, (gist14), we introduce “KnowledgeConcept” as the covering concept for these types of instances that are necessary to carry knowledge. Our observation is that each domain has a handful of these, which would each be proper subclasses of gist:Knowledge Concept.
Here are a few examples from different domains:
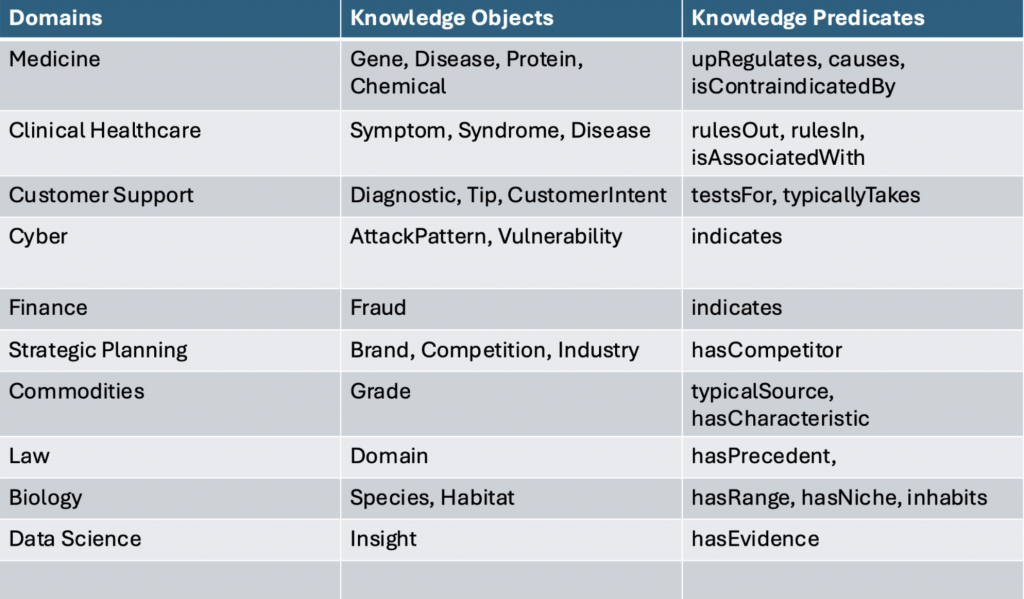
What we find is most domains have a few concepts for capturing knowledge. Each domain will have a handful of these classes, and often hundreds or thousands of instances of these classes. There are two powerful use cases for integrating knowledge with the rest of the data and information in the purview of the enterprise: “provenance” and “knowledge in context.”
Provenance
Provenance is the ability to track something from its source. In the world of art, it is used to make sure that a work of art is authentic. If knowledge is the distillation of experience, we may want to consider what experience went into the knowledge.
One problem with knowledge that is divorced from its source is the difficulty in telling which knowledge is truly grounded and distinguishing it from that which is just contrived. This is why fake news is so prevalent. News is a form of knowledge that is easy to fake.
Knowledge graphs have long had a provenance mechanism. One method for ensuring provenance is to use the “named graph” (the fourth value in a triple) to hold information about where this triple came from. The named graph (not to be confused with the name space) is a small bit of information that can be attached to any triple. It is part of the RDF spec, and therefore is not a vendor extension, it works in all triple stores.
Some people put literal values in the named graph, either to speed querying (you can get all the triples for a patient if you put the patient ID in every triple about that patient) or for security (in some cases it may be possible to assign a security profile to every triple and use that to provide fine grained authorization).
We think the most powerful thing to do with the named graph is to provide provenance information by making the named graph an IRI on its own right. Note that if a bunch of triples share the exact same source (i.e., come from the same transaction or the same batch upload), they will share this provenance information.
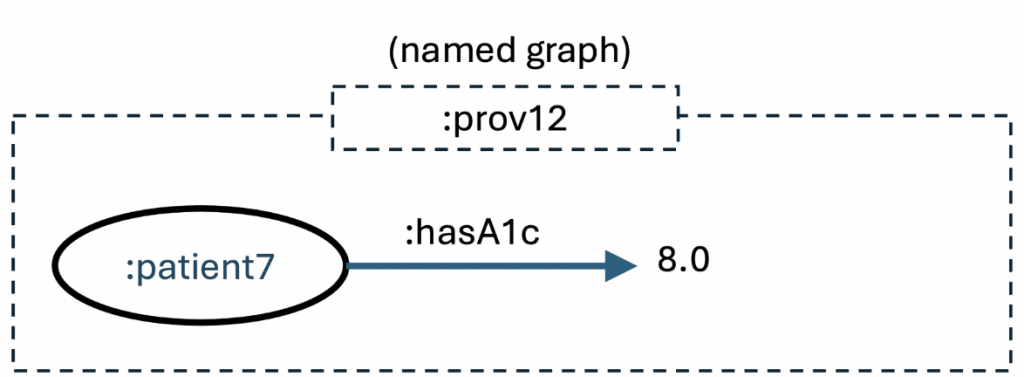
In this example, we show the provenance of a low level fact, that this patient has an A1c value of 8.0.
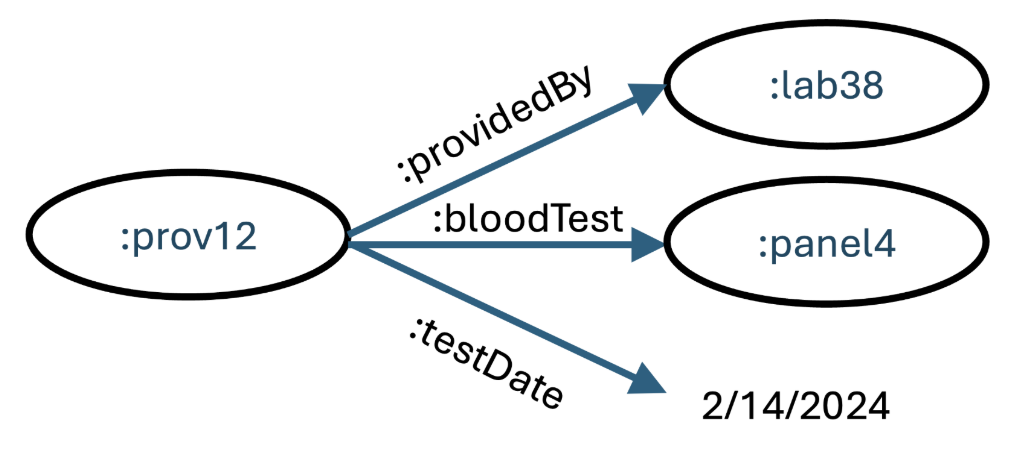
These triples represent that this factoid was provided by a particular lab on a particular day using a specific test panel. We might have also added the equipment, the procedure, that blood sample, and the phlebotomist. This forms a good audit trail as to the validity of this information. If we agree to our suggestion earlier, that knowledge is the distillation of experience, and that knowledge can be expressed in a knowledge graph, we might have something like:
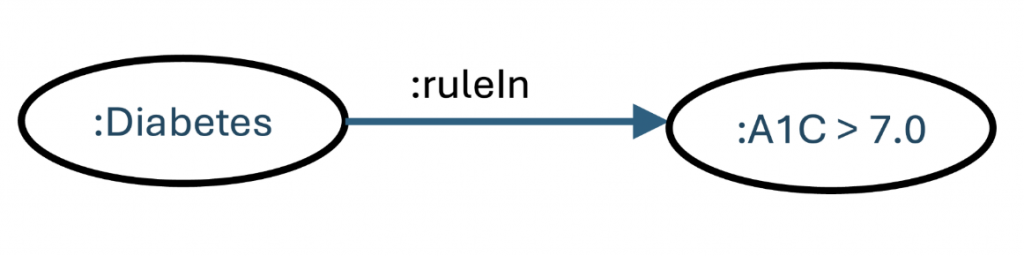
If one of our chunks of knowledge, based on the observation of thousands of people who struggle to control their blood sugar levels, is that anyone with an A1c value >7 has what we call “diabetes” (an instance of the class :Disease), then for those in the health field, this is a reasonable (if conservative) definition of the general condition called “diabetes,” a knowledge concept in our new conceptualization. But where did this come from? This did not come from a lab; this came from experience. Here, we connect this bit of knowledge with its source.
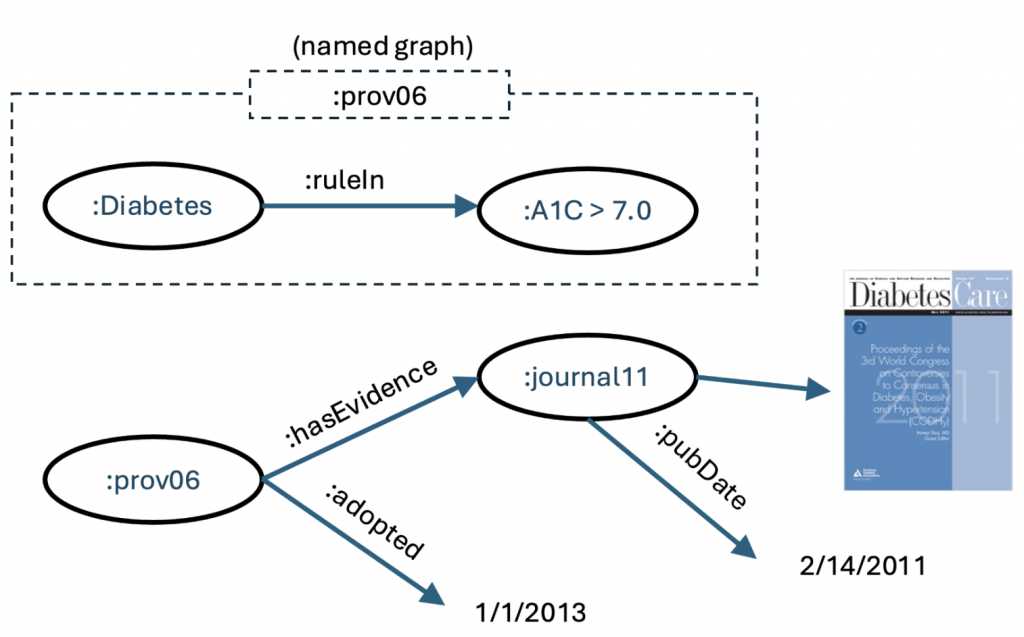
We use the named graph to get to a node that tells us where this information came from. For something as general as this example, it may be from dozens or hundreds of sources or from a meta source like Cochrane. For something specific and new, it might be a single clinical trial giving us the evidence.
In any case, we want the system, wherever possible, to refer to the source of knowledge so that consumers could consider its relevance and determine whether they think it applies in their circumstance or whether they should challenge it with other information.
Knowledge in Context at the Point of Use
The other reason we want to use a knowledge graph is to automatically bring knowledge forward at the time of need.
The current state of the art in knowledge management is “Enterprise Search.” Firms are trying to make it easy for knowledge consumers to find what they need. This is now being eclipsed by ChatGPT and our AI portal will be attempting to help with the enterprise search for the nugget of knowledge that would be most helpful at the point of need. Both of these uses are hopelessly short of what is needed. Both require a human in the loop as well as the ability to ask the right questions.
Let’s postulate that the enterprise is data-centric and that most of their data and information is being captured in real time directly into the knowledge graph. It is just a matter of getting this data to connect to the knowledge that is most important for the current situation. In some cases, this might be fully automated. In some cases, this will lead to efficient self-service, and in some cases, it helps the knowledge consumer automatically get the right information at just the right moment.
Let’s use an example from customer service. Our observation, from a project we did, showed that 20% of all calls to PayPal customer service were to find out the status of a refund. This is because the process of making a refund is actually quite complex. Here’s a simplified example to give you an idea how knowledge can be slipstreamed into a routine business process.
There are many payment options for consumers with PayPal. They might have allocated money directly from their PayPal account. They might use their bank account attached to the PayPal account. They might have paid via a debit or credit card attached to their account. Or they might have used a mix of these methods to fund their purchase. The vendor of the product the consumer bought has no idea of the payment mechanism, they just received $x from PayPal on behalf of the consumer.
But the payment mechanism is important. If a consumer is dissatisfied with the product or service (i.e., it didn’t arrive, was late, was broken or didn’t work as advertised), there can be a lenghty dialogue between the consumer and vendor that can drag on over weeks or months. Sometimes, PayPal is asked to step in and referee the disputes because a great deal of the information on the PayPal’s web site and internal repositories are about how to adjudicate such disputes.
When the consumer and vendor mutually agree to a refund, the vendor will inform the consumer that the refund has been issued. The consumer frequently goes directly to their PayPal account, doesn’t see the refund, and immediately calls customer support. Historically, customer support may have relied on enterprise search and logged into several systems to give them visibility into the context of the transaction. They usually figure it out, but often after 5-10 minutes.
Imagine something like this. The consumer dials into PayPal. The system recognizes their caller ID (or asks them some confirming questions) and determines that they have account 44, and that one of the recent transactions to that account is tran22. The system knows that this is a refund transaction.
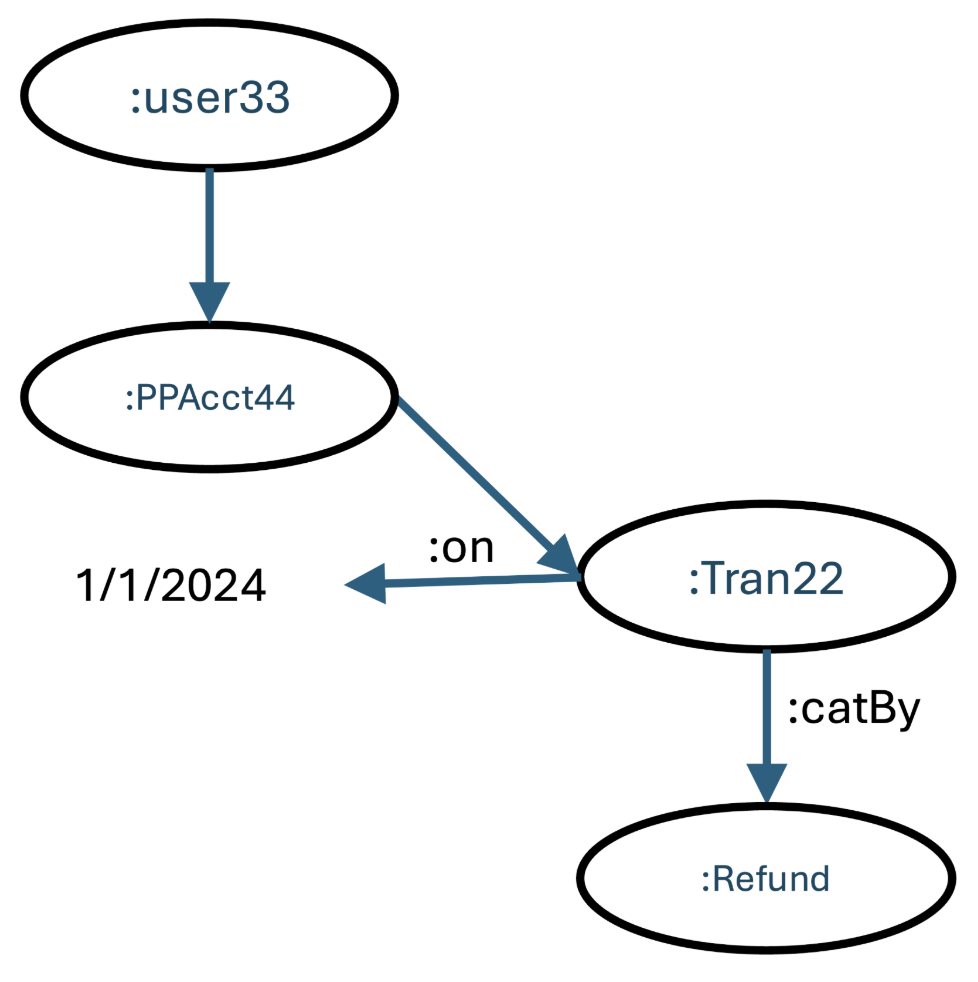
This is a good start. But the system, with integrated knowledge management, also knows something about refunds.
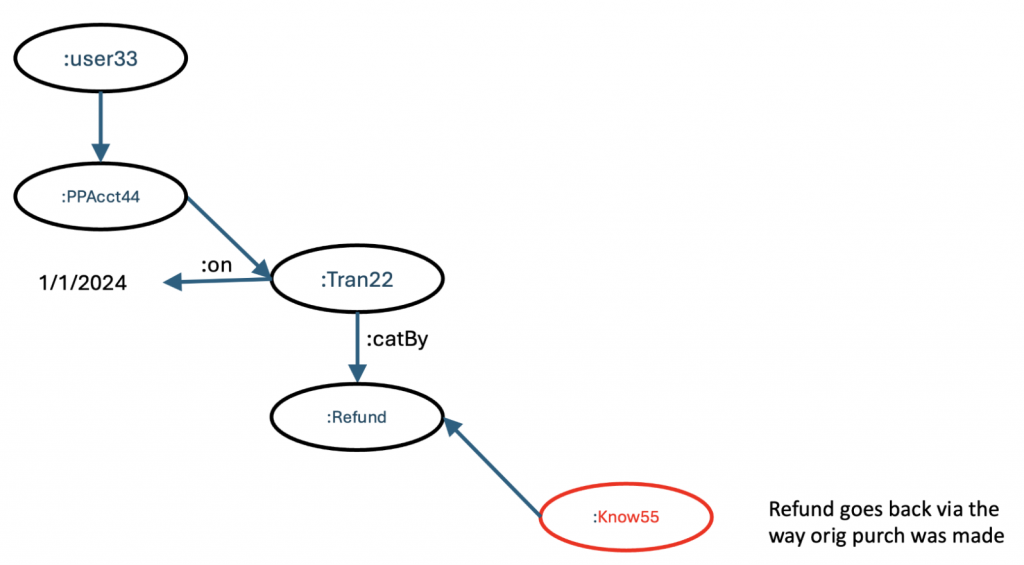
Refunds are implemented based on how the original purchase was made. The vendor never knew how the original transaction was financed. The consumer has likely forgotten. This information may be in another system. But an integrated knowledge graph would know. In this case, we find that the original purchase that was being refunded was made with a credit card attached to the PayPal account.
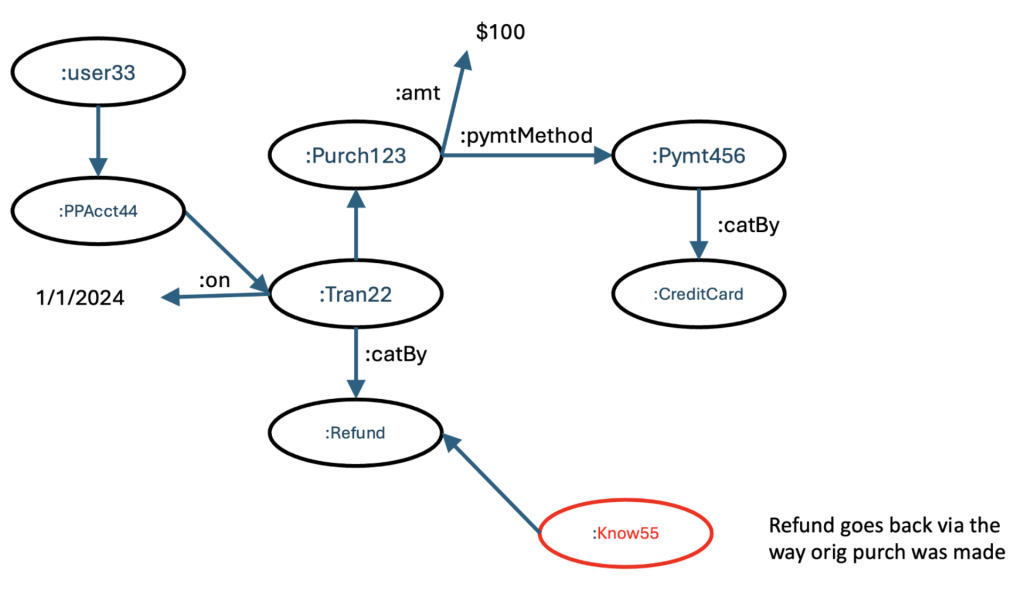
Which allows us to bring in another nugget of knowledge:
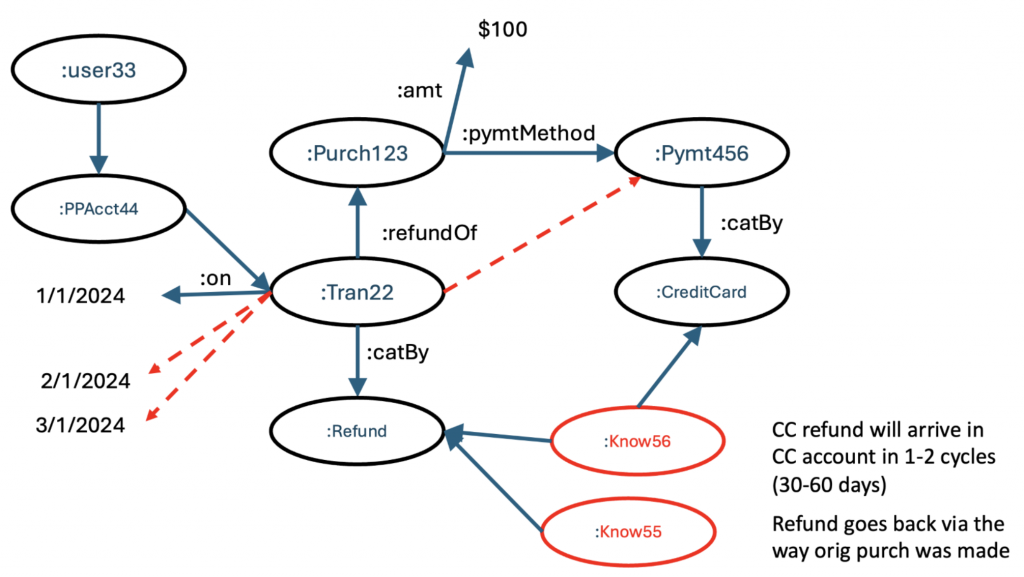
If the original purchase was on a credit card, the refund will go back to that credit card and will show as a debit memo on that card in one to two cycles. This integration of knowledge with data and information could play out fully automated (the system could send a preemptive message to the consumer to let them know what was going to happen, or it could react automatically when they call). It could also be a self-service system allowing the consumer to navigate this bit of information or become an additional insight for the customer support team.
Conclusion
The time is right for the knowledge management community and the knowledge graph community to join forces.

The two ships that were passing in the night should dock, and exchange approaches and techniques. What are we waiting for?
