
Recently, I was giving a presentation and someone asked me which segment of “the DAMA wheel” did I think semantics most affected.
I said I thought it affected all of them pretty profoundly, but perhaps the Metadata wedge the most.
I thought I’d spend a bit of time to reflect on the question and answer it properly here.
(I’m also going to broaden the original context from “semantics” to Knowledge Graphs and Data-Centric while I’m at it, partially to provide a reason for including it in this blog).
————-
The DAMA / DMBOK Wheel
To refresh your memory, here is the “wheel”.
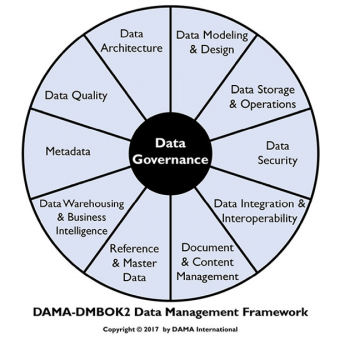
https://www.oreilly.com/library/view/dama-dmbok-data-management/9781634622479/Chapters-5.xhtml
It’s a bit sad, but the Data Management Book of Knowledge, with 588 large dense pages, devotes one paragraph to Graph Databases and makes three passing references to ontologies.
With that backdrop, let’s dig in, one wedge at a time.
Data Modeling & Design
My first reaction to the original question that sparked this writing exercise was that it would be meta-data that would be most impacted by the Knowledge Graph / Semantic / Data-Centric approaches. But then I re-read the section on Data Modeling. Just as I was writing this (in a café) a young man came up and introduced himself, because he saw I was reading the DMBOK. He exclaimed, “I’m taking the test this morning!” I didn’t have the heart to tell him what I was doing.
This chapter on data modeling is well intentioned and does represent the consensus opinion on best practices. It also represents why we are in the dire straits we are. The focus of course is on structure, and structured data, which therefore directly leads to discussions on cardinality and crow’s feet, as well as normalization. What focusing on these tactical items does is take our eye off the strategic ball, which is the question of “what does all this information mean and how is it related to each other?”
As some of you know I’m working on a follow-on book, “The Data-Centric Pattern Language,” which is dedicated to helping designers and modelers think differently about information and knowledge modeling.
Data Storage & Operations
The Data Storage & Operation chapter deals with such concepts such as setting up production Database Administration, how to virtualize data, the idea of ACID (Atomic, Consistent, Isolated and Durable) updates, CAPs theorem (that you can have two of: Consistency, Availability, and Partition Tolerance) They even mention triple stores as an option.
Surprisingly, this chapter is pretty much unaffected in the migration to Knowledge Graphs, Semantics, and Data-Centricity. Pretty much everything in this chapter still stands as is.
Data Security
This is an excellent outline of the issues and requirements in Data Security Management. They even mentioned “Data-centric Security” (which didn’t make the index and I would have missed it had I not re-read the book). They correctly point out that having an Enterprise Data Model is essential in identifying and locating sensitive data. They mention that relational databases can use views and other techniques to isolate parts of the model from certain groups.
But until you begin to put a lot of a firm’s data into a shared graph, some of which is subject to legislative control and others of which is sensitive for competitive or other reasons, you won’t see how freeing data from silos and applications create new security issues.
While there is nothing wrong with the data security chapter, I don’t think it adequately predicts what is about to happen to firms that unify their data. We believe a central part of a data-centric architecture will be a rule + role based authorization mechanism that can be managed at the business and security analyst level.
Data Integration & Interoperability
The Data Integration chapter is focused on ETL (Extract Transform and Load) which is the predominant technique for populating data warehouses. They also spend a bit of time on Service Oriented Architecture and Enterprise Service Buses and note that the existence of a canonical message model is a great boon to integration through messages and a bus.
What they seem to have missed is the use of URIs (Uniform Resource Identifiers) and their superset IRIs (International Resource Identifiers, which are URIs in Unicode), which give you integration almost for free. In a traditional system, identifiers are very local; you have to know what database, table, and column they are in to know what they are. You have to “join” them to other tables to get local integration, and you have to move them to other databases to get enterprise integration.
It really changes the integration game when you realize you can just point, federate, and integrate. If you are federating relational or big data platforms, there is the additional step of mapping, but once done, integration is point, federate, and integrate.
Document and Content Management
The document and content management wedge is mostly concerned with content, documents and records as seen by the legal department. That is how this information is seen in the light of e-discovery and records retention.
This is the section where they spend the most time on ontologies, semantics and even RDF, but more how these approaches might be used to tag documents, not so much how they might be the basis for native systems.
But the giant miss, is the lack of discussion about NLP (Natural Language Processing). The integration of structured and unstructured data has long been the holy grail of data management, and like the grail most have concluded it unattainable.
NLP and Semantics have long been on a collision course which has finally converged. For a long time, NLP has been good at “Named Entity Recognition” that is, the ability to isolate people, organizations, places, events and the like from text. Two things have changed lately that move NLP from merely lifting named entities to allowing true integration.
The first is assigning the named entities globally unique identifiers, based on URIs. This involved lifting the named entity from the document as well as some other contextual data sufficient to bump these attributes against an entity resolution service and determine if we have information on this entity (in which case use the existing URI) or if we don’t (in which case mint a new URI).
The other development has been the ability to determine, from clues in the text, the relationship between the named entities. It is now possible not only to extract these relationships, but to align them to the properties in the ontology.
This is a huge development and isn’t even hinted at in this section.
Reference and Master Data
This section has a pretty good definition of what Master Data and Reference Data are, which is valuable, as there seems to be a great deal of confusion in practice on these items. Master data is distinguished from transactional data, in that the former are the more permanent entities the firm deals with (the vendors, customers, employees and products for instance) and what the firms does with them as the transactional data (the purchase orders, sales, paychecks and issues). Like Master Data, Reference Data is more static and permanent. But reference data isn’t really about an entity, it is about things like currency and locations, as well as about the way we categorize things.
The section correctly lumps taxonomies into the Reference Data category. In my opinion they incorrectly lump ontologies into the Reference Data category as well.
They note that some Reference Data in internally created, but there is a great deal that is created and maintained by industry standards groups (ICD 9 & 10 in healthcare for instance and ISO 3166 for country codes). While adopting industry standard identifiers is a good practice, they failed to note that an even better practice which would ease data integration drastically would be the adoption of globally unique identifiers (URIs) for these items.
They point out that a key to Master Data Management has to do with the matching algorithms, the routines that determine whether two entities are in fact the same. They point out that these routines could be deterministic or probabilistic. They missed the fact that a Knowledge Graph (especially a Labeled Property Graph where we can have weights on the edges) could be probabilistic and maintain those probabilities such that different users could have different thresholds of certainty on identity matching.
Finally, they missed the key shortfall for most Master Data Management systems, which is being based on relational data structures makes them inherently brittle, and as such makes it harder to incorporate the conflicting needs of multiple divisions that try to share Master Data.
The inherent flexibility of the Knowledge Graph approach resolves the tension between sharing and having it your own way.
Data Warehousing and Business Intelligence
This is very focused on the dimensional approach to Data Warehousing. Given the general prominence of Data Warehousing, it was a surprisingly short chapter.
It pretty much missed the rise of Data Lakes and Big Data as Data Warehousing approaches (although to be fair there is a chapter on Big Data that didn’t manage to get a wedge in the wheel).
What we are seeing in large firms is a lack of resolve in getting their dimensions to conform, and as a result there is an incredible sprawl in the data warehouses. One of our clients mentioned that their analysis had detected that their data warehouse had patient data in 4,000 tables. When you have dismantled your patient data over 4,000 tables, you will never put it back together.
The big changes that will come with graph databases will be the ability to understand and locate the data contained in your data warehouse and your data lake, as well as the ability to perform network analytics, which isn’t really possible on structured data.
Meta-data
Meta-data management is affected massively on two or three different vectors. First, the meta-data management platforms. Have you ever tried to manage metadata on a relational database? It’s hard. Meta-data is complex and multifaceted. Figuring out where something is used with massive multi table joins. Traversing the graph is much, much simpler.
How about the relationship of data to meta-data? In a traditional system at one level the two are hard coupled. The data in a cell is dependent on the metadata in the column, which is really in the catalog. Any other meta-data not co-resident (for instance in a meta-data management system) is so remote that it requires being aware of the other system, a context switch, permissions, and knowledge of how the other system works to find out anything more about the meta-data for a given data element. Compare that to a Knowledge Graph— the data is one triple (and therefore one click) away from its meta-data. And everything else we know about the meta-data is similarly just a triple (and a click) away including synonyms, other implementation in other systems, business definitions, etc.
But perhaps the most profound change for meta-data management is one of scale, which ends up making it, you know, manageable. A typical large firm has millions of concepts (meta-data entities or attributes) under management. A data-centric firm has hundreds of concepts and properties (meta-data). For a long interim these will have to be mapped to their legacy equivalents, but over time this should be shrinking rather than growing.
Data Quality Management
Most of the data quality information is as valid in a semantic environment as it is in a traditional environment. The only thing that I think a semantic approach would add would be the ability to combine high quality and low quality data in a meaningful way.
In a traditional environment you either have high quality data or low quality data (really you have data that is in between, and you try to assess it and improve it wherever you can).
In a semantic environment you can share meaning, even when you aren’t sharing either structure or quality. Imagine you have an employee database, which is highly curated and therefore of high quality. Imagine that you decide to harvest data about your employees from social media. It will be differently structure and of course of very dubious quality. If you need a query that is accurate and of high reliability you would probably only query the structured source. If you wanted to combine the curated and the non-curated data though, the fact that it shares an ontology makes this possible.
Data Architecture
The DMBOK section on Data Architecture starts with the Zachman Framework, which claims to be an ontology (by the way this is the third references to ontology in the book, the other two were in the content management and reference data sections). The exact claim is “The Zachman Framework is an Ontology.” I think most ontologists would be puzzled by this claim, as there are none of the usual trappings of an ontology, such as classes, properties, formal definitions, inference and the like.
Most of the chapter concerns the relationship of conceptual, logical, and physical data models and the introduction of the possibility of an Enterprise Data Model.
Semantics and Knowledge Graph upend most of these notions, and drastically change the emphasis. In a Knowledge Graph we essentially implement the conceptual model. With Data-Centric we drop the level of complexity to the point where an Enterprise Model is understandable and directly implementable. But perhaps the most profound shift in architecture is the recognition that a Data-Centric Architecture has to take on a great deal of functionality that has historically been given over to applications, such as authentication, authorization, identity management, constraint management, query federation and much more. In a Data-Centric Architecture it becomes the job of the architecture to handle these functions once, at an enterprise level, and not thousands of times inconsistently per application.
Summary
My guess would be left to their own, DAMA would probably eventually add another wedge to the wheel for semantics, but I don’t think that recognizes what is really going on. If you agreed with what I wrote above I think you’d agree that it changes the whole wheel, pretty profoundly.
Perhaps it’s time for SemBOK.
P.S. I wrote an article for this blog, but it ended up being too long. If you’re interested in a comparison between Property Graphs and Knowledge Graphs, check out Property Graphs: Training Wheels on the way to Knowledge Graphs.
