 This is the second part of a three-part article intended to clarify the translation required between the essential view and a relational database designer’s view. To visit the first part of the series please click here.
This is the second part of a three-part article intended to clarify the translation required between the essential view and a relational database designer’s view. To visit the first part of the series please click here.
Previously, after an introduction explaining the relative roles of the Essential Data Modeler and the System/Database Designer in the development of a system that can be meaningful for a system/data consumer to use, that article described the first two steps in converting a relatively abstract Essential Data Model into a practical Logical Database Design.
–
–
–
The first two steps are:
- Step 1 – Perform default database design
- Step 2 – Resolve sub-types
This part continues the description of that process with the next step:
- Step 3 – Deal with Parameters / Characteristics
Part Three will then address the final two steps:
- Step 4 – Deal With Derived Attributes
- Step 5 – De-normalize, if necessary
Step 3: Deal with Those Parameters
Some entity classes (Party or Person, for example), on the first pass, have a lot of attributes. The values of them change over time. Moreover, the attributes themselves come in and out of existence over time. Their definitions also change.
Managing the database design (and of course the data models) in this environment is a major maintenance expense that continues for a very long time after the system is complete.
We need an alternative approach. The Essential Model provides one. First it limits attributes in most entity types to:
- For reference entity types:
- “Identifier” or “Abbreviation”,
- “Name”, and
- “Description”.
- For intersect (transaction) entity types:
- “Sequence number”,
- “Effective Date”,
- “Expiration Date”,
- And one or more “Values”.
With few exceptions, other “attributes” should be instances of Characteristics ( or Parameter, Attribute, or some such).
The value of each Characteristic is then contained in an intersect entity type that links the definition of it with one instance of the thing it is a Characteristic of.
For Example:
Party Characteristic
In Figure 1, Party Characteristic is “a distinguishing trait, quality, or property that can be given a value for a Party.”[1] Each Party Characteristic must be, in turn, part of exactly one Party Characteristic Schema. This is a category used for organizing Party Characteristics. For example, a Party Characteristic Schema could be “IRS Business Activity”, with component Party Characteristics being entries on a list published by the US Internal Revenue Service. In another case, the Party Characteristic Schema could be “Personal Physical Characteristics”, with components “Height”, “Weight”, “Eye color”, etc.
Note that each Party Characteristic itself must also be the responsibility of one and only one Party. Thus the Person characteristic “US Social Security Number” is the responsibility of the US Social Security Administration. Data reperesnting Person (personal) characteristics, such as “height” and “weight”, would be the responsibility of the company’s Human Resources Department.
Party Characteristic Value
Party Characteristic Value is “the fact that a particular Party is described by a particular Party Characteristic.”
That is, each Party Characteristic Value must be for one and only one Party Characteristic and to describe one and only one Party. Each instance of a Party Characteristic Value must be uniquely identified by a combination of both the relationship to Party, and the relationship to Party Characteristic.
In its simplest form, the Party Characteristic entity type is simply an instance of a set of values that make up a particular Party Characteristic Schema. For example, for the Legal Entity, “Essential Strategies International”, one Party Characteristic Value is simply selection of the of the Party Characteristic with the name “Management Consulting Services” and a Code of “541600”. This instance is part of the Party Characteristic Schema, “IRS Business Area”.
In this case, Part Characteristic Value links one Party to one Party Characteristic.
Moreover, the fact that Party (Organization) “Essential Strategies International” is described by the Party Characteristic Value that is for “Management Consulting Services” must also be issued by one and only one identifiable Party. In this case, the Party involved would have been President David C. Hay.
A more sophisticated version of Party Characteristic Value defines it as “the fact that a particular Party Characteristic has a specific “Value” for a particular Party. In this case, one of the “Value…” attributes (see below) will be filled in. For Example, Party Characteristic could be “Height”. A Party Characteristic Value “Value – Number”, then, could be “67” (inches)[2] for Party Characteristic “Height”, to describe the Person (Party) “George Miller”.
The Characteristic “Height” could be the responsibility of The Data Governance Committee, and the “Value – Number” for George Miller could have been issued by George Miller himself.
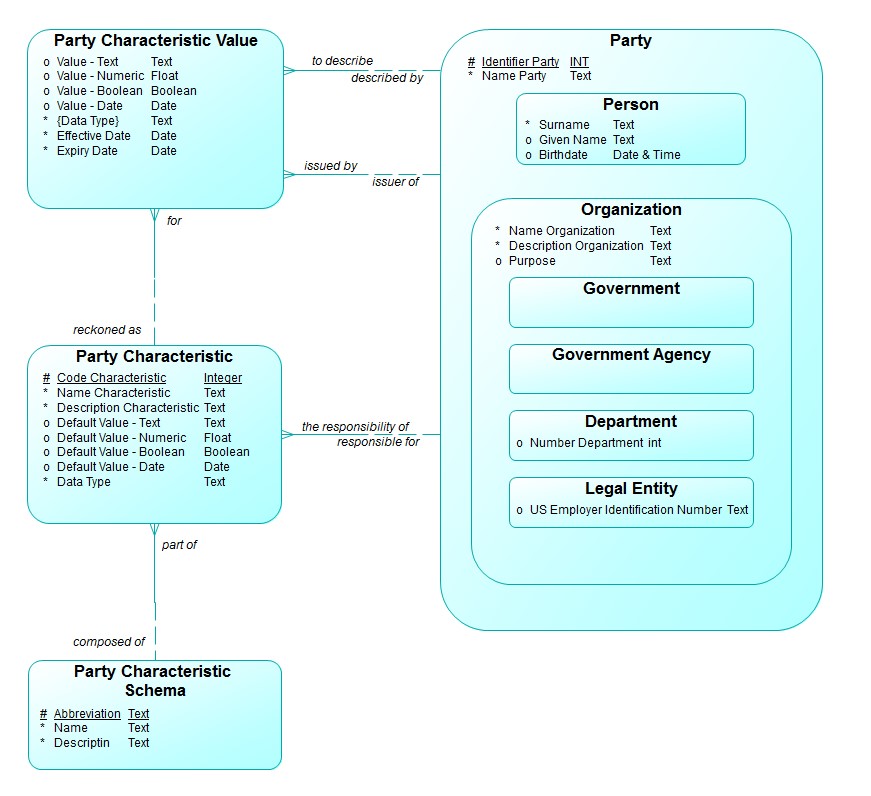
Figure 1: Party Characteristics
Data Types
There is one complexity that comes up. If this is to be a generic model, it must deal with different data types. The data type is a function of the particular Party Characteristic involved. Thus:
- Party Characteristic Value {Data Type} may be inferred from the “Data Type” column in the associated Party Characteristic
Then you have the attributes:
- Value – Text
- Value – Number
- Value – Boolean
- Value – Date
Depending on the Party Characteristic Value {Data Type} involved, only one of these attributes would have a value.
Again, note that this is only relevant for those Party Characteristics that receive a value specific to the Party. If the Party Characteristic is simply one of a list of values, there is no “Value…” value at all.
The Issue
Clearly, where columns are multi-valued or of limited life, stashing them in a …Characteristics table is the best way to go. There are cases, however, where it is appropriate to simply define attributes (for example, Person or Organization). For example, suppose the attributes shown in Figure 1, Department “Number Department” and Legal Entity “US Employee Identifier Number”, had, in fact, been converted to Party Characteristic “Name Characteristic”; then the entity Party Characteristic might look like this:
Party Characteristic
| Name | Description | Party Type |
| Birthdate | The day the person appeared on Earth | Person |
| Height | Vertical Distance to measure something | Person |
| Surname | The name of the Person’s family (also, “Last Name”) | Person |
| Given Name | The name of the individual person. | Person |
| Annual Sales | Average sales in a year | Legal Entity |
| US Employee Identifier Number | IRS Tax identifier | Legal Entity |
| Number Department | An integer that uniquely identifies a Department | Department |
It could then be implemented as the following tables: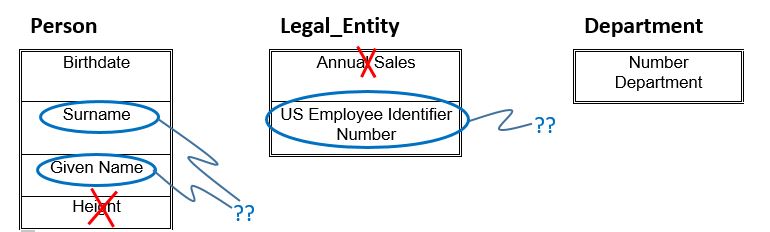
It is reasonable to expect that Person “Birthdate” is an attribute that will not be discontinued or significantly reformed. Moreover, an instance of Person is very unlikely (!) to ever have more than one “Birthdate”.
Similarly—in most cases—it is reasonable that a Person’s name won’t change once it’s entered. Different organizations, however, have different requirements for dealing with the possibilities that either “Surname” or “Given Name” may in fact change. For example, it could be assumed that the “Surname” and “Given Name” columns in a particular system always contain just the “latest value”, with an audit function being maintained outside this database.
On first pass, it would also appear that the same could be said about a Legal Entity’s “US Employee Identifier Number”. In this case, however, some caution may be required.
As long as the company only operates within the United States, this is fine. If the company will operate internationally, however, the attribute approach will make things very difficult. It is possible that you could get away with “National Tax ID” as a generic text field, although the underlying formats will actually be different. Alternatively, if you had Party Characteristics defined as “US Employee Identifier Number”, “UK Tax ID”, “Canada Tax ID”, etc., you would be safer. Among other things, this means you can now have more than one of these for a particular Legal Entity.
(Thus, “US Employee Identifier Number” shown in Figure 1, should in fact not have been an attribute of Legal Entity—even in the Essential Data Model.)
Since it can be used as an alternative identifier for Department implemented as a table, Department “Number Department” should remain as a column in that table.
Clearly, a Person’s “Height” will change over time. Now, if the only interest is in having available the latest value of h’[3] “Height”, it can be a column in the table Person. Even then, it may be necessary to at least add a column “Height Value Date”, or some such.
That is, Person’s “Height” would be better maintained as a dynamic Party Characteristic.
The “Annual Sales” for a Legal Entity is clearly a number that will change over time. At the very least, the value will be pegged to a calendar (or fiscal) year. It cannot readily be stored as an attribute of Legal Entity.
Generation – Version One
Note that to implement this structure we again have the issues of what to do about the sub-types, as discussed in Part One of this essay. For no particular reason, this model is rendered in IDEF1x.
The sub-types of the Essential Model Party not only inherit the super-type’s attributes, they also inherit the relationships associated with the super-type as well. If the generation of the logical model collapses all the sub-types into a single table, this is not a problem. You can see the result in the Logical Model shown in Figure 2:
- Each Party may be described by one or more Party Characteristic Values.
- Each Party may be the issuer of one or more Party Characteristic Values.
- Each Party may be responsible for one or more Party Characteristics.
- Each row of Party Characteristic Value is now identified by a primary key that consists of 1) the foreign key “Par_Identifier_Party”, pointing to Party along the to describe relationship, plus 2) the foreign key “Global_Characteristic_Identifer”, pointing to Party Characteristic along the for relationship.
That is, the IDEF1x notation shows that the relationships:
- Each Party Characteristic Value must be to describe one and only one Party, and
- Each Party Characteristic Value must be for one and only one Party Characteristic…
… Are shown as identifying relationships (with solid lines).
- In addition, in Party Characteristic Value, you have foreign key, “Identifier Party”, pointing to Party along the issued by relationship, and in Party Characteristic, you have a foreign key ‘Identifier_Party”, pointing to Party along the responsibility for (This is not an identifying relationship.)
- What this means is that Party Characteristic is a collection of the characteristics for any and all kinds of Parties, organized in terms of Party Characteristic Schemas.
Recalling the discussion above about the unique identifier, note that here, it is possible to specify the “Par_Identifier_Party” as part of the primary key.
Note that the foreign key columns were all generated by the CASE tool. Names are not entirely clear. It is worth a moment to make them a bit more understandable. Table 1 shows candidates for these column names.
Table 1: Improved Column Names – V1
| Table Name | Old Column Name | New Column Name |
| Party Characteristic Value | Par_Identifier_Pary | Describe_Identifer_Party |
| Party Characteristic Value | Identifier_Party | Issued_Identifier_Party |
| Party Characteristic | Identifier_Party | Defined_Identifier_Party |
| Party Characteristic | Abbreviation | Party_Characteristic_Abbreviation |
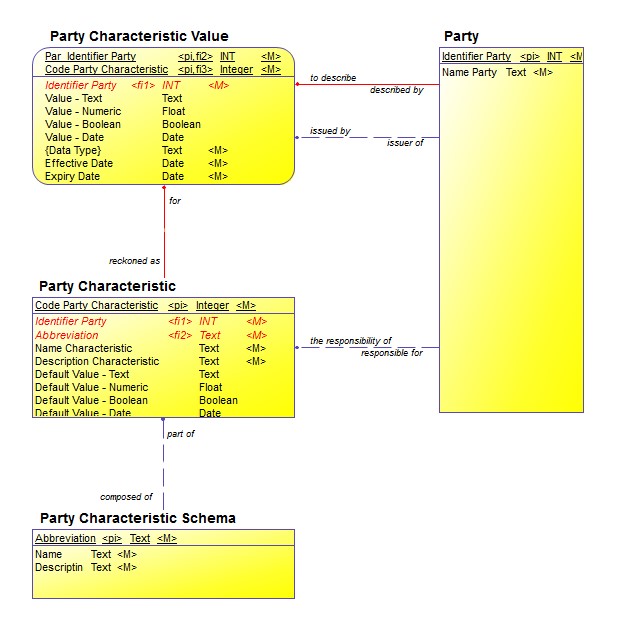
Figure 2: One Version of the Logical Model
Generation – Version Two
What if we don’t want to have a single table for all Parties? It gets very complicated if we try to generate a separate table for all sub-types—but to give you an idea of what we’re up against, check out Figure 3. Here, all we’ve done is to split the Party entity type into a Person table and an Organization table, both connected to Party Characteristic Value and Party Characteristic. The to describe/described by and issued by / issuer of relationships are replicated for the two cases.
Remember that in the Essential Model, the unique identifier of Party Characteristic Value included the relationship, “each Party Characteristic Value must be to describe one and only one Party”. Here, however, that relationship is implemented by two foreign key relationships. To be sure, there is still a single foreign key column (here renamed from “Par_Identifier_Party” to “Described_Party”) that implements both foreign keys “fk2” and “fk3”. Even though it is a single column that implements both foreign keys, this column cannot be a primary key.
What will be required is a second instance of each column, so that the “arc” between them can be implemented.
That is, the columns would then be:
- Described Person <fk2>
- Described Organization <fk4>
Neither of these are part of the primary key. Some sort of programming logic is required to implement the “arcs”:
- Either “Described Person” or “Described Organization” is mandatory—‘if there is no value for the other one.’
- ‘If there is a value for the other one, no value is permitted for this one.’
The same “arc” logic applies to the newly defined columns:
- Issued Person <fk3>
- Issued Organization <fk5>
… as well as the new pair of columns in Party Characteristic:
- Responsible Person <fk2>
- Responsible Organization <fk3>
A new column is required that, in combination with the relationship to Party Characteristic, will establish uniqueness. One candidate could be “Effective Date”, but there is no guarantee that there won’t be more than one evaluation of a Party Characteristic on the same day.
So, a surrogate key is required. In Figure 3, it is “Sequence Number”, which is defined in the context of the Party Characteristic involved. That is, “Sequence number” is “an integer that uniquely identifies each Party Characteristic Value in the context of the Party Characteristic that it is for.” (For example, the 3rd value for the Party Characteristic “Height”.)
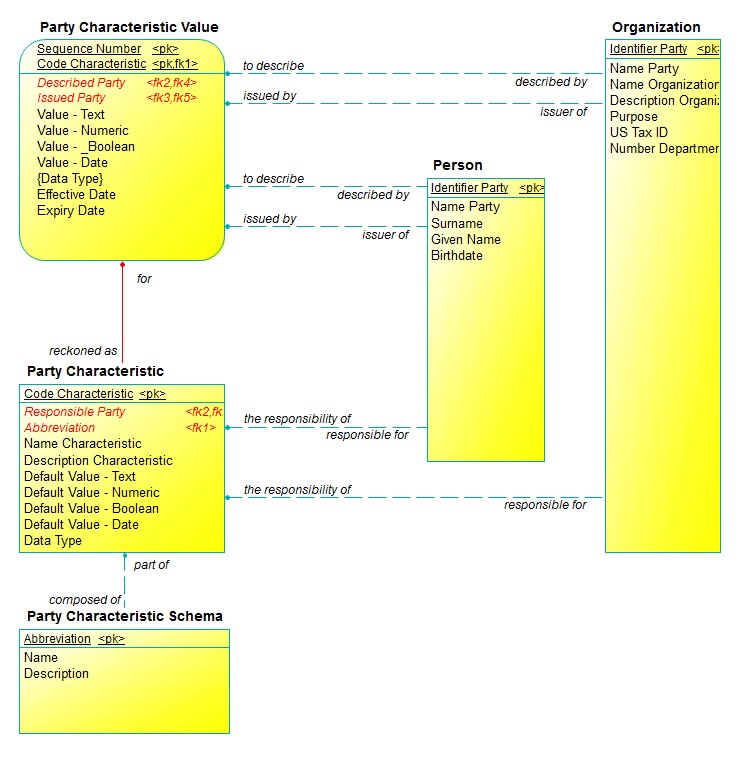
Figure 3: Version Two of the Logical Model
Note that the Person and Organization tables each default to having “Identifier Party” as its primary key. Since this was inherited from Party in the Essential Model, but it has not passed to this implementation, it will be necessary to specify keys specific to these tables. “Identifier Organization” and “Identifier Party” naturally spring to mind. These are shown in Figure 4. Also in Figure 4 is the clarification of the foreign key columns in Party Characteristic Value. Each of the columns now specifies a single “<fk>”.
Again, not shown in the physical schema, a rule must be implemented to represent “arcs” to assert that each Product Characteristic Value must have a value either for “Described Organization”, or for “Described Party”, but not both. Similarly, each Product Characteristic Value must have a value either for “Issued Organization”, or for “Issued Person”, but not both.
Similarly, in Party Characteristic, “Responsible Organization” points to an Organization, while “Responsible Person” points to a Person. Note that again, an “arc” must be implemented to control that each Party Characteristic must have a value either for a “Responsible Organization”, or for a “Responsible Person”, but not both.
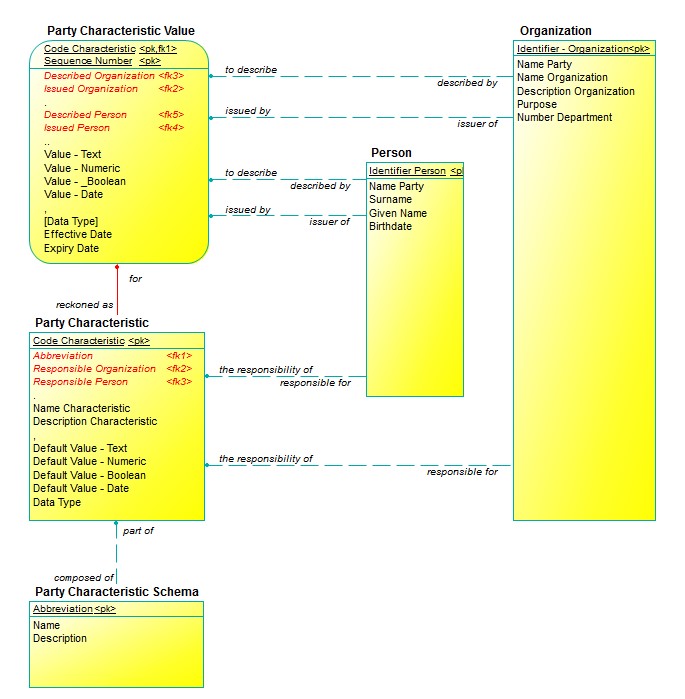
Figure 4: Version Two – Enhanced
In this chapter, we have used characteristics of Party to describe the processes and issues of determinng which should be implemented as columns and which should be implemented as …Characteristic tables. Note that both the logic and the issues involved apply equivalently to Project Characteristic, Asset Characteristic, Activity Characteristic, or any other entity described in this way.
Summary
If …Characteristics (or …Parameters or some such) are to be implemented as columns residing in a particular table, they must have the following so-called characteristics:
- They must be single-valued, even over time.
- They must be defined permanently for the owning table.
Otherwise, implementing the …Characteristic Structure described here is preferable.
On to Part Three . . .
Part Three of this series, in two months, will address steps 4 and 5.
- Step 4: Deal with computed columns.
- Step 5: De-normalize, as necessary
Footnotes
[1] This is based on the definition of “attribute”, found in Barker, R. 1990. CASE*Method: Entity Relationship Modeling. Wokingham, England: Addison-Wesley.
[2] Unit of Measure is another modeling topic, not covered in this article.
[3] As an amateur logician, your author is averse to using the plural pronoun “their” to mean “his or her.” Same with “they.” So, he has initiated a campaign to use the contraction h’ to mean either “his or her.” Similarly ‘e means “he or she.”
Remember, you read it here first.
