For years the worlds of structured systems (transactions, data bases, Oracle, DB2, Teradata, et al) have grown up side by side with the world of unstructured systems (email, telephone conversation
transcripts, spreadsheets, reports, documents). And for years these worlds have existed as if they were in isolation. The world of structured technology did not have anything to do with the world
of unstructured technology, and the world of unstructured technology did not have anything to do with the world of structured technology. It was as if there were a huge gap – a gulf of indifference
– between the two worlds.
After these two environments matured and grew to a large size, it was recognized that there was value in the integration of the two worlds. The problem was that the two worlds were fundamentally
different. One world was very disciplined and orderly; the other world was very undisciplined and very disorderly. The two worlds were as different as any two things can be.
But recent technology (Inmon Data Systems) has allowed these two worlds to become integrated.
In integrating the two worlds, it is soon discovered that the means for integration (the lingua franca) is text – words, phrases, and symbols. The commonality between the two worlds centers around
the ability to match text between structured systems and unstructured systems. Therefore text matching becomes central to the understanding of how structured systems and unstructured systems can be
integrated.
There are (at least!) five states of matched data between the two environments. Those five states are –
- no matching whatsoever,
- coincidental textual matches
- hard wired matches
- probabilistic matching
- metadata matching.
In reality there are probably many other ways to match the data between the two worlds. But these five approaches (one of which is no approach at all) constitute the ways in which structured data
sits next to unstructured data.
NO MATCH
One possibility for bringing unstructured data into the structured environment is to not attempt to match the data between the two environments at all. Fig 1 shows this approach.
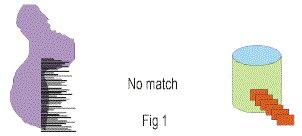
In this case the unstructured data is edited and manipulated outside of the structured environment, placed in a structured format (i.e., a relational format) and then is entered into the structured
environment. In doing so, the unstructured data can be stored in standard structured technology such as DB2, Oracle, or Teradata. In addition the unstructured data can be accessed and analyzed by
standard technology such as Cognos, Business Objects, MicroStrategy, Crystal Reports, and so forth. Note that when placed in the structured environment in this format, the unstructured data is NOT
in a blob format.
There are many possibilities for the analysis of unstructured data in a standalone format. The possibilities include –
- auditing unstructured data – looking for compliance to HIPAA, Sarbanes Oxley, and so forth,
- looking for patterns – is a new product being received well in the marketplace,
- legal protection – did a company have advance warning that there was a danger in their products from the complaints made by the customer base, and so forth.
So the first format of structured data and unstructured data residing together is that of not interfacing the two worlds at all, but having the unstructured data in a structured format and doing
analysis directly on the unstructured data.
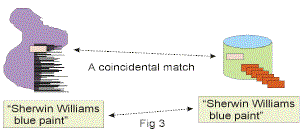
COINCIDENTAL MATCH
The second choice for matching structured data and unstructured data when the two types of data have been placed in the structured environment is to execute what can be called the “coincidental
match”. Fig 2 illustrates the coincidental match.
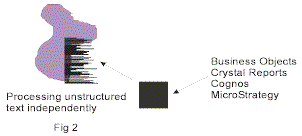
In Fig two it is seen that structured data and unstructured data are in the structured environment. A simple match based on text is made between the two environments. As a simple example of such a
match, suppose an email mentions “Sherwin Williams paint” and an inventory list also mentions “Sherwin Williams paint”. A comparison between the text in the email and the inventory list will
expose the linkage between the two environments.
One of the problems with a coincidental linkage between the two environments is that there may or may not be the proper context for the linkage. In other words, the coincidental linkage is raw and
may or may not have any relevance or meaning when examined together. The only implication is that the same word or phrase has been found in multiple places.
Fig 3 shows a coincidental match between the structured data and the unstructured data.
HARD WIRED MATCH
The third possibility for the matching of data between the structured world and the unstructured world is that of the “hard wired match”. A hard wired match is one that is based on some very
concrete identifier. Some common identifiers are email address and telephone number. These two identifiers are very commonly found in the structured environment and the unstructured environment.
Fig 4 shows a hard wired match.
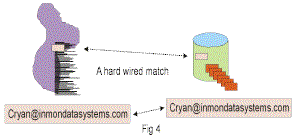
In Fig 4 it is seen that a match is made between email address found in the structured environment and the unstructured environment.
There are other less commonly found identifiers, such as passport number, employee id, drivers license number, social security number and so forth.
While hard wired identifiers between the structured environment and the unstructured environment are very useful, in many cases they don’t exist. A second issue is that over time these numbers
change. Every two years or so a person’s email address is likely to change. That presents a challenge to technology depending on the hard wired match.
And a third problem with the hard wired match is that it does not have perfect integrity. As an example of the fallacy of the integrity of a hard wired match, consider the following set of
circumstances. Suppose I am visiting at ABC corporation. I am working with Sue Smith at ABC corporation. Sue goes to lunch and while she is at lunch I look on the Internet at the stock market. I
see that things are falling in the stock market. I pick up Sue’s phone and tell my broker to sell a thousand shares of ABC corporation.
A month later an audit is done and it is seen that an order to sell shares was made from Sue’s phone. Sue is now accused of insider trading.
From this simple example (which is not too far fetched) it is seen that just because a person has a phone number attached to their name does not necessarily mean that the person actually has
exclusive use and control of the phone number.
PROBABILISTIC MATCH
Perhaps the most common and the most useful type of match that can be done between the structured environment and the unstructured environment is that of the probabilistic match. Fig 5 shows a
probabilistic match.
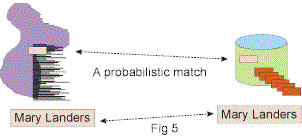
In Fig 5 it is seen that the name “Mary Landers” is found in both the structured environment and the unstructured environment. The assumption is that they are PROBABLY the same person.
A probabilistic match is one where there is a likelihood of a true match but a possibility of an untrue match. With each match a probability of accuracy is assessed. An assessment of .9 means that
there is a good probability of a match. An assessment of .1 means that there is little confidence in the match.
The reason why a probabilistic match between the structured environment and the unstructured environment is so powerful is that the opportunity for such a match arises very frequently. Contrast the
probabilistic match against the hard wired match. While there is a relatively high degree of confidence attached to the hard wired match, the opportunity to use a hard wired match does not occur
very often. But the opportunity to use a probabilistic match occurs very frequently. Therefore, even if there is an air of uncertainty associated with a probabilistic match, because the occasion to
use a probabilistic match occurs so frequently, probabilistic matches are very important.
As an example of a probabilistic match for which there is a low level of confidence, refer to Fig 6.
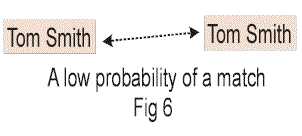
Fig 6 shows that the names “Tom Smith” are found in both the structured environment and the unstructured environment. Now there is nothing wrong with the person known as “Tom Smith”. The
problem is that the name “Tom Smith” is so common. There are lots of “Tom Smith”s running around out there. Therefore, the probability of a true match is low, maybe as low as .01% (which is
very low).
Now let’s consider another case. Consider the probabilistic match made in Fig 7.
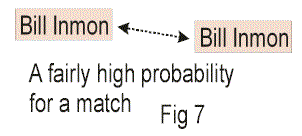
In Fig 7 it is shown that there is a match between the structured environment and the unstructured environment on the name “Bill Inmon”. The name “Bill Inmon” is much less common than the name
“Tom Smith”. Therefore, the probability of a true match on “Bill Inmon” may be as high as .7. But, there are still more than one “Bill Inmon”s running around (check out the Internet on people
search). So the probability of a true match is less than 1.0.
Of course if we start to throw other qualifying data into the match criteria, we can raise the probability of a true match much higher. Look at the match made in Fig 8.
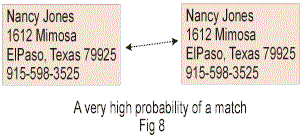
In Fig 8 it is seen that a match has been made between the structured environment and the unstructured environment. The name is very common. But the corresponding address is very unique. The common
name coupled with the uncommon address makes for a very high probability of a true match indeed. The probability of a true match is very close to 1.0.
However, in even the best matches there is always the infinitesimal chance that a true match has not been achieved.
There is a famous case where two babies were born in the same hospital, on the same day, with the exact same name. While such a coincidence is very rare, it is always possible. For this reason the
probability of 1.0 is rarely achieved when doing a probabilistic match.
METADATA MATCH
The fifth possibility for a match of data between the structured environment and the unstructured environment is that of a metadata match. Fig 9 shows a metadata match.
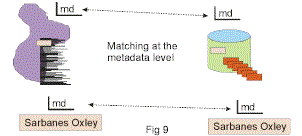
In Fig 9 it is seen that the same metadata is found in both environments. There are two problems with a metadata match –
- the match is for a classification of data, not actual data itself, and
- there often is not much metadata found in the unstructured environment.
These then are the possibilities for the matching of data between the two environments. There are special considerations in the application of these techniques. Using these techniques is kind of
like a surgeon selecting which instruments are the most appropriate for an operation.
About Inmon Data Systems
Founded in Colorado by Bill Inmon, Guy Hildebrand and Dan Meers, Inmon Data Systems (IDS) is a software company dedicated to the proposition that there needs to be a bridge between the worlds
of structured data and unstructured data. IDS has foundation technology that allows unstructured data to be brought into the structured environment and once there, integrated into the structured
environment.
Applications – unstructured visualization (with Compudigm)
- Enterprise metadata consolidation
- CRM enhancement
- Communication compliance
- Email and unstructured indexing for bulk storage
IDS is located in Castle Rock, Colorado.
Contact IDS at 303-973-3788 for further information.
