 Abstract
Abstract
The world is changing more quickly than ever particularly in the area of multi-channel data flows. The shift from the industrial age to the information age combined with the current security, safety, financial and economic crises are already impacting our behavior and we are becoming more and more data driven. The survival of any enterprise or organization will depend on four characteristics that will ensure its sustainability and support its growth: agility; Trust; Intelligence and Transparency. In the current economic climate, we believe that these characteristics are fundamental pillars. More than ever, data quality and governance are keys to global sustainability. We present in this paper an innovative framework and a governance model enabling any enterprise or organization to measure, monitor, and continuously improve in the domains of safety and security.
1. Introduction
Our security and safety depend highly on the quality of the data present in the information system because, in most of our activities, we are relying on computers. For example, at any airport in any country the precision of detecting terrorism or fraud will rely highly on the data stored in their databases. If the quality of this data is not optimal, it is obvious that our security could be compromised. We can also cite the example of any product in the food industry that may contain allergens. The consumers rely on the information written on the packaging. If this data is not 100% correct there could be an impact on the consumer’s life. We can continue with this type of example to illustrate the importance of the quality of the data we are consuming especially when it comes to our safety and security.
Our objective is to present a unified practical and executable framework enabling us to measure the ‘as is’ and evolution of data in the global environment to strive for Data excellence and maximize human safety and security.
We will therefore elaborate:
- The vision and the mission of the Data Excellence Framework [1] including a data excellence maturity roadmap.
- The semantic rules approach to support security and safety processes and enable their performance and effectiveness.
- The five data quality dimensions based on semantic rules.
- How to leverage the Data Excellence Framework in the area of safety and security.
- The mathematical model to calculate and publish KSIs (Key Security Indicators) and anomaly reports enabling an increasing degree of security and safety governance.
- How to achieve security and safety excellence through the governance of critical safety and security rules.
As a result of our model, the overall KSI (Key Security Indicators) will represent the ‘Trust’ index of the data stored in the database. The ‘Trust’ index will help give visibility and encourage further improvements. Its accuracy depends on the quality and on the intelligence of the rules included.
2. The Data Excellence Framework (DEF)
The Data Excellence Framework is a set of common methods, definitions, tools, processes, roles and responsibilities to measure the ‘as is’ and monitor the evolution of the data, rules, and values in an information system.
It is a comprehensive methodology aiming to govern data with transparency and effectiveness to maximize the data’s value and usage. The DEF can be used as key enabler for proactive Governance of Global Security and Safety through the definition, measurements, and governances of the basic and most critical rules related to security and safety processes in any domain or industry. These rules will be implemented as semantic methods [2] using a semantics based technique, MMS (Méta Modèle Sémantique) / SMM (Semantic Meta Model) [3] to compute the degree of data compliance with the rules, and to filter and extract the exceptions and deviations.
3. The Semantic Rules Based Approach
The semantic rules are rules that data should comply with in order to have processes execute properly [4]. They are expressed in natural language and can be organized by domain in semantic meta bases following Walid el Abed’s SMM / MMS model [5] to make them language independent in a multilingual environment. The semantic rule-based approach is a unique value proposition representing the backbone of the Data Excellence Framework, supporting the five data quality dimensions that we will discuss later in this paper.
The semantic rules are defined and structured according to a specific format (see Table 1):
| Group | Attribute | Example |
| Identification | Code | SR-00001 |
| Version | 1 | |
| Name | Allergen Data Completeness | |
| Description | All food or medical products must consistently (across all processes and databases) include data on the allergens contained in its constituents and raw materials | |
| Quality dimension | Completeness | |
| Owner | Healthcare manager | |
| Steward | Product manager | |
| Objective | Trust | Yes |
| Intelligence | ||
| Agility | ||
| Transparency | Yes | |
| Impact | Processes impacted | Product manufacturing, product packaging, product distribution. |
| Scope of the impact | Any potential consumer of the product. | |
| Criticality | High, consumer life may depend on the allergen data. | |
| Query | Data source | Production database, packaging database. |
| Tables | ||
| Fields | ||
| Semantic meta network [6] |
Table 1. Semantic rules structure
Applied to the security and safety domain, it enables us to use the KSI (Key Security Indicator) at the record level to address the root cause of defects related to the security and safety information in the information system. This is shown by, for example, a safety rule which states “All food or medical products must consistently (across all processes and databases) include data on the allergens contained in its constituents and raw materials.” A semantic method will be used to measure the compliance of the product data with this specific rule, and determine the exceptions related to the rule. This will enable the completion of the missing allergen data and help address the root cause by allowing for the analyses of the processes dealing with allergen data.
4. The Data Quality Dimensions
The data excellence framework defines five data quality dimensions (uniqueness, completeness, accuracy, non-obsolescence, and consistency). The semantic rules are grouped by these dimensions. Each rule belongs to a single data quality dimension. Table 2 depicts the definition of the five data quality dimensions:
| Dimension | Description | Applied to security and safety |
| Uniqueness | The uniqueness dimension is the collection of semantic rules that allow the identification in a deterministic way of an entity, a relationship, or an event instance within a specific context to execute a specific process. | Semantic rules that the data must comply with to ensure unambiguous unique instances of the data required to execute a security or safety process. |
| Completeness | The completeness dimension is the collection of the semantic rules that guarantee that all data required for a successful execution of a process in a specific domain and context are present in the database. | Semantic rules ensuring the presence of all data required for the execution of a safety or security process. |
| Accuracy | The accuracy dimension is a collection of semantic rules ensuring that the data reflects the real world view within a context and a specific process. | Semantic rules ensuring the correctness of the data required for the execution of a safety or security process. |
| Non-obsolescence | The Non-obsolescence dimension is a collection of semantic rules that guarantee that the data required to execute a specific process in a specific context is current and up to date. | Semantic rules ensuring the currency of the data used for the execution of a safety or security process. |
| Consistency | The consistency dimension is a collection of semantic rules required to ensure that the data values are consistent across all the databases and systems for the execution of a specific process in a specific context. | Semantic rules ensuring data is consistent between different sources used in a safety or security process. |
Table 2. The data quality dimensions
In summary, the five data quality dimensions applied to global security enable a more precise view of the quality of the data contained in a database and can be used for the execution of a safety or a security process or procedure. The collection of all semantic rules related to a specific security process for the five data quality dimensions must answer the following question: “Do I have a unique, current, complete, exact, and consistent view of the data I need to take a decision or to perform an action during the execution of this specific security process?”
5. The Mathematical Model (Key Security Indicators)
A key security indicator is an indicator that shows the percentage and evolution of compliance of the data to the semantic rules related to security and safety processes. It will be used to drive corrective or preventive actions and to correct the data errors related to security and safety process.
The mathematical model includes three components:
- The calculation of the percentage of compliance to a specific semantic rule of the data rows related to a main security or safety entity (Product, Person, Service, etc.). This percentage is obtained by the following formula: 100-((Total number of non-compliant data rows/ (Total number of data rows) * 100).
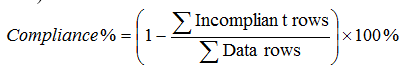 This indicator will be called the atomic key security indicator. It is atomic because we are measuring at the lowest level which is the semantic rule level, and therefore it cannot be decomposed.
This indicator will be called the atomic key security indicator. It is atomic because we are measuring at the lowest level which is the semantic rule level, and therefore it cannot be decomposed. - The aggregation model (polarization) is calculated at a higher level than the Key Security Indicator. For example, the completeness key security indicator is the percentage of data rows compliant with all completeness semantic rules related to safety or security. The data row will be considered non-compliant if it deviates from at least one semantic rule of the quality dimension collection. At any level of aggregation (polarization) the Key Security Indicator will represent the percentage of data rows compliant with the collection of semantic rules related to the security or safety grouping level. It is important to note that double counting must be avoided; the data row must be counted only once regardless of the number of semantic rules violated. The overall Key Security Indicator is the percentage of data rows compliant with the collection of all the semantic rules related to security and safety processes. It will be obtained by the following formula:
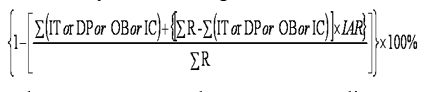
Where IT=Incomplete, DP=Duplicate, OB=Obsolete, IC=Inconsistent, Number of data rows in scope=R, Inaccuracy ratio=IAR. The aggregation model allows for drill downs and rollups at any level of the key security indicator and the related non-compliant data rows.
- The error handling component consists of combining all the deviations related to a specific Key Security Indicator in a single data row representing the identification of the security entity (person, object or service) and the values to be corrected according to the semantic rules applied. The exception report is dynamically generated for the KSI in any aggregated format.
The evolution trend is calculated for the last six months based on the value of the KSI, including changed and new semantic rules. The evolution trend is displayed as a 3rd-level polynomial regression.
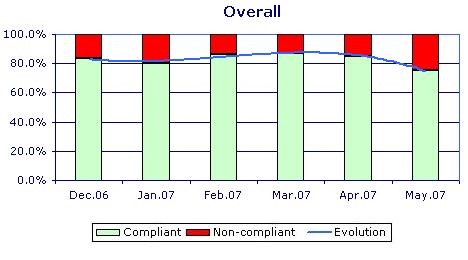
Figure 1. The overall Key Security Indicator
6. Data Excellence Process to Improve Security and Safety
The data excellence process consists of five phases:
- Identification and scoping of the security domains and their processes; defining the security and safety rules and governance model.
- Defining the Key Security Indicators and their data collection and reporting or publishing them.
- Driving data corrections per security or safety domains, achieving KSI targets for each individual semantic rule.
- Implementing processes and semantic rules to prevent further data pollution from external source systems or data entry.
- Monitoring and continuously striving for Data Excellence.
The process below depicts the continuous data excellence process flow and the organizational roles required for the governance of the security and safety rules.
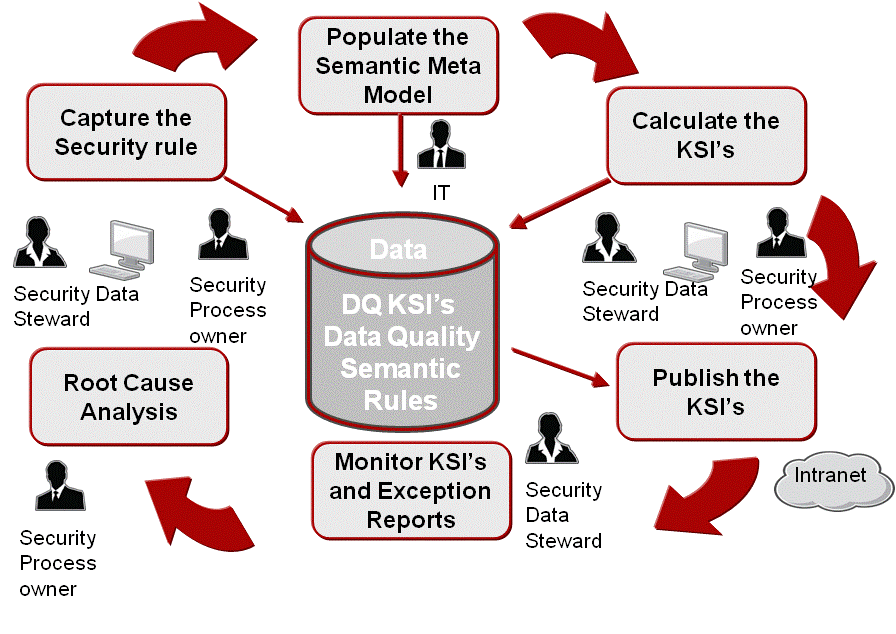
Figure 2. The data excellence process
At the action and activity level, we consider that data excellence in the domain of security and safety can be achieved in five steps process as illustrated in Figure 3 below.
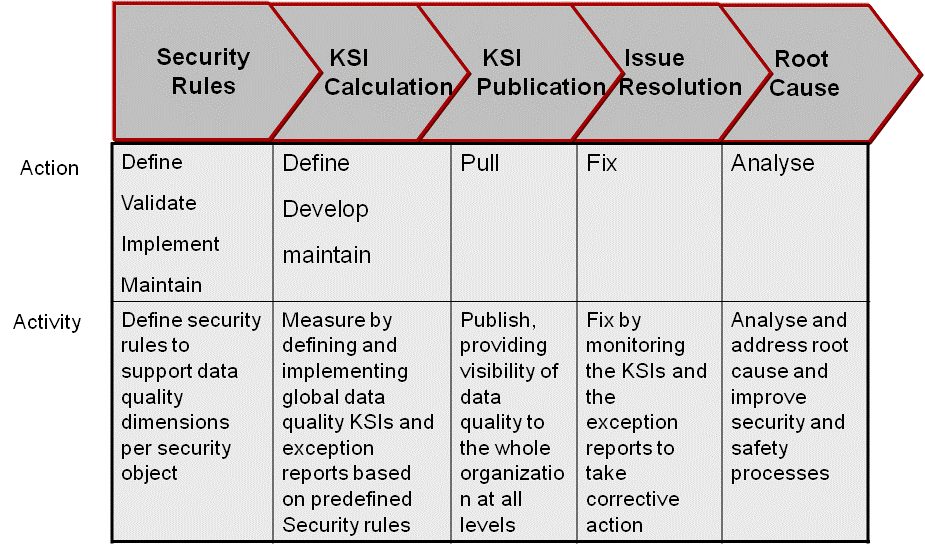
Figure 3. Data Excellence steps and actions
7. The Data Excellence Governance Model
Safety and security governance can be executed through semantic rules stewardship. Stewardship is the willingness and commitment to be accountable/responsible for a set of semantic rules for the well-being of the Enterprise by operating in service of the global community rather than one’s own interests [7]. This can be fulfilled with three main roles:
- The safety and security semantic rules accountant who will be in charge of defining, validating, prioritizing, and setting the objectives of the security rules.
- The security steward who will be in charge of following the KSI and coordinating with the data respondent to take corrective actions.
- The security and safety data respondent who will be in charge of correcting the data deviating from the security rules.
The governance model in Figure 4 will be supported by the security and safety data excellence group who will be in charge of facilitating the data excellence processes within the organization, coaching the stewards and maintaining the knowledge and the stewards’ network.
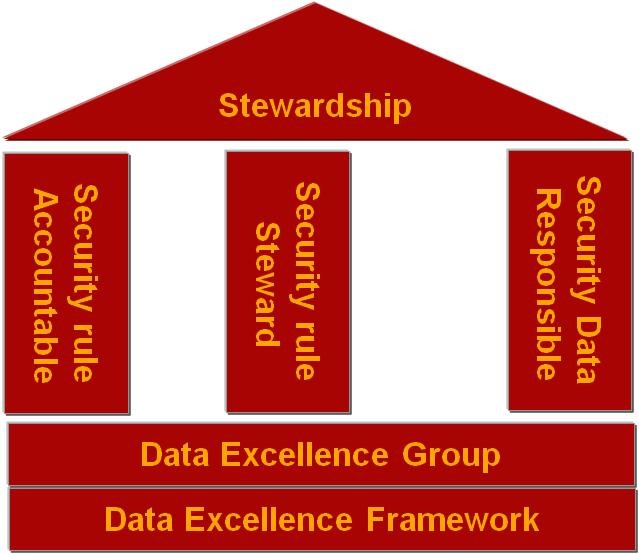
Figure 4. The Data Excellence Governance model
8. Conclusion
We presented a comprehensive framework based on the governance of the critical semantic rules related to safety and security, enabling transparency and improvements through the Key Security Indicators. It is understood that the Data Excellence Framework will not solve all issues related to safety and security. However, in a digital world it will enable safety and security to become data-driven and ultimately address progressively the root cause of issues.
The approach we have described is essentially pragmatic and easy to operate. A strength of the approach we have described is the atomization of governance to a simple concept of semantic rules representing the smallest value unit that can be measured and actioned at the record level, while abstracting the complexity of implementation using semantic methods and the mathematical model we have presented. The aggregation model (polarization technique) described provides much flexibility and a full panel of different views of the Key Security Indicator. The data quality dimensions we have presented are a variable collection of semantic rules and do not have a static value even after the individual calculation of the rules. The KSI is also an empty shell that will be instantiated when we observe it in a specific way. Depending on the view, it will have a different value and a different significance, with exception reports being similar to quantum particles. What safety or security rules do I want to govern in order to secure what I eat, what I drive, and which airlines, cars, and trains I should trust?
Technology-wise, the Data Excellence Framework is currently available and fully embedded in a software system called Data Excellence Management System (DEMS) developed by the company Global Data Excellence from Switzerland.
Is it worth motivating enterprises and governments to invest in a Data Excellence Framework and System in a risky data driven world?
References
[1] EL ABED W., “Data Excellence Framework from Vision to Execution and Value Generation in Global Environment” IDQ, Information and Data Quality Conference, San Antonio, Texas, USA, September 22-25, 2008.
[2, 4, 7] EL ABED W., “ Global Data Excellence Framework (GDE-F WeA-9.0) from Vision to Value Generation” , Data Management & Information Quality Conference Europe, London, UK, 3-6 November 2008
[2] CARDEY S., EL ABED W., GREENFIELD P., “Exploiting semantic methods for information filtering”, “Filtrage et résumé automatique de l’information sur les réseaux”, in Actes du 3ème Colloque du Chapitre français de l’ISKO (International Society for Knowledge Organization), Université de Paris X, 5 et 6 juillet 2001, pp.219-225
[5] EL ABED W., “Metabase for the interrogation of infocenters in natural language; metamodel proposition» in BULAG, 24, Université de Franche-Comté, Besançon, 1999
[6] EL ABED W., “System for the interrogation of relational databases in natural language” in BULAG, Acts of the international colloquium FRACTAL 1997, Université de Franche-Comté, Besançon10-12 décembre.
