
The role of semantics in connecting logical performance-driven functions with the lexical (linguistic) functions across any interaction between humans and machines through artificial intelligence (AI) technologies have witnessed significant headwinds in recent years. Despite the abundance of historical data or contextual information, AI solution providers have struggled to augment humanistic values into key decision-making processes that involve corporate governance.
As a result, in addition to offering performance benefits, AI solution providers are tasked with providing the capability to understand human language effectively, enabling the smooth interactions between humans and machines for corporate governance.
History of Human Computer Interaction
Human–computer interaction (HCI) is research in the design and use of computer technology, which focuses on the interfaces between the user, the computer, and the ways they work together. The research and practice of HCI emerged in between the late 1970s and in the early 1980s. In the late 1970s, only IT professionals and dedicated hobbyists were interacting with computers.
In the beginning of 1980, personal computing was made available for everyone. The objective was to make it easy and efficient for less experienced users to use computer without assistance.
A new paradigm in the digital world has deeply changed the Human–machine interaction as the business needs evolved requiring more precise decision-making. In addition to that, knowledge evolved and can be found in many types of formats (paper, databases, Wikipedia, etc.). Several pieces of knowledge are disconnected within an organization and systems are not normalized and are siloed and inconsistent.
However, the language problem inherent to the organisational complexity of humans and machines’ ecosystems, combined with the tsunami of regulation and data, makes it impossible to connect the knowledge together and links it to be used wisely for the organisational value outcome.
As a result, new challenges for AI, data governance, and enterprise data management emerged, making it difficult for humans and machines to interact; and the underlying semantics is lost in translation. A bridge between human and machine interaction is needed.
A Paradigm Shift Towards Linguistics and Semantics-Driven AI
As governance and communication problem are unsolved, a paradigm shift is needed for the acceleration of value creation to overcome organisational complexity.
Many platforms and solutions exist (ERP, CRM, MDM, SRM, BI, etc.), but the current approach of handling data is fragmented due to isolated tools working in the different area of the organisation leading to siloed instinctive decisions which are leading to considerable money, time and trust loss.
Moreover, the use of analytic AI (NLP and ML) based on existing data, disconnected from knowledge and human wisdom, and ignoring the social contexts by analysing past transactions and interactions with probabilistic predictions into potential futures generates huge energy and costs.
Semantics and Language
Filtering of information extracted from the Web, or any textual data or information, is problematic for various reasons. We will be principally concerned with two of these, the first being of semantics and the second one of language.
Semantics
For the first problem, that of semantics, we mean that, in general, there is an absence of explicit semantic modelling of data on the Web. We can contrast this with, for example, the explicit semantic modelling of data in a relational database, modelling which is done before the database is constructed, and which leads to a number of benefits. One benefit is that of functionality: there is the presence of a formal calculus (SQL). Another benefit is that in terms of read access performance: there is the possibility of indexing based on the model (in practice the database’s schema) under reading rather than updating. Finally, knowledge and experience of relational data base technology is widespread.
Traditionally, for (static) ostensibly amorphous textual data in which we can say that there is an explicit absence of semantic modelling, recourse has typically been made to analytic means such as concordance techniques, which for performance needs require indexing on variously ‘words’, ‘compounds’, ‘contexts’ (often in the form of regular expressions), and in the limit linguistic elements. In other words, a model is certainly constructed, but this may be before, contemporaneous, or after the presence of the raw data. Put briefly, explicit semantic modelling is for creating an artefact (such as a data base responding to some need), analytic semantic modelling involves seeing if some set of data already in existence (some Web content) is a theorem of a previously proposed theory (model). In the case of the Web, due to the page structure, and also due to the use of mark up languages and labelling following the PICS standard, the data is not wholly amorphous and we are in a somewhat hybrid situation where semantic analysis is possible. But it is often over domains other than that of conventional meanings (site names themselves, page name hierarchies, taxonomic, text segmenting and structure etc.), and in particular, in conjunction with document style (not in the linguistic sense) standards. Because information querying is of such importance on the Web, third party domain-oriented views of the data on the Web are provided by browsers (search engine services). Such views, forms of ‘progressive analytic semantic models’ which clothe the otherwise disparate and ‘amorphous’ data items (themselves typically disparate and amorphous) in trying to type the data, are de facto responses to the otherwise impoverished explicit semantic organization or view of data on the Web.
Language
Turning to the second problem, that of language, this concerns the languages, artificial and natural, used for accessing information on the Web and in particular for constructing filters. Browsers (and interfaces to relational data base on the Web) typically provide, in addition to queries expressed in free text, (artificial) formalized query languages. However, the great majority of the user population accessing the web has neither the training in the use of nor the inclination in the learning of one, several or a multitude of formalized query languages. Natural language as a means for expressing queries, and in the limit filters, has the immense advantage that competence in natural language is inherent to humans, which is not the case with artificial query languages. When one has no specific knowledge of the user or user population, the default language for expressing queries would seem rightly to be natural language. The evident difficulty, which we address in the paper, is the machine interpretation of requests and filter descriptions posed to the Web, but expressed in natural language.
Semantics and Language
The fact is that these two problems, semantics and languages, are inextricably linked. Furthermore, firstly, a model for semantics must handle the semantics of any domain (including itself if we want to be able to use our tools as meta tools). And secondly, we must cater for the multitude of different natural languages, and target query languages which can be different also between that of text and that of queries in remembering that meanings are for the most part language independent.
Artificial intelligence
Artificial intelligence (AI, also Machine Learning, analytics and statistics driven) is intelligence demonstrated by machines, in contrast to the natural intelligence (NI) displayed by humans and other animals. Colloquially, the term “Artificial intelligence” is applied when a machine mimics “cognitive” functions that humans associate with other human minds, such as “learning” and “problem solving”.
The roles of AI are visual perception, voice recognition, decision-making, translation, communication, task automation, the ability to learn new things, and the ability to abstract or associate with new knowledge based on already established knowledge.
Conventional and Analytic AI vs. Linguistic and Value-Driven AI
Conventional and Analytic AI
NLP does not handle semantics and has a language dependence (syntax, grammar and morphology). It relies on statistics and dictionaries words found in a similar environment of words that are “the same”. They must therefore mean the same thing more or less.
Machine learning recognises complex, multi-dimensional patterns.
No meaning is associated to any of the underlying elements.
Communications with an AI system (SIRI) are always limited by a single context.
Linguistics and Value-driven AI
Linguistics AI handles semantics embedded in a Semantic Meta Model SMM (language and data structure independent):
- What words mean (WORD<>SEME<>ATTRIBUTE<>COLUMN).
- How they relate semantically to each other in a context (dynamic semantic network).
It understands words and sentences within context.
Examples:
- All employees in a technical position must have a technical degree.
- No product should contain contaminants of type X without an explicit label on the package.
- A Human can talk using standard vocabulary in any language.
A Semantically Driven Knowledge Modelling for the Business Ecosystem
A new kind of AI is needed to enable the connection and coordination between human and machine, using semantics and knowledge modeling to standardise, enrich, and gain insights from data.
DEMS-NiXus (Data Excellence Management System – Natural Intelligence eXpanded Universe System), uses a semantic and linguistic Artificial Intelligence to translate human language business rules to machine code. DEMS is a multilingual system for the interrogation of databases in natural language and it automates data governance.
It enables reasoning over textual data and operating with textual knowledge. It is autonomous and independent, encapsulating a kind of consciousness with the current standards, regulations, and ethics with the ability to interpret knowledge’s prescriptions from all parties of the ecosystem.
Data Excellence Model (DEM): The Knowledge Assets and Semantics of Human and Machine Interactions
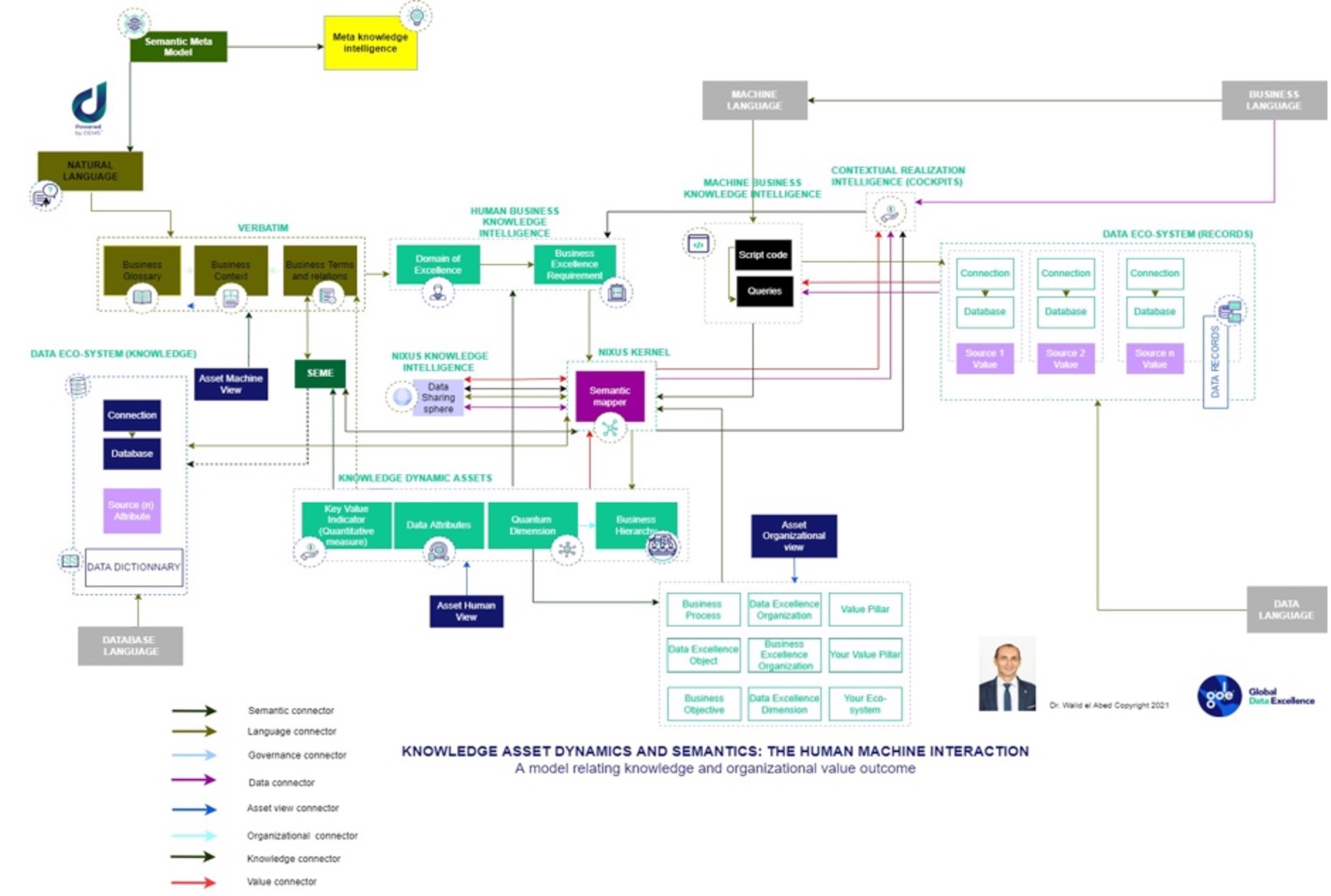
The human-machine interaction
(Click to view larger)
Conclusion
We examined how semantically-driven knowledge modelling for the business ecosystem can be at the heart of linguistics and semantics-driven AI. The combination of this technique with the Data Excellence Model (DEM) could become the kernel of a leading-edge operating system in the digital era, to permanently facilitate human and machine interactions, explore the knowledge assets dynamics and semantics, and enforce a permanent and contextual dialogue between humans and machines for ethics, values, and policies enforcement at each step of the value creation, ensuring sustainability and respect of ownership privacy policies.
The ability of such DUIOS (Digital/Data Universe Intelligent Operating System) to transform a law into rules, and human natural language into machine code for humans and machines to understand, will enable humans to define an objective, applying the required threshold, specifying the desired target, and then defining the requirements and policies in Natural Language. The knowledge is then generated from the predefined requirements. Following the knowledge generation, semantics is autogenerated, which in turn creates the program that bridges the gap between the human definitions of rules and the program that will be executed on the database. When a requirement or any organizational data is changed or modified, the system identifies all the links, the traceability, and the impact of the change, and auto-adjusts the full ecosystem to this new requirement.
Such a DUIOS caters to governments platforms, as they need to govern the economy of the country and to provide services to their citizens. It also caters to standard businesses and the financial industry, enabling them to transit from the old ERP era governing, according to processes and financial data only, to a ‘digital governed by value enterprise’ dealing with the world of never-ending complexity. This next generation operating system (DUIOS) involves all aspects of data, community, and business rules. The data aspect can include the ‘data sharing sphere,’ which enables cross-organizational data sharing. Being raised above GAFA and the traditional social networks such as LinkedIn and Facebook, the DUIOS could be at the heart of any digital/data platform (Metaverse) which enables value-driven, and purpose-driven social networks and fosters collaboration across the full ecosystem for the creation of a new society of excellence governed by value with a permanent dialogue between humans and machines.
References
El ABED, W. (2001) Semantic Meta Model And Data-Processing Kernel For The Multilingual Interrogation Of Databases In Natural Language (Theory And Application) (Published doctoral thesis). Centre De Recherche Tesnière, France.
El ABED, W., Cardey, S. and Greenfield, P. (2017) A Model for Turning Knowledge into Organisational Value Outcomes and Vice-Versa, IFKAD Conference, St. Petersburg, Russia.
El ABED, W. (2019) Innovative Solutions for Creating Sustainable Cities. Chapter 4: Data Excellence Science – The Platform To Create Future Cities. Edited by S. Albert, Cambridge Scholars Publishing.
