 In my blog last month, we looked at five aspects of relationship types, relationships in graphs, and how relationships are described in ontologies. This month we’ll look at how relationships appear in structured data.
In my blog last month, we looked at five aspects of relationship types, relationships in graphs, and how relationships are described in ontologies. This month we’ll look at how relationships appear in structured data.
Consider a typical design (Figure 1[i]) for a collection of records to keep track of data about licensed drivers in some state. This is a very “flat” design that is typical of designs destined for implementation in a SQL database.

Figure 1. Drivers Record Collection
There are relationships in this data, but it’s a bit hard to see them given the flattened record layout. Figure 2 shows exactly the same data, but with the postal address and name components separated into their own composite types. The Drivers Record Collection 2 is less complex, and we have relationship lines that we can label with readings of the relationships (lives primarily at, known by) and, if we wish, names for the types of the relationships (no relationship type names are given in this design).

Figure 2. Drivers Record Collection with Some Types Out of Line
It’s important to understand that the dashed arrows with solid arrowheads in Figure 2 do not represent traditional foreign key relationships. These arrows represent composition by aggregation, which means that the components of the referenced types, Postal Address Type and Personal Name Type, are incorporated into the Drivers Record Collection that references them. In other words, the result is effectively the Drivers Record Collection of Figure 1.
It could be that a NoSQL database designed to capture this driver information from an online form would capture it exactly as modeled, with what amounts to a single flat record per driver, with the postal address and personal name as embedded JSON objects or XML elements. Perhaps later in the life of this data, in a system of record for driver data or in an analytical warehouse, there might be an effort to identify when more than one driver has the same address. In such a case, postal addresses would be placed in their own record collection, each address given a key, and each driver record would reference a driver’s home address by its key, rather than incorporating it inline. Figure 3 shows such a design. Postal Addresses is that record collection where each unique postal address is given a key, and that key is referenced by the Drivers Analytical Record Collection.
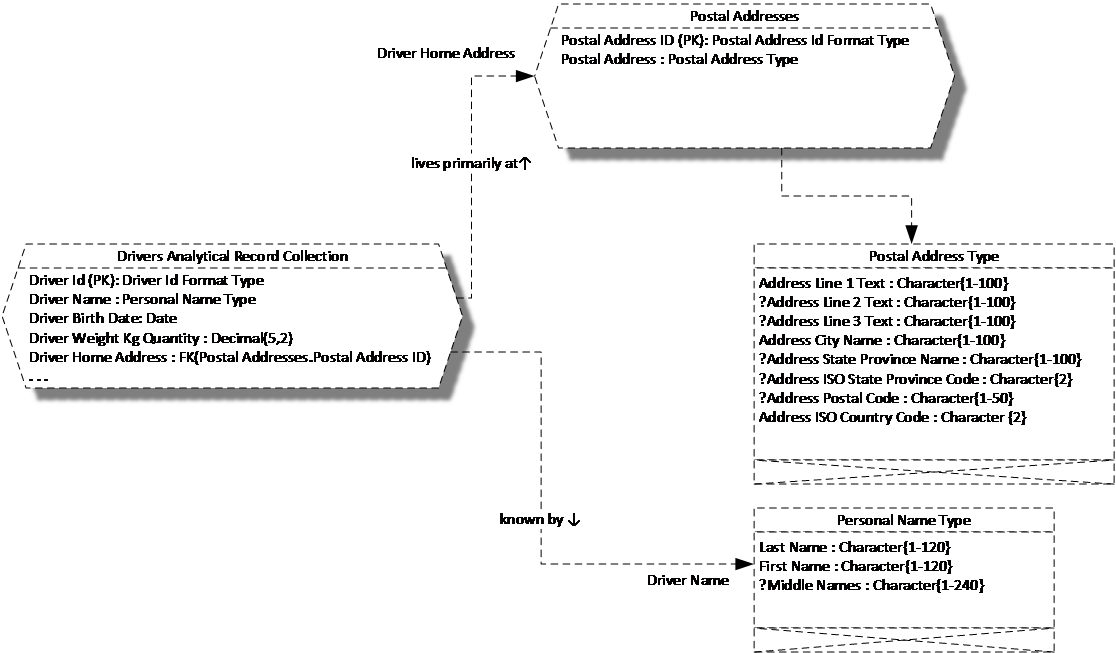
Figure 3. Drivers Analytical Record Collection
The very same Postal Address Type that is incorporated by aggregation into the Drivers Record Collection in Figure 2 is incorporated by aggregation into the Postal Addresses record collection in Figure 3. This kind of composite type re-use is very important to data quality. After all, we want to make sure that the data captured in the front-end NoSQL database is represented without loss in the back-end database due to a data type changing for no good reason. Composite type reuse is standard in almost all programming languages, and yet, for a variety of reasons, is unavailable to most of the data world. The Concept and Object Modeling Notation (COMN) makes it possible to express composite type reuse whether or not the implementation DBMS supports the concept directly. As was already seen above, aggregation means that separate data structures are not required for the reusable types in implementation.
We’ve moved from a flat data structure in Figure 1, typical of most SQL database designs, to a design that brings out embedded types and makes relationships explicit in Figure 2, to reuse of the formerly embedded types in Figure 3. So far, we have concluded that the Drivers Record Collection expresses two relationships: from a driver to a home address, and from a driver to a personal name. But there are two data attributes in the Drivers Record Collection that we haven’t talked about yet: Driver Birth Date and Driver Weight Kg Quantity. Do these data attributes participate in or indicate relationships?
Strictly speaking, no. A person’s weight is an attribute of the person, in the ordinary sense of the word attribute, which is “an inherent characteristic” (Merriam-Webster). We use a data attribute to store a value indicating a person’s weight, but attributes—inherent characteristics—are not related to entities; they are just an inseparable part of them. Other attributes of persons include height and native language. This is confusing for two reasons. First, we often abbreviate the term “data attribute” as simply “attribute”, and lose the distinction between an inherent characteristic of something and data measuring that inherent characteristic. Second, although weight and other inherent characteristics are attributes of a person, data about a person is held in variables called data attributes which are not inherent characteristics of records but are separable components of them. The data attributes of a driver record are incorporated into that record through aggregation. They could be separated, and in fact often are through such operations as projection of a subset of the data attributes, for example by a view or an extract that makes only selected data attributes available. In contrast, you cannot separate a person from their weight (though many of us would like to do so! J). So, real-world attributes are inherent characteristics of entities, but data attributes are components of records.
Unlike weight, a birth date is not an inherent characteristic of a person. A birth date is data that is part of a fact about an event in a person’s life—the event of being born. Events only exist to the extent that we remember them and/or record data about them. We can then talk of the relationship of event data to entities. Whether we can say that events are related to entities per se is a philosophical question I’m not ready to tackle.
These fine distinctions between attributes as inherent characteristics and data attributes as components of records seem somewhat philosophical but have great significance when modeling metadata. A metadata model is already a hall of mirrors with similar structures reflecting at many levels; confusing attributes and data attributes makes metadata models even more difficult. So, if you’re just focused on data, you have little to worry about – but if you’re entering the world of metadata, prepare yourself and pay attention to the difference!
This monthly blog talks about data architecture and data modeling topics, focusing especially, though not exclusively, on the non-traditional modeling needs of NoSQL databases. The modeling notation I use is the Concept and Object Modeling Notation, or COMN (pronounced “common”), and is fully described in my book, NoSQL and SQL Data Modeling (Technics Publications, 2016). See http://www.tewdur.com/ for more details.
Copyright © 2016, Ted Hills
[i] Models in this blog use the Concept and Object Modeling Notation (COMN), more fully described at http://www.tewdur.com/.
