 In this paper I wrote with Sylviane Cardey and Peter Greenfield we examine how a semantics based technique, MMS (Méta Modèle Sémantique) [ELA 99, ELA 00] employing a query history mechanism (principally for anaphora processing) devised for natural language queries to formally organized data (the example being relational databases) might be extended to the filtering of information on the Web.
In this paper I wrote with Sylviane Cardey and Peter Greenfield we examine how a semantics based technique, MMS (Méta Modèle Sémantique) [ELA 99, ELA 00] employing a query history mechanism (principally for anaphora processing) devised for natural language queries to formally organized data (the example being relational databases) might be extended to the filtering of information on the Web.
Our interest is larger than content filtering (which might also be termed access filtering – “Internet content filtering involves the limitation of the material that may be seen on a particular computer screen at a particular time” [WIL 01]), and concerns filtering Web data in the general sense. We discuss the expected benefits and difficulties of this essentially pragmatic approach, which on the one hand is dependent on the existence of third party browsers coupled with domain indicators such as taxonomies and the use of labels following the PICS standard (Platform for Internet Content Selection developed by the World Wide Web Consortium), but on the other hand, in its concrete form, uses de facto standard tools and techniques of relational data base management systems.
Semantics and Language
Filtering information extracted from the Web is problematic for various reasons, and in this paper we will be principally concerned with two of these – the first being semantics, and the second one language.
Semantics
In general, there is an absence of explicit semantic modelling of data on the Web. We can contrast this with, for example, the explicit semantic modelling of data in a relational database, modelling which is done before the database is constructed, and which leads to a number of benefits. One benefit is that of functionality; there is the presence of a formal calculus (SQL). Another benefit is that in terms of read access performance there is the possibility of indexing based on the model (in practice, the database’s schema) under reading rather than updating. Finally, knowledge and experience of relational data base technology is widespread.
Traditionally, for (static) ostensibly amorphous textual data in which we can say that there is an explicit absence of semantic modelling, recourse has typically been made to analytical means such as concordance techniques, which for performance needs require indexing on variously ‘words’, ‘compounds’, ‘contexts’ (often in the form of regular expressions), and in the limit linguistic elements ‑ see for example [BIS 99]. In other words, a model is certainly constructed, but this may be before, contemporaneous, or after the presence of the raw data. Put briefly, explicit semantic modelling is for creating an artifact (such as a data base responding to some need), analytic semantic modelling involves seeing if some set of data already in existence (some Web content) is a theorem of a previously proposed theory (model). In the case of the Web, due to the page structure and also due to the use of mark-up languages and labelling following the PICS standard, in reality the data is not wholly amorphous and we are in a somewhat hybrid situation, where semantic analysis is possible but often over domains other than that of conventional meanings (site names themselves, page name hierarchies, taxonomic, text segmenting and structure, etc.), and in particular, in conjunction with document style (not in the linguistic sense) standards (for an example of the interpreting of mark‑up data see [FIT 99]). Because information querying is of such importance on the Web, third party domain oriented views of the data on the Web are provided by browsers (search engine services). Such views, forms of ‘progressive analytic semantic models,’ which clothe the otherwise disparate and ‘amorphous’ data items (themselves typically disparate and amorphous) in trying to type the data are de facto responses to the otherwise impoverished explicit semantic organization or view of data on the Web.
Language
Turning to the second problem, that of language, this concerns the languages, artificial and natural, used for accessing information on the Web and in particular for constructing filters. Browsers (and interfaces to relational data bases on the Web) typically provide, in addition to queries expressed in free text, (artificial) formalized query languages. However, the great majority of the user population accessing the web has neither the training in the use of nor the inclination in the learning of one, several, or a multitude of formalized query languages. Natural language as a means for expressing queries and in the limit filters has the immense advantage that competence in natural language is inherent to humans which is not the case with artificial query languages. When one has no specific knowledge of the user or user population, the default language for expressing queries would seem rightly to be natural language. The evident difficulty, which we address in the paper, is the machine interpretation of requests and filter descriptions posed to the Web, but expressed in natural language.
Semantics and Language
The fact is that these two problems, semantics and languages, are inextricably linked. Firstly, a model for semantics must handle the semantics of any domain (including itself if we want quite reasonably to be able to use our tools as meta tools), and secondly, we must cater for the multitude of different natural languages and target query languages which can be different also between that of text and that of queries, in remembering that meanings are for the most part language independent.
Web Data Access
Of the organizations, organization levels, and content types of data subjected to queries for information, we shall restrict ourselves in this paper to two, these being data organized from the outset according to some formal model with an associated formal semantics by means of some calculus (and in particular the relational model with SQL), and data as it is organized on the Web (at the ‘lowest level’ in addressed pages of marked up ‘data’). However, on inspection, one finds that in reality both approaches use the same abstract architecture, this being based on a canonical query pivot language (such as SQL for relational databases, for free text amongst other regular expressions and GCCA [BIS 99], and for natural language queries to relational database variously the use of the linguistic operators of Z.S. Harris [HAR 76], [BOU 99] and MMS – semantic modelling [ELA 01], this last being the basis of this article).
A Semantics Based Approach
The theoretical basis for MMS is that of the semantic modelling of queries. Any query of a data source, independent of the language in which the query is expressed (natural or formal), is considered as following certain semantic rules that are essential for its understanding [ELA 00]. A semantic meta model, MMS, enables the construction of meta bases which allow on the one hand the classifying of keywords appearing in queries, and on the other hand the creation of links that can occur between the keywords. Using this approach, the influence of a specific natural language is prima facie slight and indeed is contained in a parametric fashion (as data within the meta base).
In essence, the theory is based on the fact that if one is placed within a precise context then the information pertinent to the context can be represented by an unambiguous explicit semantic structure. In order that contexts be always unambiguous, the meta model requires that the principal theme of a given meta base is the domain. A domain corresponds to a relational database, its content having to conform to the database’s schema (the table descriptions, the joins, etc.).
This classification by domain is necessary because the meaning of key words can vary according to the domain. In contrast to classical relational data base modelling which leads to a data base schema as an explicit artefact with explicit domains, the case of the Web would involve domains of variously taxonomies or PICS labels.
The Semantic Meta Model and Meta Base
The semantic meta model serves as the model of the meta base which contains a description of the information source under investigation. The semantic meta model together with the associated kernel, due to Walid EL ABED [ELA 00], enables the modelling of the semantic structure of an arbitrary relational database; this involves the classification of the various domains within the information source together with a classification of the various keywords that can appear in a query to be expressed in a natural language. A keyword can be a simple keyword or a compound. This keyword classification distinguishes between generic keywords and specific keywords.
Generic keywords are domain independent, but have roles in the formulation of the semantic description of a given query (and thus, once established for a given natural language can be re‑used for other information sources). Generic keywords can be either accessory (not required in calculating the meaning but aiding in determining the natural language used), conditional (corresponding to restrictions which contribute to “where” conditions in SQL), or numeric.
Specific keywords are domain specific, and are either classifying keywords or informational keywords. Classifying keywords are those associated with concepts within a given domain; a classifying keyword corresponds to a table in a relational data base of some domain. Information keywords are those associated with a concept and each corresponds to an attribute of a table.
For example, given that we have a domain named “museum” for which there exists a meta model and we pose the query:
Give me the tariffs for the museums in Besançon
And the analyzer within the kernel determines the classification of the key words according to the meta model is:
- accessory: Give, me, the, for, in
- informational: tariffs
- classifying: museums
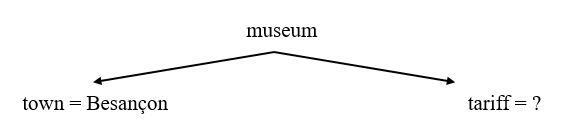
This leaves “Besançon”. “Besançon” is an occurrence of the informational word “town” which is an attribute of the classifying word “museums”. “town” is not present in the query; a task of the analyzer is justly the ‘restitution’ of any information missing in the query that is necessary for processing the query. The analyzer can do this because the meta model contains meta semantic networks; for example:
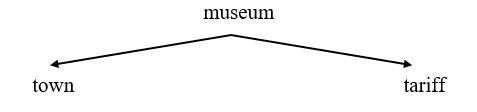
The analyzer ‘reconstructs’ the query, deducing missing information. In the example, there is an informational word (“town”) missing from the query, but it is implied by a value (“Besançon”) in the query. Contrary to the conventional approach in natural language query systems in which attribute values are also present as static pairs in the ‘knowledge representations’ of the domains (equivalent to our meta model), the association is done dynamically by the analyzer. In consequence, our meta model is not burdened with copies of data present in the target data base and is thus unaffected by changes in the data base’s contents. The reconstituted query corresponds to the following semantic network:
Its implementation being as follows:
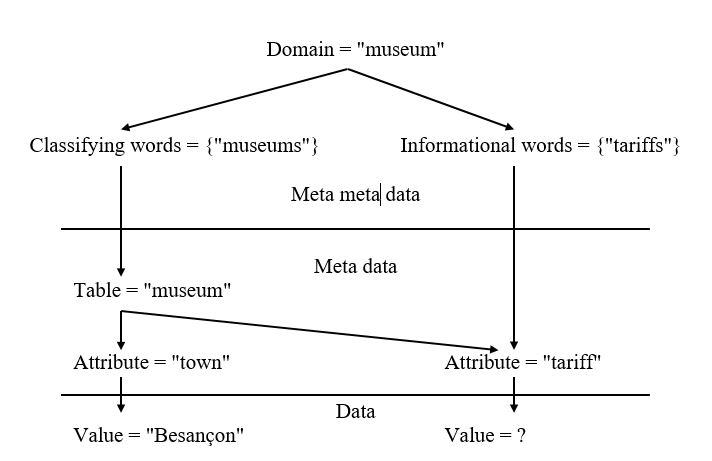
Attributes with un-instantiated values correspond to SQL SELECT arguments whilst attributes with instantiated values appear in the WHERE arguments. Classifying words leads to table names which appear as FROM arguments. The analyzer constructs the following SQL query which has the same meaning as the natural language query:
SELECT museum.tariff FROM museum WHERE museum.town = “Besançon”
The domain name and the table name are the same in this simple example where the domain contains just one table. The meta model can support domains where the classifying words are associated with multiple tables; a good example is the meta model of the domain used to store meta models of domains and in which there are multiple tables. By this means, not only can natural language queries be posed to meta models of various domains, but such queries can also be posed to the meta model of the system’s data base.
Whilst we have addressed the problem of just contextual semantic ambiguity, other ambiguities due to the inherent imprecision of natural language can be present. For queries to relational databases, these come especially from evaluation adjectives and from adverbs modifying these adjectives; however, encouraging results have been obtained using fuzzy logic [CHA 99].
Anaphora Processing
The natural language interface to relational data bases provides a degree of anaphora processing. Consider the following sequence of queries/replies:
Query 1: “What is the citadel’s address?”
Reply: Rue de la Résistance
Query 2: “Give me its telephone number.”
Reply: 03.81.82.16.22
Query 3: “And the astronomical clock’s”
Reply: 03.81.81.76.76
To enable anaphora processing, a memo technique is used in which the determining of a concept that is missing in a query is based on concepts already used in preceding queries. Though practical but certainly not 100%, it is far from treating all the semantic problems due to anaphora.
Multilingual Queries
In the system upon which this proposal is based, the technique for translating natural language requests in the context of a request history mechanism to requests expressed in a canonical query pivot language (SQL) is semantically based, and this to such an extent that which specific natural language used is in fact a minor issue; indeed, a user can use different natural languages to compose requests (even within a request).
Accessing the Web
For the MMS system to be able to access the Web, the issue is, as we have observed, that the Web hosts very disparate data organizations, as well as multiple query languages (browser and other). However, the notion and reality of the MMS linguistic meta model remains. Thus a possible approach is one, to devise relational models of the specific Web domains to be queried; and two, to devise SQL interpreters appropriate for the corresponding Web query languages/data organizations, and with the appropriate operational semantics.
To enable natural language filter programming, the idea is briefly that filters are programmed in natural language by means of specific sequences of queries, these making free use of anaphora where needed. Thus we propose interactive ‘investigative’ or ‘exploratory’ natural language programming of filters.
Conclusion
In our approach, at the abstract level, the Web query languages expressed against information in given Web formats are peers with queries expressed in the users’ natural languages. Of course, there does need to be a translation mechanism between the pivot language, SQL, and each of the ‘languages’ used to express queries against Web data (as used in browsers). However, what marks our proposal is that the natural language queries and filters, and the Web data, have common semantics realized by MMS.
The approach we have described is essentially pragmatic. A strength (or it could be equally said a strategic weakness) of the approach is the dependency on the existence and the continuing availability of third party browsers, domain taxonomies, labels, and the like. Our approach uses these facilities as an available partial solution to the overall semantics problem. It permits us to envisage a hybrid solution where we can at least use the standard tools and techniques of relational data base management systems, and furthermore by using meta base techniques, our query interface can manipulate the/its meta bases. The MMS approach leads to systems that are light in resources; copying of base data in the meta bases is deliberately avoided. Abstraction of the interface between our query interface and different browsers is clearly something that also needs to be done as well as work on what operational semantics is appropriate in what situation – what is the data to be filtered?
References
[BIS 99] BISKRI, I., DELISLE, S., “Les grammaires catégorielles pour le développement d’applications multilingues destinées au Web”, BULAG N° 24, 1999, p. 39‑57.
[BOU 99] BOUCHOU, B., MAUREL, D., “Natural Language Database Query System”, NLDB’99, Klagenfurt, Austria, June 1999.
[CHA 99] CHAO, H‑L., CHEN, C‑H., CARDEY, S., “Traitement automatique de la sémantique floue dans l’interrogation de bases de données en langage naturel”, BULAG N° 24, 1999, p. 187‑208.
[ELA 00] EL ABED, W., Méta modèle sémantique et noyau informatique pour l’interrogation multilingue des bases de données en langue naturelle (théorie et application), thèse, Université de Franche‑Comté, Besançon, France, décembre 2000.
[ELA 99] EL ABED, W., “Métabase pour interrogation en langue naturelle des infocentres ; proposition de modélisation”, BULAG N° 24, 1999, p. 59‑80.
[HAR 76] HARRIS, Z.S., Notes du cours de syntaxe, Paris, Le Seuil, 1976.
[WIL 01] WILKINSON, E., “Filtering”, The Computer Bulletin, March 2001, p. 32.
