
Introduction
We are living in the age of a data revolution, and more corporations are realizing that to lead—or in some cases, to survive—they need to harness their data wealth effectively. The data warehouse, due to its unique proposition as the integrated enterprise repository of data, is playing an even more important role in this situation. There are two prominent architecture styles practiced today to build a data warehouse: the Inmon architecture and the Kimball architecture.
This paper attempts to compare and contrast the pros and cons of each architecture style and to recommend which style to pursue based on certain factors.
[Publisher’s Note: From time-to-time, TDAN.com republishes content that was and remains popular in the publication. This feature from Sakthi Rangarajan is one of the most read pieces of content of all-time on TDAN.com.]
Background
In terms of how to architect the data warehouse, there are two distinctive schools of thought: the Inmon method and Kimball method. They both view the data warehouse as the central data repository for the enterprise, primarily serve enterprise reporting needs, and they both use ETL to load the data warehouse. The key distinction is how the data structures are modeled, loaded, and stored in the data warehouse. This difference in the architecture impacts the initial delivery time of the data warehouse and the ability to accommodate future changes in the ETL design. When a data architect is asked to design and implement a data warehouse from the ground up, what architecture style should he or she choose to build the data warehouse? What criteria can help an architect choose between the Inmon or the Kimball architecture?
The Inmon Approach
The Inmon approach to building a data warehouse begins with the corporate data model. This model identifies the key subject areas, and most importantly, the key entities the business operates with and cares about, like customer, product, vendor, etc. From this model, a detailed logical model is created for each major entity. For example, a logical model will be built for Customer with all the details related to that entity. There could be ten different entities under Customer. All the details including business keys, attributes, dependencies, participation, and relationships will be captured in the detailed logical model. The key point here is that the entity structure is built in normalized form. Data redundancy is avoided as much as possible. This leads to clear identification of business concepts and avoids data update anomalies. The next step is building the physical model. The physical implementation of the data warehouse is also normalized. This is what Inmon calls as a ‘data warehouse,’ and here is where the single version of truth for the enterprise is managed. This normalized model makes loading the data less complex, but using this structure for querying is hard as it involves many tables and joins. So, Inmon suggests building data marts specific for departments. The data marts will be designed specifically for Finance, Sales, etc., and the data marts can have de-normalized data to help with reporting (Breslin, 2004). Any data that comes into the data warehouse is integrated, and the data warehouse is the only source of data for the different data marts. This ensures that the integrity and consistency of data is kept intact across the organization. Figure 1.2 shows the typical architecture of an Inmon data warehouse.
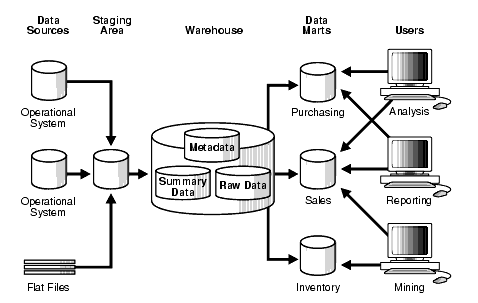
Click to view larger.
The key advantages of the Inmon approach are:
- The data warehouse truly serves as the single source of truth for the enterprise, as it is the only source for the data marts and all the data in the data warehouse is integrated.
- Data update anomalies are avoided because of very low redundancy. This makes ETL process easier and less prone to failure.
- The business processes can be understood easily, as the logical model represents the detailed business entities.
- Very flexible – As the business requirements change or source data changes, it is easy to update the data warehouse as one thing is in only one place.
- Can handle varied reporting needs across the enterprise.
Here are some of the disadvantages of Inmon method:
- The model and implementation can become complex over time as it involves more tables and joins.
- Need resources who are experts in data modeling and of the business itself. These type of resources can be hard to find and are often expensive.
- The initial set-up and delivery will take more time, and management needs to be aware of this.
- More ETL work is needed as the data marts are built from the data warehouse.
- A fairly large team of specialists need to be around to successfully manage the environment (Breslin, 2004).
The Kimball Approach
The Kimball approach to building the data warehouse starts with identifying the key business processes and the key business questions that the data warehouse needs to answer. The key sources (operational systems) of data for the data warehouse are analyzed and documented. ETL software is used to bring data from all the different sources and load into a staging area. From here, data is loaded into a dimensional model. Here the comes the key difference: the model proposed by Kimball for data warehousing—the dimensional model—is not normalized. The fundamental concept of dimensional modeling is the star schema. In the star schema, there is typically a fact table surrounded by many dimensions. The fact table has all the measures that are relevant to the subject area, and it also has the foreign keys from the different dimensions that surround the fact. The dimensions are denormalized completely so that the user can drill up and drill down without joining to another table. Multiple star schemas will be built to satisfy different reporting requirements. So, how is integration achieved in the dimensional model? Here, Kimball proposes the concept of ‘conformed dimensions’. The key dimensions, like customer and product, that are shared across the different facts will be built once and be used by all the facts (Kimball et al. 2013). This ensures that one thing or concept is used the same way across the facts. Another key artifact of the Kimball model is the ‘enterprise bus matrix’. This is the document where the different facts are listed vertically and the conformed dimensions are listed horizontally. Where ever the dimensions play a foreign key role in the fact, it is marked in the document. This serves as an anchoring document showing how the star schemas are built and what is left to build in the data warehouse. Figure 1.3 shows a typical Kimball data warehouse architecture.
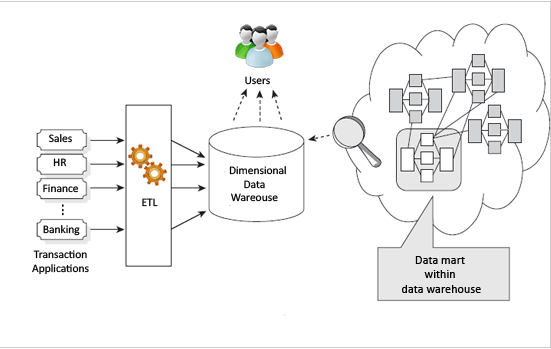
Click to view larger.
Here are some of the advantages of the Kimball method:
- Quick to set-up and build, and the first phase of the data warehousing project will be delivered quickly.
- The star schema can be easily understood by the business users and is easy to use for reporting. Most BI tools work well with star schema.
- The foot print of the data warehousing environment is small;it occupies less space in the database and it makes the management of the system fairly easier.
- The performance of the star schema model is very good. The database engine will perform a ‘star join’ where a Cartesian product will be created using all of the dimension values and the fact table will be queried finally for the selective rows. This is known to be a very effective database operation.
- A small team of developers and architects is enough to keep the data warehouse performing effectively (Breslin, 2004).
- Works really well for department-wise metrics and KPI tracking, as the data marts are geared towards department-wise or business process-wise reporting.
- Drill-across, where a BI tool goes across multiple star schemas to generate a report can be successfully accomplished using conformed dimensions.
Here are some of the disadvantages of the Kimball method:
- The essence of the ‘one source of truth’ is lost, as data is not fully integrated before serving reporting needs.
- Redundant data can cause data update anomalies over time.
- Adding columns to the fact table can cause performance issues. This is because the fact tables are designed to be very deep. If new columns are to be added, the size of the fact table becomes much larger and will not perform well. This makes the dimensional model hard to change as the business requirements change.
- Cannot handle all the enterprise reporting needs because the model is oriented towards business processes rather than the enterprise as a whole.
- Integration of legacy data into the data warehouse can be a complex process.
Deciding Factors
Now that we have seen the pros and cons of the Kimball and Inmon approaches, a question arises. Which approach should be used when? This question is faced by data warehouse architects every time they start building a data warehouse. Here are the deciding factors that can help an architect choose between the two:
- Reporting Requirements – If the reporting requirements are strategic and enterprise-wide and integrated reporting is needed, then Inmon works best. If the reporting requirements are tactical and business process/team oriented, then Kimball works best.
- Project Urgency – If the organization has enough time to wait for the first delivery of the data warehouse (say 4 to 9 months), then Inmon approach can be followed. If there is very little time for the data warehouse to be up and running (say, 2 to 3 months) then the Kimball approach is best (Breslin, 2004).
- Future Staffing Plan – If the company can afford to have a large sized team of specialists to maintain the data warehouse, then the Inmon method can be pursued. If the future plan for the team is to be thin, then Kimball is more suited.
- Frequency of Changes – If the reporting requirements are expected to change more rapidly and the source systems are known to be volatile, then the Inmon approach works better, as it is more flexible. If the requirements and source systems are relatively stable, the Kimball method can be used.
- Organization Culture – If the sponsors of the data warehouse and the managers of the firm understand the value proposition of the data warehouse and are willing to accept long-lasting value from the data warehouse investment, the Inmon approach is better. If the sponsors do not care about the concepts but want a solution to get better at reporting, then the Kimball approach is enough.
Conclusion
It has been proven that both the Inmon and Kimball approach work for successfully delivering data warehouses. There are even organizations where a combination of both (‘hybrid model’) has been implemented. In a hybrid model, the data warehouse is built using the Inmon model, and on top of the integrated data warehouse, the business process oriented data marts are built using the star schema for reporting. We cannot generalize and say that one approach is better than the other; they both have their advantages and disadvantages, and they both work fine in different scenarios. The architect has to select an approach for the data warehouse depending on the different factors; a few key ones were identified in this paper. Finally, for any approach to be successful, it needs to be carefully thought out, discussed in detail, and designed to satisfy the organization’s BI reporting needs and should also gel with the culture of the organization.
References
Breslin, Mary. 2004. “Data Warehousing Battle of the Giants: Comparing the Basics of the Kimball and Inmon Models” Business Intelligence Journal, Winter 2004. Accessed May 22, 2016.
Inmon, W. H. Building the Data Warehouse, Fourth Edition. John Wiley & Sons., 2005.
Marakas, George M. Modern Data Warehousing, Mining, And Visualization. Prentice Hall, 2003.
Inmon, W. H. 2010. “A TALE OF TWO ARCHITECTURES” InmonCif.com. Accessed May 23, 2016.
Kimball, Ralph, and Margy Ross. The Data Warehouse Toolkit: The Definitive Guide to Dimensional Modeling, Third Edition. John Wiley & Sons. 2013. Books24x7.
Stanford. 2003. “Data Warehousing Concepts” Stanford.edu. Accessed May 26, 2016.https://web.stanford.edu/dept/itss/docs/oracle/10g/server.101/b10736/concept.htm#i1006297
Zentut. 2016. “Ralph Kimball Data Warehouse Architecture” Zentut.com. Accessed May 25, 2016. http://www.zentut.com/data-warehouse/ralph-kimball-data-warehouse-architecture/

{kind=link}