“Technical debt” refers to the implied cost of future refactoring or rework to improve the quality of an asset to make it easy to understand, work with, maintain, and extend. The concept of technical debt was first proposed in the early 1990s by Ward Cunningham to describe the impact of poor-quality code on your overall software development efforts. Since then, people have extended the metaphor to other types of debt, including architecture technical debt, documentation technical debt, and data technical debt.
Data technical debt (DTD) refers to any technical debt associated with the design of legacy data sources or with the data contained within those data sources. There are several categories of DTD that your data sources may exhibit:
- Structural. Quality issues with the design of a table, column or view.
- Data quality. Quality issues with the consistency or usage of data values.
- Referential integrity. Quality issues with whether a referenced row exists within another table and that a row which is no longer needed is (soft) deleted appropriately.
- Architectural. Quality issues with how external programs interact with a data source.
- Documentation. Quality issues with any supporting documents, including models.
- Method/functional. Quality issues with execution aspects within a data source, such as stored procedures, stored functions, and triggers.
Got Data Technical Debt?
When I was with Project Management Institute (PMI), I ran two studies that explored technical debt, the 2022 Data Quality Survey and the 2022 Technical Debt Survey, both of which I refer to in this article. Figure 1 summarizes the results from a question in the 2022 Data Quality Survey that explored the general state of production data quality. The question explored people’s opinion of the quality of the data that they had most recently accessed from a production data source. As you can see, only 42% felt that the data was of high or very high quality. 19% of respondents indicated that the data quality was low, a clear sign that data technical debt is a problem with those data sources, although nobody indicated very low.

How Did We Get Here?
There are several reasons why organizations suffer from data technical debt. Often, it is accidental. The teams that build data sources either don’t have the skills to develop a high-quality data source or they aren’t given the time and money to do so. It is also common to see a well-designed data source to be extended inappropriately, or to be used inappropriately, thereby reducing overall quality. In some cases, technical debt is taken on intentionally, with management understanding the impact of their decision and willingly choose to live with the consequences to gain other benefits (usually time to market). Martin Fowler wrote about this eloquently almost two decades ago with his technical debt quadrant, a concept that I extended for a data technical debt quadrant.
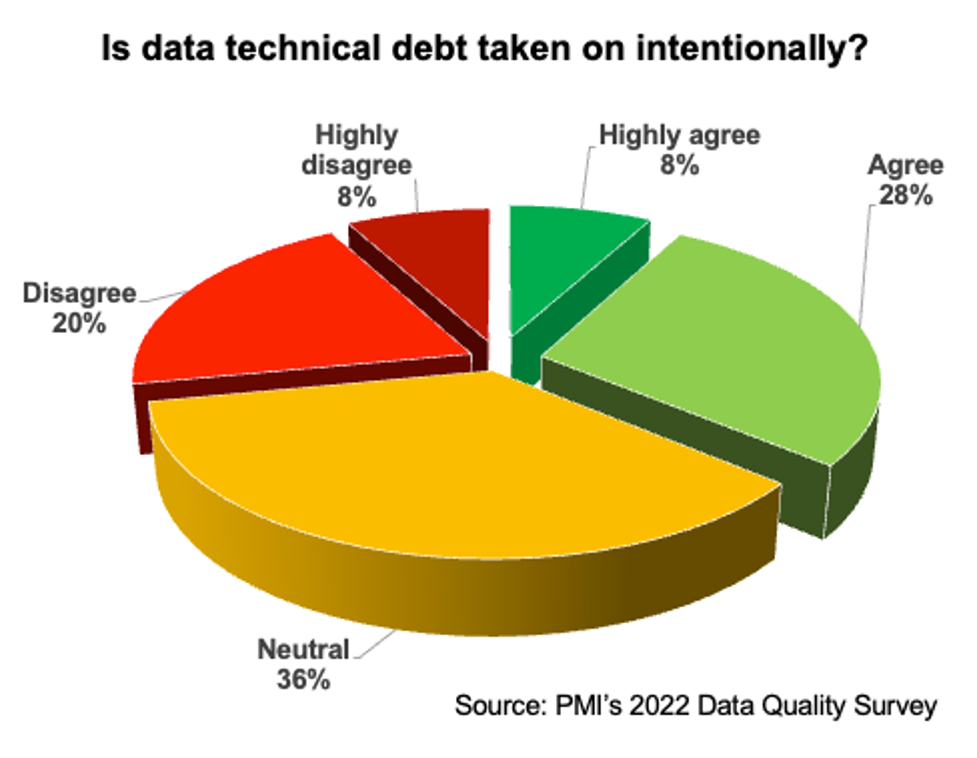
The 2022 Data Quality Survey explored this issue directly, asking people whether they believed their organization takes on data technical debt intentionally. The results are summarized in Figure 2, and as you can see, it isn’t a pretty picture. The fact that 28% of respondents indicated that they believed that data technical debt was being taken on unintentionally, and that an additional 36% weren’t sure, indicates to me that many organizations need to do better when it comes to increasing their DTD.
What Gets Measured Gets Improved
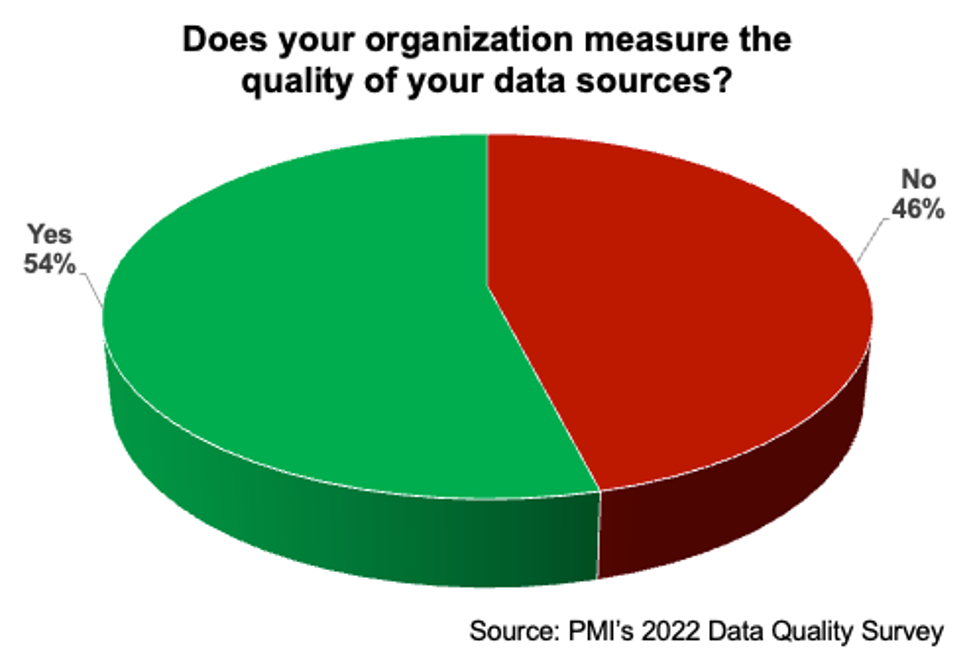
A common refrain in the metrics community is that if you want to improve something then you need to measure it. Furthermore, you need to measure the right thing In the 2022 Data Quality Survey, we explored whether organizations measured data quality, finding that only a bit more than half were doing so. We did not explore what they were measuring, so cannot attest to the effectiveness of their measurement strategies.
These results were similar to those of PMI’s 2022 Technical Debt Survey which found that 79% of organizations measured code technical debt, 56% measured architecture technical debt (including data architecture debt), and only 40% measured data/database technical debt. Organizations must consistently and coherently measure their data technical debt so as to be in a position to understand it, to avoid it whenever they can, and to fix it when then run into problems. Without any metrics in place, organizations are effectively flying blind.
Are We Serious About Fixing Data Technical Debt (DTD)?
In many cases, no. In the 2022 Data Quality Survey, we asked people what their organization was doing to address DTD, if anything. Figure 4 summarizes the results of that question. On the positive side, some respondents, 19%, indicated that they had little or no DTD. Another 19% said that they were taking a database refactoring approach, which is a proven and more important safe way to evolve existing production databases over time. Another 5% indicated that they intend to rewrite and deploy all of their systems at once, which to be fair is a viable strategy for small organizations with only a handful of legacy systems (good luck otherwise).
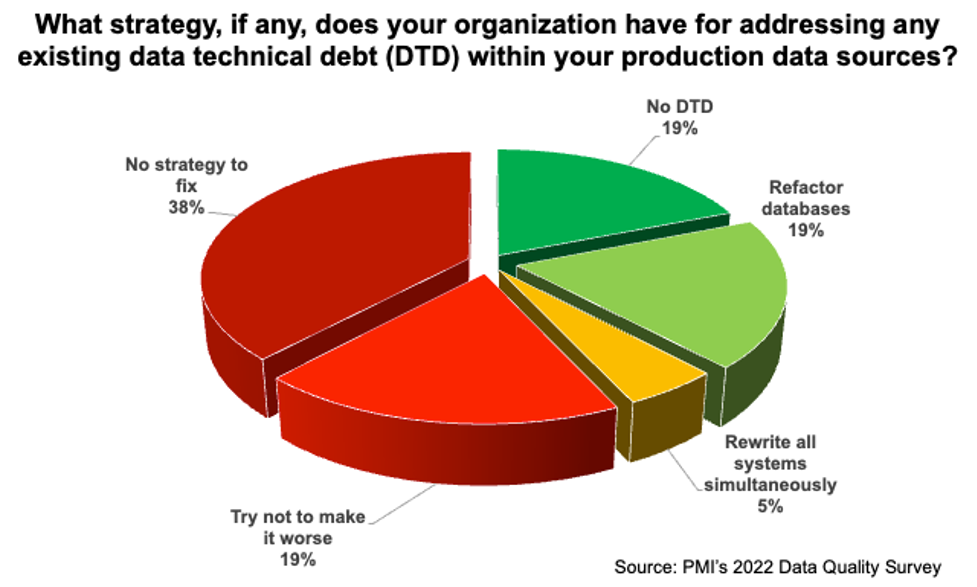
But, there’s a lot of red in Figure 4. Many respondents, 38%, indicated that their organizations had no strategy to address DTD at all. Furthermore, 19% of respondents indicated that they were trying to not make things worse, which is effectively no strategy either. Due to software and data entropy the situation is guaranteed to get worse over time if you do nothing— the evolving needs of your stakeholders alone will invalidate some of your data and the business logic around it. In short, it looks to me that close to 60% of organizations have given up addressing their data quality problems.
Is Management to Blame?
I suspect that the answer is that they mostly are. Figure 5, summarized from PMI’s 2022 Technical Debt Survey, explores management priorities in organizations. As you can see, only 3% indicated that addressing technical debt was their first priority compared with delivering on time, delivering on budget, or adding new functionality into existing systems. The survey asked people to rank these four priorities within their organizations, also finding that addressing technical debt was the least important priority for 61% of respondents.

The challenge that we face is that the desire to be on time, on budget, or to add new functionality tends to motivate teams to short change quality. In the IT project management realm, we’ve known for decades about a concept called the iron triangle— at least one of scope, schedule, and cost must be allowed to vary otherwise quality suffers. It’s clear to me that many organizations are inadvertently taking on data technical debt in their chase questionable management goals.
Parting Thoughts
I want to leave you with three thoughts. First, data technical debt (DTD) isn’t just about data quality, it’s about quality issues surrounding data work in general. DTD is an underappreciated part, but only a part, of technical debt. For DTD to be addressed effectively it must be a component of our organization’s overall technical debt strategy, and for that to happen data quality practitioners need a seat at the table.
Second, to be relevant voices at that table, data quality practitioners need to embrace new ways of working. Many of the traditional data quality strategies of yesteryear, particularly those requiring significant up-front work or significant overhead, are non-starters for today’s agile enterprises. The concrete quality practices of the agile database techniques stack show how to apply the proven, and common, agile/dev-ops development practices to database development.
Third, we need more data about what is going on out there. We need more studies about the current state of data quality, data quality practices, and the effectiveness of those practices. We also need to explore management understanding of, and strategies around, data quality and related issues. I’m a firm believer in making data-informed decisions, a philosophy that we need to apply within the data community ourselves, and to do that we need to regularly collect pertinent data.
