
We just finished a conversation with a client who was justifiably proud of having centralized what had previously been a very decentralized business function (in this case, it was HR, but it could have been any of a number of functions). They had seemingly achieved many of the benefits of becoming data-centric through decentralization: all their data in one place, a single schema (data model) to describe the data, and dozens of decommissioned legacy systems.
We decided to explore whether this was data-centric and the desirable endgame for all their business functions.
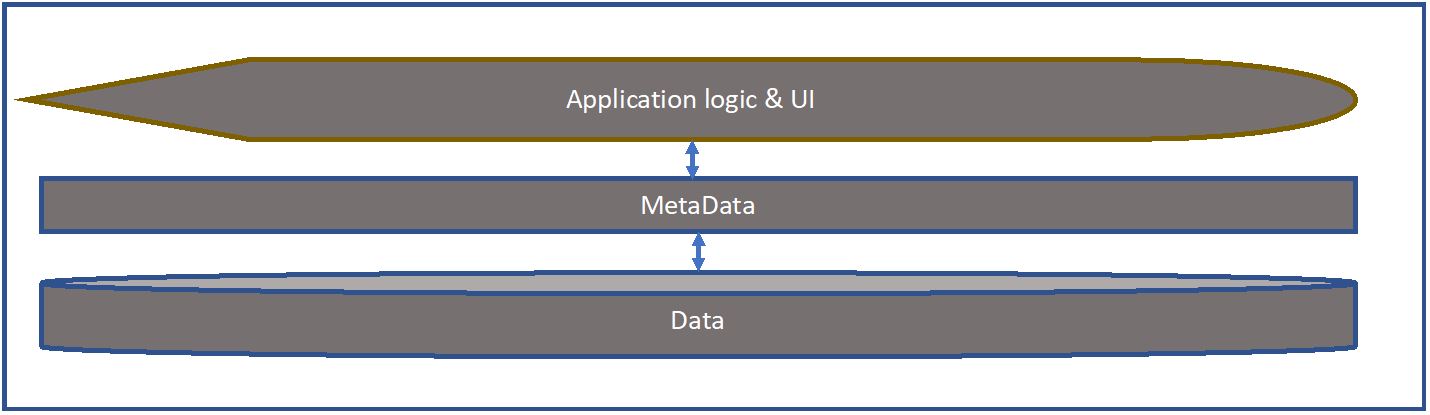
A quick review. This is what a typical application looks like:

The metadata is the key. The application, the business logic and the UI are coded to the metadata (Schema), and the data is accessed through and understood by the metadata. What happens in every large enterprise (and most small ones) is that different departments or divisions implement their own applications.
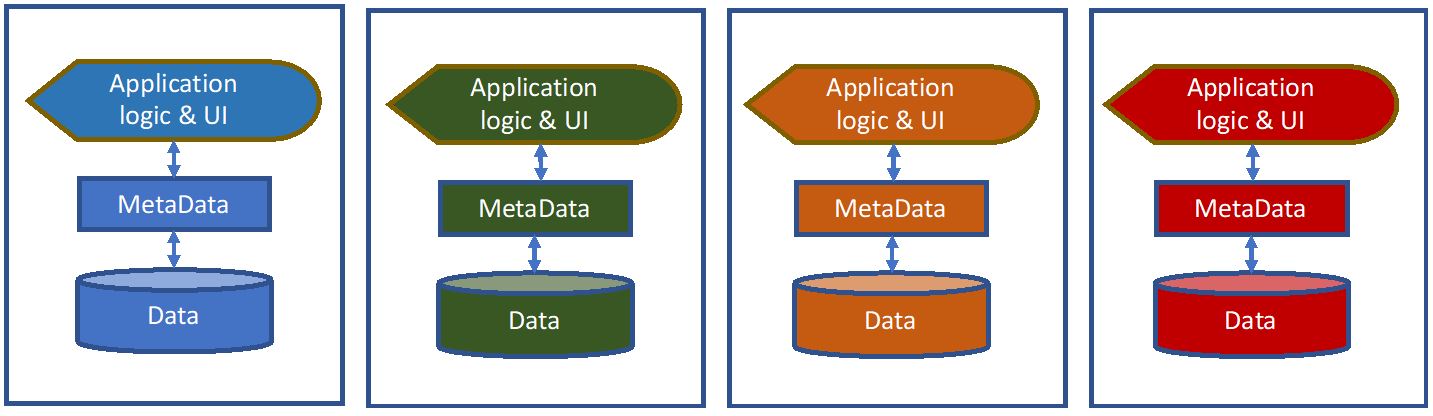
Many of the applications were purchased, and today, some are SaaS (Software as a Service) or built in-house. What they all fail to share is a common schema. The metadata is arbitrarily different and, as such, the code base on top of the metadata is different, so there is no possibility of sharing between departments. Systems integrators try to work out what the data means and piece it together behind the scenes. This is where silos come from. Most large firms don’t have just four silos, they have thousands of them.
One response to this is “centralization.” If you discover that you have implemented, let’s say, dozens of HR systems, you may think it’s time to replace them with one single centralized HR system. And you might think this will make you Data-Centric. And you would be, at least, partially right.
Recall one of the litmus tests for Data-Centricity:

Let’s take a deeper look at the centralization example.
Centralization replaces a lot of siloed systems with one centralized one. This achieves several things. It gets all the data in one place, which makes querying easier. All the data conforms to the same schema (and single shared model). Typically, if this is done with traditional technology, this is not a simple model, nor is it extensible or federate-able, though there is some progress.
The downside is that everyone now must use the same UI and conform to the same model, and that’s the tradeoff.
The tradeoff works pretty well for business domains where the functional variety from division to division is slight, or where the benefit to integration exceeds the loss due to local variation. For many companies, centralization will work for back office functions like HR, Legal, and some aspects of Accounting.
However, in areas where the local differences are what drives effectiveness and efficiency (sales, production, customer service, or supply chain management) centralization may be too high a price to pay for lack of flexibility.
Let’s look at how Data-Centricity changes the tradeoffs.
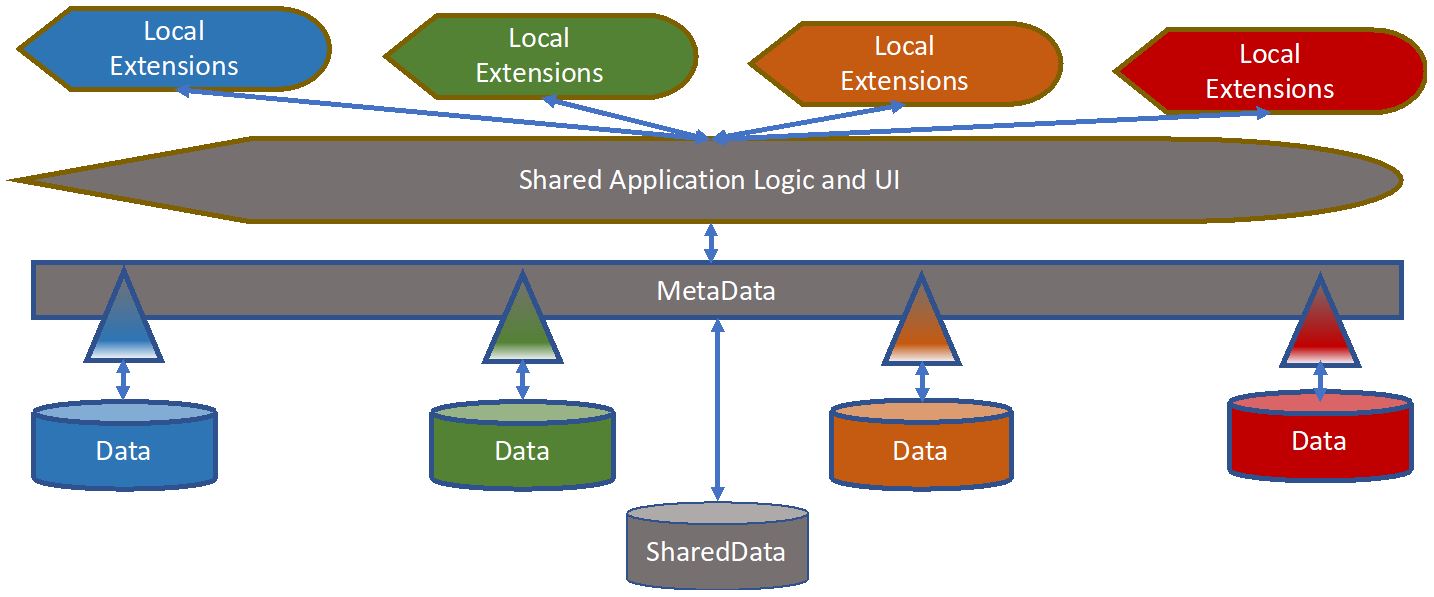
Let’s start with the metadata. With a Data-Centric approach, there is still a common, shared metadata layer. How detailed and comprehensive it is can be left as a local design decision, but we advocate having it cover all the potentially shareable concepts. The colored, inverted triangles represent points of extension and points of federation. The local datastore specializes and extends the common model (we’ll give an example below). The inverted triangle also indicates how a query expressed in the schema of the shared model, can be federated down to the local data. It is primarily a question of performance and latency: how much of the data is captured centrally in the can labeled, “SharedData,” and how much is left in the domain specific areas? The concept works even if the only shared data is the model, but it typically performs better if some of the key data (especially the less dynamic key data, such as master data and reference date) is co-located in a shared repository.
Also, it is possible to build a shared set of use cases, and then extend them for local needs, or have all the UI be local, and only share the shared data.
This example with inventory data may make it clearer.
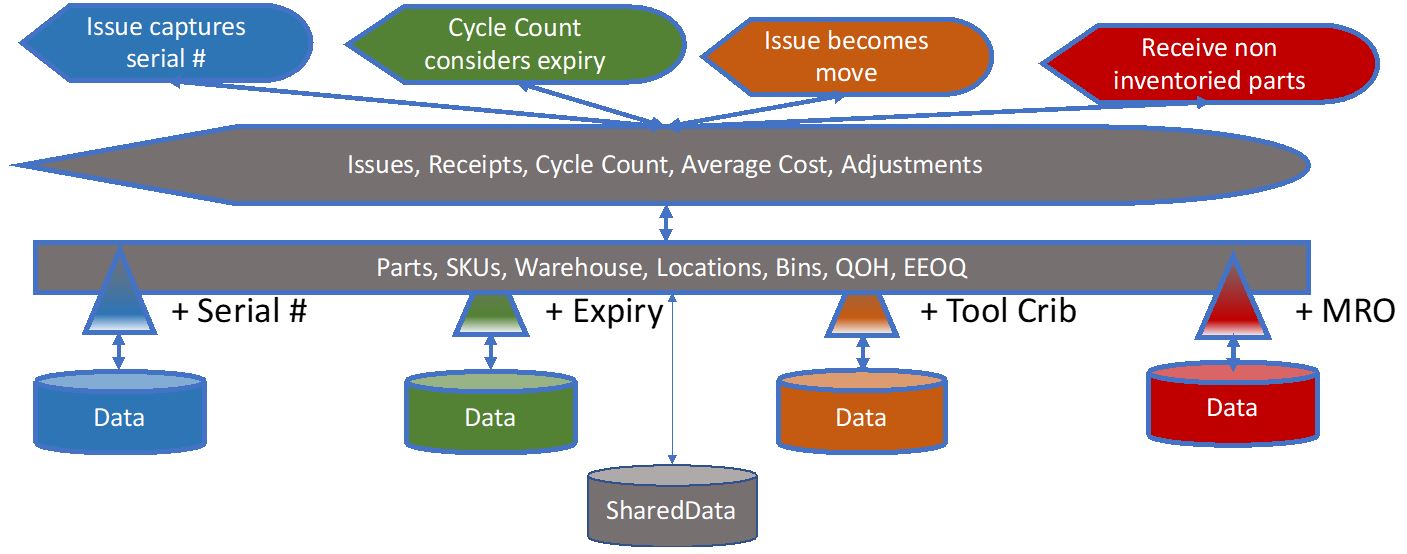
It’s not too hard to imagine a firm sharing some of the basic characteristics of inventory management. All inventory management firms have parts, stock, warehouses and bins to store them in. Every inventory system ever written calls them something different and has somehow managed to structure the data differently. However, they all share the same basic concepts, which includes parts and stock as well as quantity on-hand and, at least, the idea of an economic order quantity (even if they have different algorithms for calculating economic order quantity, they all share they concept).
And it is possible to write basic inventory functionality (e.g., issuing, receiving, and cycle counting) against the shared model.
An area where knowledge graphs make things a lot easier is when one division realizes they need some functionality and data that the other divisions don’t need. In the centralization scenario, everyone must to agree to any change that the local division puts forward, which is often expensive and time consuming.
In the Data-Centric world, let’s say one division needs to have serialized parts. There are several different sets of requirements for serialized parts in manufacturing, but let’s go with the one that only needs to record the serial number at issue time (because it becomes part of the “as-built” bill of material in the manufacturing system). In this case, we extend the schema with the concept of “serial number” and create a sub-type of inventory part for “serialized part.” We then extend (or perhaps replace, depending on the implementation technology) the issue use case. For serialized parts, we ask for the serial number at issue time.
If someone from headquarters queries for all inventory items that have certain characteristics, they would find these serialized parts (because they are specializations of the corporate “part”), even though they had no prior knowledge of “serialized parts.” In this case, because the serial number was only captured at issue time, it might not even be in that particular data store. However, we could imagine a different set of requirements where we needed to inventory by serial number, in which case we also change the receiving use case (again, only for “serialized parts”). In this scenario we would have serial numbers in the data store.
By similar logic, another division might have some perishable items and may want to have an expiry date. They don’t care about serial numbers and aren’t bothered by them. They don’t have to change their issue or receipt use cases, but they might want to change their cycle counting and/or reordering routines to take into account potential spoilage.
And so, it goes for the many variations, most of which are relatively small, and can be achieved with small extensions to the core.
By the way, this approach can also be used for the kinds of functions covered in the centralization example, but the degree of benefit isn’t as great, and therefore isn’t likely the place you would start your Data-Centric journey. (You might as well start where there is more payoff and where there aren’t already available approaches to solve the problem).
To sum up:
- Data-Centric and centralizing business systems both succeed in replacing silos.
- Centralization is mostly feasible where the strategic advance of local variation is exceeded by the value of consolidating information.
The Data-Centric approach allows us to have the best of both worlds: maximum sharing while allowing regional variation.
