
I read “How Big Things Get Done” when it first came out about six months ago.[1] I liked it then. But recently, I read another review of it, and another coin dropped. I’ll let you know what the coin was toward the end of this article, but first I need to give you my own review of this highly recommended book.
The prime author, Bent Flyvbjerg, is a professor of “Economic Geography” (whatever that is) and has a great deal of experience with engineering and architecture. Early in his career, he was puzzling over why mass transit projects seemed routinely to go wildly over budget. He examined many in great detail; some of his stories border on the comical, except for the money and disappointment that each new round brought.
He was looking for patterns, for causes. He began building a database of projects. He started with a database of 178 mass transit projects, but gradually branched out.
It turns out there wasn’t anything especially unique about mass transit projects. Lots of large projects go wildly over budget and schedule, but the question was: Why?

It’s not all doom and gloom and naysaying. He has some inspirational chapters about the construction of the Empire State Building, the Hoover Dam, and the Guggenheim Museum in Bilbao. All of these were in the rarified atmosphere of the less than ½ of 1% of projects that came in on time and on budget.
Flyvbjerg contrasted them with a friend’s brownstone renovation, California’s bullet train to nowhere, the Pentagon (it is five-sided because the originally proposed site had roads on five sides), and the Sydney Opera House. The Sydney Opera House was a disaster of such magnitude that the young architect who designed it never got another commission for the rest of his career.
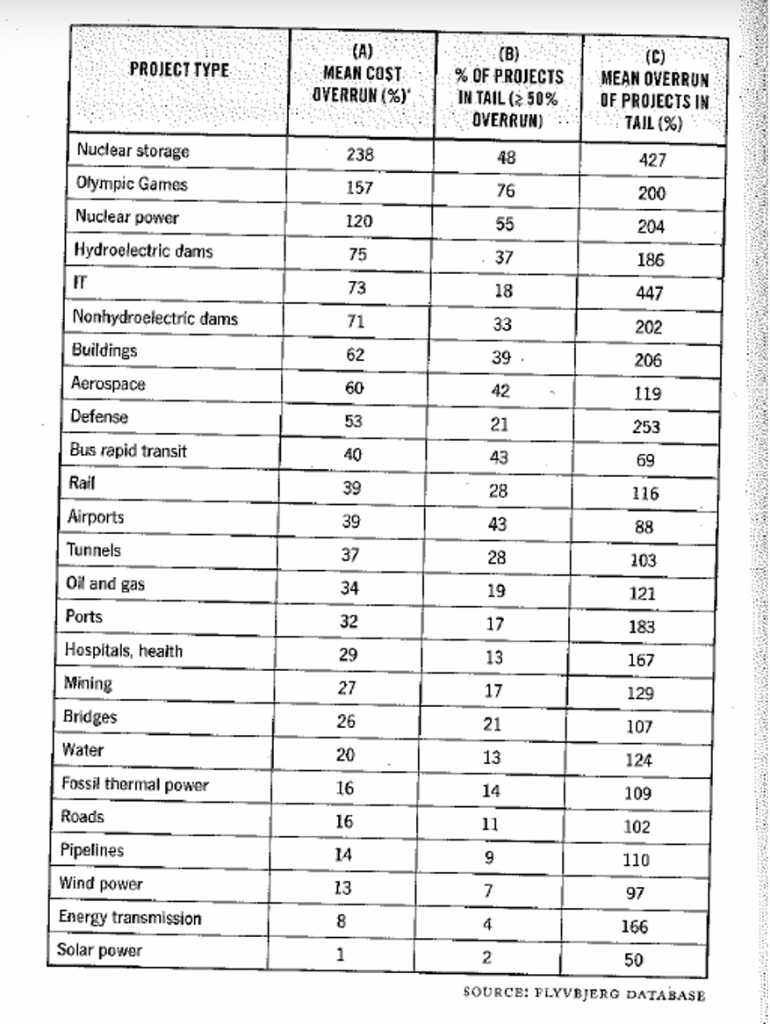
Each of the major projects in his database has key considerations, such as original budget and schedule and final cost and delivery. The database is organized by type of project (nuclear power generation versus road construction, for instance). The current version of the database has 38,000 projects. From this database, he can calculate the average amount projects run over budget by project type.
IT Projects
He eventually discovered IT projects. He finds them to be among the most likely projects to run over budget. According to his database, IT projects run over budget by an average of 73%. This database is probably skewed toward larger projects and more public ones, but this should still be of concern to anyone who sponsors IT projects.
He described some of my favorites in the book, including healthcare.gov. In general, I think he got it mostly right. Reading between the lines, though, he seems to think there is a logical minimum that the software projects should be striving for, and therefore he may be underestimating how bad things really are.
This makes sense from his engineering/architecture background. For instance, the Hoover Dam has 4.3 million cubic yards of concrete. You might imagine a design that could have removed 10 or 20% of that, but any successful dam-building project would involve nearly 4 million cubic yards of concrete. If you can figure out how much that amount of concrete costs and what it would take to get it to the site and installed, you have a pretty good idea of what the logical minimal possible cost of the dam would be.
I think he assumed that early estimates for the cost of large software projects, such as healthcare.gov at $93 million, may have been closer to the logical minimum price, which just escalated from there, to $2.1 billion.
What he didn’t realize, but readers of Software Wasteland[2] as well as users of healthsherpa.com[3] did, was that the actual cost to implement the functionality of healthcare.gov is far less than $2 million; not the $93 million originally proposed, and certainly not the $2.1 billion it eventually cost. He likely reported healthcare.gov as a 2,100% overrun (final budget of $2.1 billion / original estimate of $93 million). This is what I call the “should cost” overrun. But the “could cost” overrun was closer to 100,000% (one hundred thousand percent, which is a thousand-fold excess cost).
From his database, he finds that IT projects are in the top 20%, but not the worst if you use average overrun as your metric.
He has another metric that is also interesting called the “fat tail.” If you imagine the distribution of project overruns around a mean, there are two tails to the bell curve, one on the left (projects that overrun less than average) and one on the right for projects that overrun more than average. If overruns were normally distributed, you would expect 68% of the projects to be within one standard deviation of the mean and 94% within two standard deviations. But that’s not what you find with IT projects. Once they go over, they have a very good chance of going way over, which means the right side of the bell curve goes kind of horizontal. He calls this a “fat tail.” IT projects have the fattest tails of all the projects in his database.
IT Project Contingency
Most large projects have “contingency budgets.” That is an amount of money set aside in case something goes wrong.
If the average large IT project goes over budget by 73%, you would think that most IT project managers would use a number close to this for their contingency budget. That way, they would hit their budget-with-contingency half the time.
If you were to submit a project plan with a 70% contingency, you would be laughed out of the capital committee. They would think that you have no idea how to manage a project of this magnitude. And they would be right. So instead, you put a 15% contingency (on top of the 15% contingency your systems integrator put in there) and hope for the best. Most of the time, this turns out badly, and half the time, this turns out disastrously (in the “fat tail” where you run over by 447%). As Dave Barry always says, “I am not making this up.”
Legacy Modernization
These days, many of the large IT projects are legacy modernization projects. Legacy modernization means replacing technology that is obsolete with technology that is merely obsolescent, or soon to become so. These days, a legacy modernization project might be replacing Cobol code with Java.
It’s remarkable how many of these there are. Some come about because programming languages become obsolete (really it just becomes too hard to find programmers to work on code that is no longer padding their resumes). Far more common are vendor-forced migrations. “We will no longer support version 14.4 or earlier; clients will be required to upgrade.” What used to be an idle threat is now mandatory, as staying current is essential in order to have access to zero-day security patches.
When a vendor-forced upgrade is announced, often the client realizes this won’t be as easy as it sounds (mostly because the large number of modifications, extensions, and configurations they have made to the package over the years are going to be very hard to migrate). Besides, having been held hostage by the vendor for all this time, they are typically ready for a break. And so, they often put it out to bid, and bring in a new vendor.
What is it about these projects that are so rife? Flyvbjerg touches on it in the book. I will elaborate here.
Remember when your company implemented its first payroll system? Of course you don’t, unless you are, like, 90 years old. Trust me, everyone implemented their first automated payroll system in the 1950s and 1960s (so I’m told, I wasn’t there either). They implemented them with some of the worst technology you can imagine. Mainframe Basic Assembler Language and punched cards were state of the art on some of those early projects. These projects typically took dozens of person years (OK, back in those days they really were man years) to complete. This would be $2-5 million at today’s wages.
These days, we have modern programming languages, tools, and hardware that is literally millions of times more powerful than what was available to our ancestors. As such, a payroll system implementation in a major company is a multi-hundred million undertaking these days. “Wait, Dave, are you saying that the cost of implementing something as bog standard as a payroll system has gone up a factor of 100, while the technology used to implement it has improved massively?” Yes, that is exactly what I’m saying.
To understand how this could be you might consult this diagram.
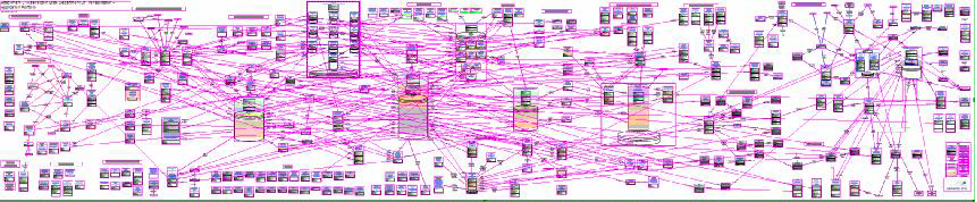
This is an actual diagram from a project with a mid-sized (7,000-person) company. Each box represents an application and each line an interface. Some are APIs, some are ETLs, and some are manual. All must be supported through any conversion.
My analogy is with heart transplantation. Any butcher worth their cleaving knife could remove one person’s heart and put in another in a few minutes. That isn’t the hard part. The hard part is keeping the patient alive through the procedure and hooking up all those arteries, veins, nerves, and whatever else needs to be restored. You don’t get to quit when you’re half done.
And so it is with legacy modernization. Think of any of those boxes in the above diagram as a critical organ. Replacing it involves reattaching all those pink lines (plus a bunch more you don’t even know are there).
DIMHRS was the infamous DoD project to upgrade their HR systems. They gave up with north of a billion dollars invested when they realized they likely only had about 20% of the interfaces completed and they weren’t even sure what the final number would be.
Back to Flyvbjerg’s Book
We can learn a lot by looking at the industries where projects run over the most and run over the least. The five types of projects that run over the most are:
- Nuclear storage
- Olympic Games
- Nuclear power
- Hydroelectric dams
- IT
To paraphrase Tolstoy, “All happy projects are alike; each unhappy project is unhappy in its own way.”
The unhappiness varies. The Olympics is mostly political. Sponsors know the project is going to run wildly over, but want to do the project anyway, so they lowball the first estimate. Once the city commits, they have little choice but to build all the stadiums and temporary guest accommodations. One thing all of these have in common is they are “all or nothing” projects. When you’ve spent half the budget on a nuclear reactor, you don’t have anything useful. When you have spent 80% of the budget and the vendor tells you you are half done, you have few choices other than to proceed. Your half a nuclear plant is likely more liability than asset.
And so it is with most IT projects. Half a legacy modernization project is nothing.
Now let’s look at the bottom of Flyvbjerg’s table:
- Roads
- Pipelines
- Wind power
- Electrical transmission
- Solar power
Roads. Really? That’s how bad the other 20 categories are.
What do these have in common? Especially wind and solar.
They are modular. Not modular as in made of parts, even nuclear power is modular in some fashion. They are modular in how their value is delivered. If you plan a wind project with 100 turbines, then when you have installed 10, you are generating 10% of the power you hoped the whole project would. You can stop at this point if you want (you probably won’t as you’re coming in on budget and getting results).
In my mind, this is one reason I think wind and solar are going to outpace most predictions of their growth. It’s not because they are green, or even that they are more economical — they are — but they are also far more predictable and lower risk. People who invest capital like that.
Data-Centric as the Modular Approach to Digital Transformation
That’s when the coin dropped.
What we have done with data-centric is create a modular way to convert an enterprise’s entire data landscape. If we pitched it as one big monolithic project, it would likely be hundreds of millions of dollars, and by the logic above, high risk and very likely to go way over budget.
But instead, we have built a methodology that allows clients to migrate toward data-centric one modest sized project at a time. At the end of each project, the client has something of value they didn’t have before, and they have convinced more people within their organization of the validity of the idea.
Briefly how this works:
- Design an enterprise ontology. This is the scaffolding that prevents subsequent projects from merely re-platforming existing silos into neo-ilos.
- Load data from several systems into a knowledge graph (KG) that conforms to the ontology in a sandbox. This is nondestructive. No production systems are touched.
- Update the load process to be live. This does introduce some redundant interfaces. It does not require any changes, but some additions to the spaghetti diagram (this is all for the long-term good).
- Grow the domain footprint. Each project can add more sources to the knowledge graph. Because of the ontology, the flexibility of the graph and the almost free integration properties of RDF technology, each domain adds more value, through integration, to the whole.
- Add capability to the KG architecture. At first, this will be view-only capability. Visualizations are a popular first capability. Natural language search is another. Eventually, firms add composable and navigable interfaces, wiki-like. Each capability is its own project and is modular and additive as described above. If any project fails, it doesn’t impact anything else.
- Add live transaction capture. This is the inflection point. Up to this point, the project was a richer and more integrated data warehouse. Up to this point, the system relied on the legacy systems for all the information, much as a data warehouse does. At this junction, you implement the ability to build use cases directly on the graph. These use cases are not bound to each other in the way that monolithic legacy system use cases are. These use cases are bound only to the ontology and therefore are extremely modular.
- Make the KG the system of record. With the use case capability in place, the graph can become the source system and system of record for some data. Any data sourced directly in the graph no longer needs to be fed from the legacy system. People can continue to update it in the legacy system if there are other legacy systems that depend on it, but over time, portions of the legacy system will atrophy.
- Legacy avoidance. We are beginning to see clients who are far enough down this path that they have broken the cycle of dependence they have been locked into for decades. The cycle is: If we have a business problem, we need to implement another application to solve it. It’s too hard to modify an existing system, so let’s build another. Once a client starts to get to critical mass in some subset of their business, they begin to become less eager to leap into another neo-legacy project.
- Legacy erosion. As the KG becomes less dependent on the legacy systems, the users can begin partitioning off parts of it and decommissioning them a bit at a time. This takes a bit of study to work through the dependencies, but is definitely worth it.
- Legacy replacement. When most of the legacy systems data is already in the graph, and many of the use cases have been built, managers can finally propose a low-risk replacement project. Those pesky interface lines are still there, but there are two strategies that can be used in parallel to deal with them. One is to start the furthest downstream, with the legacy systems that are fed, but do little feeding of others. The other strategy is to replicate the interface functionality, but from the graph.
We have done dozens of these projects. This approach works. It is modular, predictable, and low-risk.
If you want to talk to someone about getting on a path of modular modernization that really works, look us up.
[4] “How Big Things Get Done,” Bent Flyvbjerg and Dan Gardner, p. 192
