
I go to data conferences. Frequently. Almost always right here in NYC. We have lots of data conferences here. Over the years, I’ve seen a trend — more and more emphasis on AI.
I’ve taken to asking a question at these conferences: What does data quality mean for unstructured data? This is my version of The Unanswered Question.
Charles Ives (1874-1954), the great, quirky, American composer credited with foreshadowing many musical innovations widely adopted during the 20th century,1 wrote “The Unanswered Question” in 1908. It’s short — less than six minutes. You can all listen to it yourselves. Really.2 It begins with the most peaceful, untroubled music imaginable…. and then the trumpet steps in with the quiet but jarring first statement of The Question. It receives a blasé answer from the woodwinds (all flutes, or flutes, a clarinet, and/or an oboe “at the discretion of the conductor”), etc. Clearly not satisfied, the trumpet asks again… and again… the answering instruments grow more and more annoyed, until they throw their hands up in despair…. and then Ives leaves us with the strings peacefully droning on their version of Seinfeld’s “The Serenity Now.”
So, that trumpet is pretty much me at these conferences.
I know you are dying to know what is The Unanswered Question? Well, it depends. Ives wrote that the solo trumpet poses “The Perennial Question of Existence.”3 For Leonard Bernstein, in his famous Harvard lectures, titled “The Unanswered Question,”4 it was “Wither music?” Of course, Bernstein ends his epic future history of music with this statement: “I’m no longer quite sure what the question is, but I do know that the answer is ‘Yes.’”5
My unanswered question is not as profound. But it is sincere. As a data governance professional who started out in this field over a dozen years ago, I know what to do with structured data. And it all begins with CDEs — critical data elements. If you ask any data governance person what the three most important factors to improving data quality, don’t be surprised if they say “CDEs, CDEs, CDEs.” This reminds me of humorist Dave Berry’s view of real estate brokers.
“Ask any real estate broker to name the three most important factors in buying a property, and he’ll say: ‘Location, location, location.’ Now ask him to name the Chief Justice of the United States Supreme Court, and he’ll say: ‘Location, location, location.’ This tells us that we should not necessarily be paying a whole lot of attention to real estate brokers.”6
Now, I don’t want to denigrate my field, because I’m sure my colleagues in data governance would certainly not respond to just any question with “CDEs, CDEs, CDEs.” But if the topic is data quality? If I was a betting person, I’d put money on “CDEs” coming up in the conversation immediately, if not sooner.
There’s nothing wrong with focusing on CDEs. You can’t govern all data. So, you start with understanding from the stakeholders which data is most important to a process, function, or report. You then move to determining how to measure, improve, and control data quality for these data elements. Anyone who has done this knows it’s not simple. You need to analyze the data lineage. You need to find any data elements derived from other data elements. And you must deal with dueling data quality requirements from different departments for the same CDEs. Still, conceptually straightforward.
Now, at these conferences I attend, over the last two years, the refrain has adapted to the pre-eminent obsession (oh, I mean focus) on GenAI. It boils down to “GenAI is only so good as the data, and you need strong data governance and data quality to assure the data is good.”
In this light, GenAI is the best thing that’s happened to my profession since the Financial Crisis of 2008. Honestly, how often did you hear data governance before the regulators stepped up the pressure on the banks to get their data houses in order? To paraphrase that memorable catchphrase of a certain recurring character, portrayed by the original “SNL” cast member, Garrett Morris, “Regulation has been very, very good to DG.” (It is, after all, “SNL”’s 50th season, so I plan to include at least one “SNL” reference per article). Now, it’s Gen AI. And who am I to go complain about that?
But we are talking about GenAI, and at the conferences I attend, the technology most hyped — I mean discussed — is large language models (LLMs). Large language models are trained or fine-tuned, or augmented via RAG, on unstructured data. We are talking documents, e-mails, tweets, software code. What is a data element in this context, let alone a CDE? And if data quality makes all the difference to GenAI, what does data quality mean for unstructured data?
So, I ask this question to panelists and speakers. I always get a nod of acknowledgement, but then the person often steers the question to something else. That might be determining whether the LLM is spouting hallucinations. Or extracting structured data from unstructured documents for data quality testing. I don’t object to either of these topics, especially the first one, but it doesn’t get me closer to the answer to my Unanswered Question.
I’ve been doing my own research. At first, my searches for managing data quality of unstructured data didn’t yield much. Then, I realized I was asking the wrong question. When determining Critical Data Elements, you start with the needs of the data consumer. In the case of Gen AI, the direct consumer of data is the large language model itself.
So, what does data quality mean to the LLM? I got some ideas on where to begin from my conversations with data professionals. I’ve also been reading articles about data quality for natural language processing (NLP). NLP is a different technology than LLMs, but both train on unstructured data.
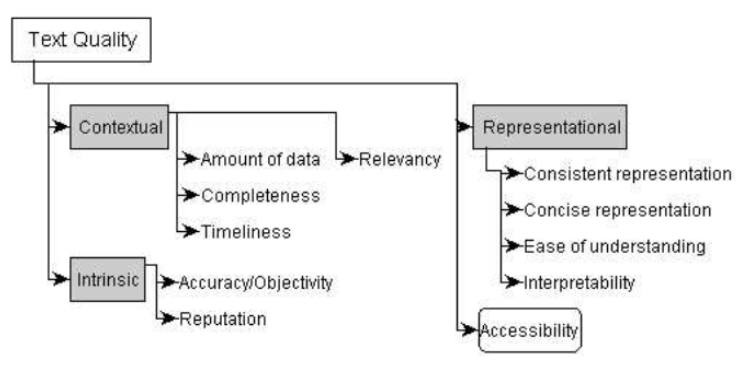
Daniel Sonntag, in his paper “Assessing the quality of natural language text data,” depicts aspects of data quality for unstructured data. He delineates four “text quality dimensions,” which recall a traditional data governance framework’s typical data quality dimensions:
Sonntag also writes about a version of the hallowed data quality concept “fit-for-purpose”:
“We begin by a clear understanding of what data quality means to data consumers. It is the concept of fitness of use that emphasizes a consumer viewpoint of quality because getting information from the data or text is ultimately the consumer interest; he judges whether the data is fit for use.”
Sonntag goes on (at some length) to define the above dimensions. I’ll use these as a basis for pulling together other observations I’ve gathered over the previous months.
Intrinsic Data Quality, as shown above, includes accuracy, objectivity, and reputation. In the context of training a large language model, this could equate to the trustworthiness of the sources of the training datasets. Take a common enterprise use case for generative AI: creating a chatbot that answers questions about corporate policies, procedures, and systems. A company trains or fine-tunes an LLM with its own library of documents. An important data quality consideration is that the training data includes the most up-to-date documents. This suggests the need for strong document management. Obsolete documents need to be retired, and document metadata needs to be maintained.
Document management takes me back … way back to the mid-1990s. I worked in the group health insurance division of The Travelers, which merged with MetLife’s group health insurance division to create MetraHealth, which United HealthCare bought… all in the space of a year! I built a document management solution to create and manage health insurance booklets, policies, and agreements. We used FrameMaker (now owned by Adobe) and Curo Document Management (no idea what happened to them). Later, at Merrill Lynch, I gathered requirements for an enterprise-wide document management system.
The project didn’t go anywhere, but it introduced me to every department at Merrill, which proved extremely useful through my 10+ years there. I also gained an appreciation of the sheer complexity of managing documents. Some industries, such as pharmaceuticals, have rigorous controls around documentation. There’s even an ISO standard for document management, ISO 19475:2021. I’m happy to accept contributions so I can buy it and write my next article about it.
But I digress. As usual.
For accessibility of text, Sonntag cites an example of “a typical quality aspect for machine consumers [the LLM in this case:] how easily a text document can be retrieved from a database (confer precision/recall)”. Data provenance may factor into whether you can use a document in the training/retraining/RAG dataset. Questions about a document’s data provenance include who created it, and what are the rights and restrictions on using it. You can find more about data provenance and AI in another column I wrote, “Through the Looking Glass: Data Provenance in the Age of Generative AI.”
Sonntag’s text data quality model includes different parameters for the contextual and representational dimensions. He notes that, in the case where the data consumer is the computer, the key is whether the text representation is suitable for automatic processing. He defines representational data quality as “aspects of data formats in form of concise and consistent representation and meaning in form of interpretability and ease of understanding. This suggests that texts are well-represented, if they are concise and consistently represented, but also interpretable and easy to understand.”
Sonntag goes on to outline a long list of text data quality issues, from “typing errors, different spellings of same words, co-reference problems, and lexical ambiguity.” He notes these are characteristics of “single-source” text data. There’s a whole host of other “multi-source problems.” One example: “In financial magazines, bank means financial institution, different from a bank in a natural park.”
So, what’s to be done here? Soulpage describes data preparation steps in its blog to address some of these problems, as part of cleaning and preprocessing data7:
- Removing noise: This involves removing text that is not relevant to the task at hand, such as headers, footers, and advertisements.
- Correcting errors: This involves correcting spelling and grammatical errors.
These actions can address those typing errors and different spellings Sonntag cites above. But then there are cases such as identifying the correct definition of bank to use in what context. This is where data labeling comes in. Data labeling is adding metadata to individual data points in a training dataset. And more often than not, humans perform this function. It’s the “secret sauce” behind Gen AI. Privacy International, in its blog “Humans in the AI loop: the data labelers behind some of the most powerful LLMs’ training datasets,” gives an example: “Data labelers mark raw datapoints (images, text, sensor data, etc.) with ‘labels’ that help the AI model make crucial decisions, such as for an autonomous vehicle to distinguish a pedestrian from a cyclist.”
Data labeling is a vast area to explore. There are human and automated solutions, and important implications to data quality as well as data bias. This deserves an article all to itself, so for now, I will finish with these two points:
- Sorry to say, but with all the aspects of text data quality we’ve covered, and the many articles and discussions I have drawn on, CDEs don’t seem to have a place in the world of unstructured data. Horrors! Readers are welcome to refute this.
- Humans don’t create documents, images, and music intending to feed LLMs! They create to communicate something… to other humans. This is why we need to think carefully about the data quality requirements of AI training data, because the data consumer is not a human — it’s a machine.
[1] Charles Ives – Wikipedia
[2] Here’s one video – there are many, and you can listen to it on Spotify too: Ives: The Unanswered Question ∙ hr-Sinfonieorchester ∙ Andrés Orozco-Estrada
[3] en.wikipedia.org/wiki/The_Unanswered_Question
[4] Bernstein, Leonard, The Unanswered Question, Six Talks at Harvard, 1976, Harvard University Press, Cambridge, Massachusetts and London, England.
[5] Bernstein, Ibid, pg. 425
[6] Dave Barry, Homes and Other Black Holes (ed. Ballantine Books, 2010) – ISBN: 9780307758828
[7] soulpageit.com/how-to-train-your-own-language-model-a-step-by-step-guide/
