 In today’s world, corporations everywhere have call centers. It is through the call center that the corporation can communicate directly with the customer and/or the prospect. Call centers have become one of the most important marketing and sales arms of the corporation.
In today’s world, corporations everywhere have call centers. It is through the call center that the corporation can communicate directly with the customer and/or the prospect. Call centers have become one of the most important marketing and sales arms of the corporation.
As ubiquitous and as important as the call center is, in most organizations the call center is a mystery when it comes to being able to hear what the customer says. Certainly, the customer can talk with a representative of the corporation.
And call center representatives are trained in the manner in which the conversation needs to be conducted. But once the conversation occurs between the representative and the customer, no further information is gleaned from the conversation.
And that’s a shame. Because there is a wealth of information that is locked in the interchange between the corporate representative and the customer.
Ask any executive whether they know what is going on in their call center. The executive will assure you that he/she knows what is going on. (Note: Executives are trained to always proclaim that they know what is going on!)
When you ask the executive to further elucidate, the conversation goes something like this – “we do 7,500 calls a day. And the calls average 4 ½ minutes.”
Then you ask the executive – “Well that is interesting. That is one way to look at your call center. But can you tell me what the customer is saying? What they are asking for? What they are complaining about? Do they want to buy something else?”
Then the executive explains that you can’t know that sort of thing.
The very heart of what the customer is saying is NOT being accessed and understood by the executive of the corporation.
The problem is that there is MASSIVE opportunity that is being lost by not understanding what the customer is saying. MASSIVE OPPORTUNITY!!!
Instead, the corporation merely discards the call center conversations with a customer into the trash heap. One of the most meaningful opportunities the corporation has is now gone and will never return.
In today’s world it is not necessary to lose this massive opportunity. Once upon a time, technology was so expensive and so crude that trying to do much with call center information was merely a pipe dream. But the cost of technology has dropped and the sophistication of technology is such that in today’s world, an organization can really hear what is being said in the call center.
And that opens up whole new worlds of opportunity.
OPENING UP THE CALL CENTER
The general plan for opening up the call center is shown by the following schematic.
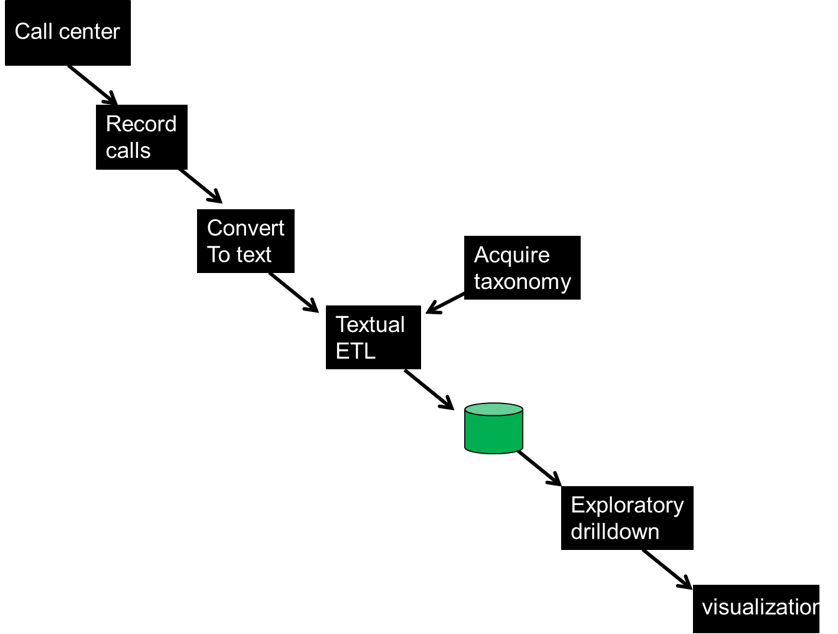
The first step of course is to have a call center. The calls in the call center are recorded. The recorded calls are gathered and are converted to text. Once in the form of electronic text the calls are passed through textual ETL. Input into textual ETL comes from the calls and from a taxonomy. The taxonomy is specific to the business that has the call center.
From textual ETL, the text, and the taxonomy, a standard data base is produced.
After the data base is produced, exploratory drill down process can occur. And after the organization has a firm understanding of what is needed, visualization can be created and run on an ongoing basis.
The plan that was mentioned previously outlines how an organization can go from call center conversations to an analysis of what the customer has been saying. The result is MASSIVE OPPORTUNITY.
It is noteworthy that the customer has a collective voice that is being heard. One of the advantages of this plan is that ALL the customers who participate in the call center have their conversations heard.
Another advantage is that once automated, the process occurs quickly. The conversation with the customer can occur at 10:00 am in the morning and the analysis of the conversation can be made at 2:00 pm in the afternoon. In other words, once automated, the plan can be executed in a very short amount of time.
One of the features of the plan is that there is feedback and iterative processing throughout it. If at any point it is necessary to recast the analysis, the analysis can be redrawn and iterative processing can occur. The fact that iterative processing can be done throughout is one of the inherent strengths of the plan. Because iterative processing is viable, the ability of the organization to be responsive to changing conditions is accounted for. In other words, the plan that has been described is adaptable to changing conditions.
THE CALL CENTER
The call center is the place where corporate representatives converse with customers and prospects. The number of call center representatives is commensurate with the number of calls incoming. These representatives are trained in the type of conversation to be held and in the handling of difficult calls and difficult people.
It helps if the date and time of the recording is captured along with the recording itself. It may also be useful to record the location where the recording is made and the identification of the corporate representative as well.
For there to be an analysis of the collective activity in the call center, the calls need to be recorded. A typical medium for the calls to be recorded in is .wav technology, which is a simple technology that merely records the conversation.
CONVERTING .wav TECHNOLOGY
The telephone conversations are recorded in a .wav format. The next step is to use the .wav recordings as input into conversion technology. The conversion of the conversation is a critical juncture. If the conversion is not made accurately the remainder of processing will be negatively affected. The problem is that under the best of circumstances, the conversion to a .txt format will not be done perfectly.
The conversion technology can be “trained” to improve the accuracy of the conversion. But even when the conversion technology is trained, there will still be inaccuracies in the conversion to text. Inaccuracies are simply a fact of life.
The conversion to text should be done with the expectation that the conversion will at least be done adequately, if not done perfectly.
In any case .wav voice transcriptions are converted into an electronic text format, such as .txt.

TEXTUAL ETL
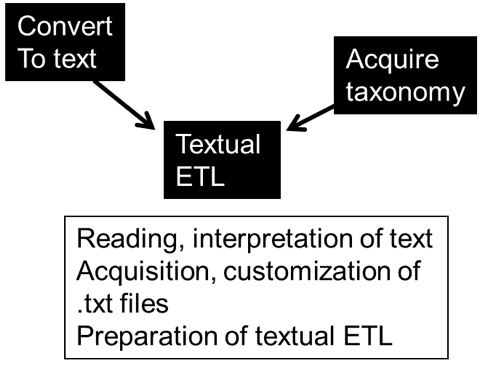
Once the voice recordings are converted into an electronic text format, the text can be processed by textual ETL. Textual ETL uses two basic forms of input to do its processing – electronic text and taxonomies. The taxonomies are classifications of data that are relevant to and customized to the business of the corporation. There are almost always multiple taxonomies that are used because most businesses are multi-faceted. There will usually be one (or more) taxonomy for each facet of the customer-centric business. All of the taxonomies will be used for input into textual ETL.
The processing of voice recordings is only one of many things that textual ETL is capable of doing. The consequence is that a certain amount of preparation of textual ETL needs to be done before processing. The format of the input data, the editing rules, the specific taxonomies that will be used, and the selection of algorithms are just some of the preparation of textual ETL that must be done in order to process call center input.
The text is read, analyzed, and placed into a data base. There are many important elements that are captured by textual ETL. But the two most important elements are the text itself and its context. Both of these elements are vital to the understanding and interpretation of the text. Other elements that are captured are the identification of the recording and the byte address of the text within the recording. Other incidental information may include any editing done to the text, assumptions made by the taxonomy, identification of which taxonomy was used in the interpretation, and so forth.
The output of textual ETL is a simple data base. It is important that a simple data base be produced because other software that will use the output operates best on simple data bases. Stated differently, the more complex a data base is, the less useful it will be for further processing. Therefore, the output from textual ETL needs to be as simple as possible.
THE DATA BASE
The data base produced by textual ETL is a simple data base. It can be in any number of technologies, such as Oracle, SQL Server, Hadoop, DB2, Teradata, and others. The volume of data that can be handled is limited only by the dbms technology itself.
There is nothing different or special about the dbms or the data bases that are created other than the fact that there is only a single data base design for all call center conversations. Traditionally, data base designers have created different data base designs for different business purposes. In doing so, data base designers customize their design. But data base design coming from textual ETL is unique in that there is only one generic design. The different variations in business circumstances are buried within the single design itself.
The result is that analytical software that operates on textual ETL output does not have to worry about a plethora of different data base designs emanating from textual ETL.

DRILLDOWN PROCESSING
Once the output data bases are created, the usual first step is to do interactive drilldown processing against the data. Drilldown processing in many ways is a first peek at what is going on in the call center. Drilldown processing is usually interactive and is done heuristically. Drilldown processing is done quickly and spontaneously. In this type of processing, the analyst can look at one thing then change his/her mind and look at something else on an immediate, instantaneous basis.
The best way to describe drilldown processing is that it is an exploratory exercise. The analyst looks at one thing and may never again look at the same thing. Drilldown processing is the epitome of ad hoc, heuristic processing. The analyst uses it in order to determine what needs to be looked at on a regular basis.
There are two basic forms of drilldown processing – taxonomy based drilldown and raw data drilldown. Both forms of drilldown have the same objective – to find out what data is in the text. Taxonomy-based drill down uses taxonomies to navigate the output. Raw data drilldown simply looks at the raw data. The difference is the efficiency with which the processes operate. As a rule, taxonomy based drilldown operates much more quickly than raw data drilldown. When there is a lot of data it is much more efficient to use taxonomy-based drilldown.
The only limitation of taxonomy based drilldown is that taxonomy-based drilldown depends on predefined taxonomies. On occasion the analyst will want to do a search based on words that are not found in any taxonomy. When that is the case the search is done against raw data. When there is a lot of raw data, such searches can take a long time.
TYPICAL DRILLDOWNS
Typical drilldown searches of call center data are on politeness. Has the call center conversation included polite language? Conversely, has the call center conversation consisted of impolite language? Whatever else a call center conversation is, it is (or at least should be) polite. Impolite call center interchanges are not appropriate.
A second typical drilldown analysis is about legality. Has the conversation had any mentions of a lawsuit or attorneys? Call center interchanges about this subject are always a concern.
A third category of analysis concerns “red flag” subjects. Red flag subjects can include many things. Typically, red flag subjects include emergencies, injuries, payments, deadlines, trouble, disputes, alarms, frights, insults, milestones, and so forth. Whenever there is a mention of a red flag subject the call center analyst wants to know.
While these subjects are always important, perhaps the biggest value of call center conversation analysis is that of looking for future business opportunity. Business opportunity comes in many different forms. Opportunity arises in terms of new products for sale, changes to existing products, recognizing demand for products that don’t yet exist, and so on.
Unlike other words in a conversation that are predictable, the analysis of conversations seeking new opportunity is very unpredictable. This is where drilldown on taxonomies becomes less useful and drilldown on raw data becomes more useful. Drilldown on raw data can use any word for analysis. The only price of drilldown on random words is the length of time required to analyze large amounts of raw data.
Sentiment analysis can be done on call center conversations. However, much of call center conversations do not express sentiment. Most call center calls are of an informational variety. And the inaccuracy of .wav to .txt conversion often makes sentiment analysis very hard to do. However, it is possible to do at least a limited form of sentiment analysis on call center conversations when applicable.
Drilldown analysis is the first step in taking a more systematic and a more formalized approach to analytical processing of call center conversations. The primary purpose of drilldown processing is to allow the analyst to understand what data needs to be regularly examined.

A TYPICAL SET OF TAXONOMIES
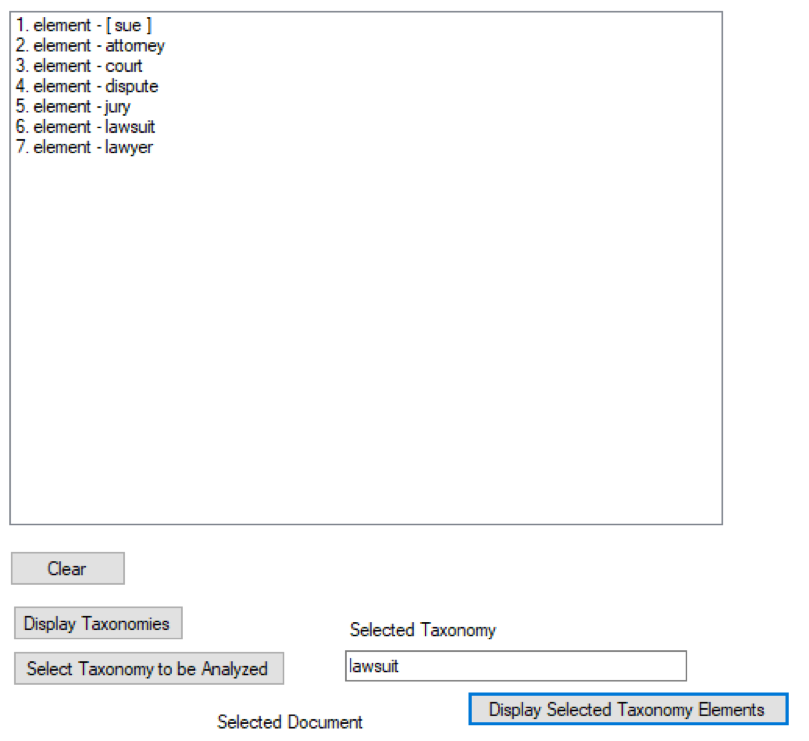
A typical taxonomy is shown. Looking at the taxonomies that have been used is usually a good first step in drilldown analysis.
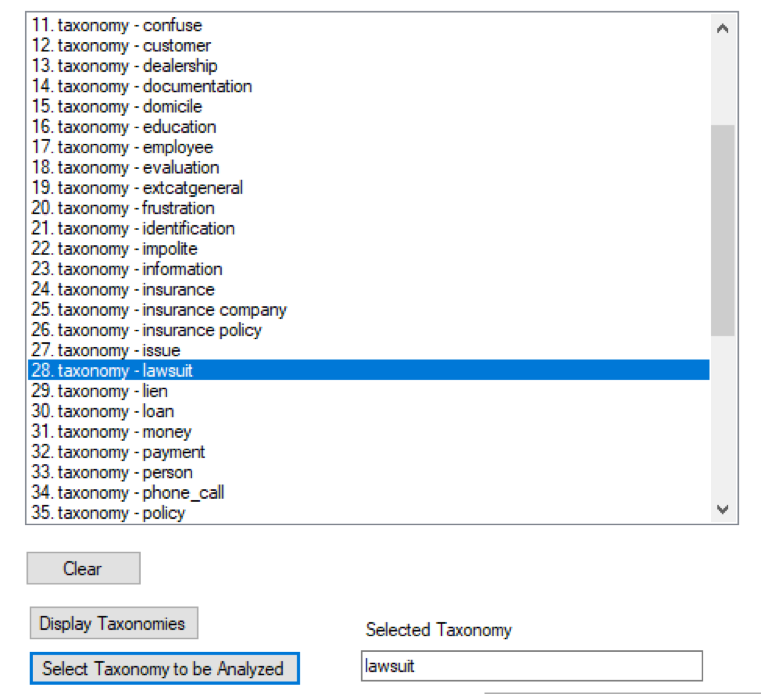
In this case the analyst is interested in looking at any mention of a lawsuit aising in a call center conversation.
It is natural to want to know what the taxonomy consists of. The actual elements of a lawsuit taxonomy include:
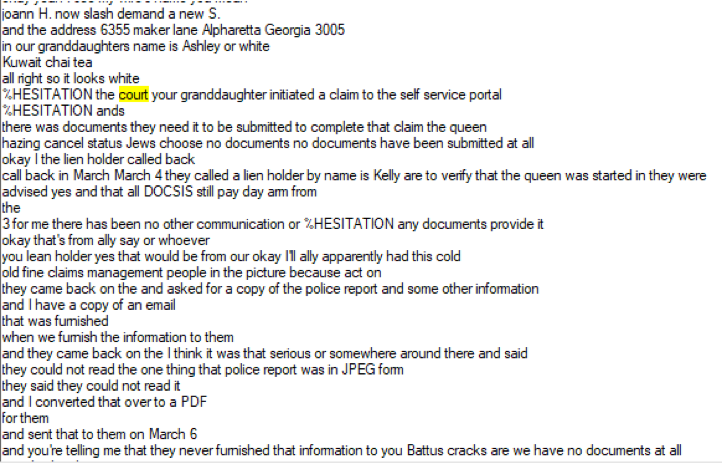
After the lawsuit taxonomy has been selected, the documents that contain a mention of a lawsuit are located. A document is selected and is then displayed. As part of the display, the word(s) that caused the document to be selected are highlighted.
In such a manner the analyst can quickly determine what the call center conversation was about.
A RAW TEXT DRILLDOWN
A raw text search starts with the identification of what words are needed for analysis.
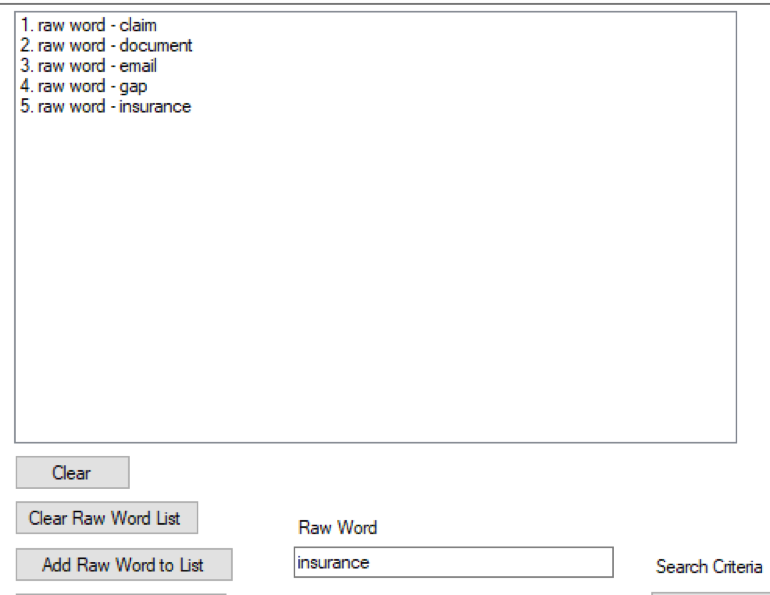
In this case, the analyst has selected to search for the words claim, document, email, gap, and insurance.
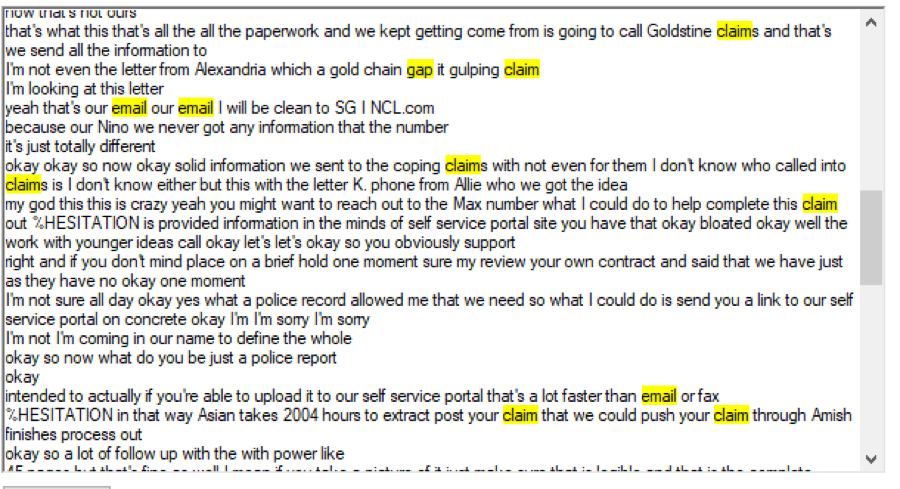
The search is done on all documents, and the documents that are qualified are identified. One of the documents is selected and displayed.
VISUALIZING A REPETITIVE ANALYSIS
After the analyst understands the data that is found in the call center cnversations, the analyst may choose to have the data analyzed on a regular basis. This is usually done with a tool made for visualization.

The visualization tool produces a graphical representation of the data.
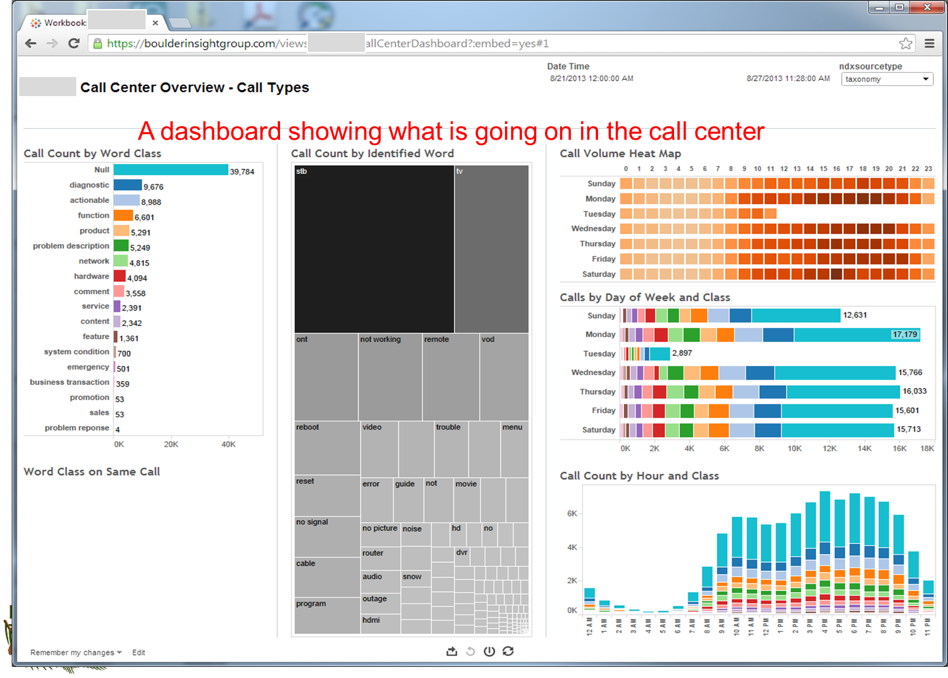
There are many important pieces of information that are shown in the visualization. Some of the important features of the visualization include –
- A general characterization of the conversation
- A 24-hour demographic analysis of when the calls arrive in the call center
- A weekly analysis of the arrival of the phone calls
- A monthly analysis of the arrival of the phone calls
- A drill down display of the subject discussed in the conversations
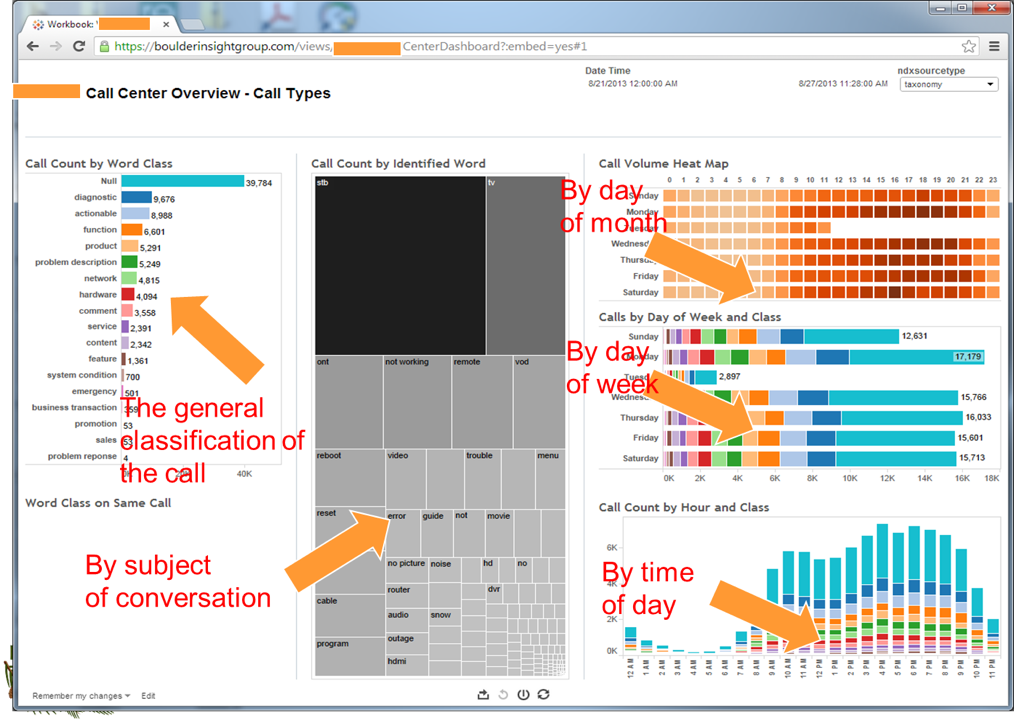
Now, with the plan and the tools that have been described you can understand at both a detailed level and a summary level what is going on in your call center.
